 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Emotion to Expression: Theoretical Foundations and Resources for Fear Speech
Jan 23, 2026Few forces rival fear in their ability to mobilize societies, distort communication, and reshape collective behavior. In computational linguistics, fear is primarily studied as an emotion, but not as a distinct form of speech. Fear speech content is widespread and growing, and often outperforms hate-speech content in reach and engagement because it appears "civiler" and evades moderation. Yet the computational study of fear speech remains fragmented and under-resourced. This can be understood by recognizing that fear speech is a phenomenon shaped by contributions from multiple disciplines. In this paper, we bridge cross-disciplinary perspectives by comparing theories of fear from Psychology, Political science, Communication science, and Linguistics. Building on this, we review existing definitions. We follow up with a survey of datasets from related research areas and propose a taxonomy that consolidates different dimensions of fear for studying fear speech. By reviewing current datasets and defining core concepts, our work offers both theoretical and practical guidance for creating datasets and advancing fear speech research.
ProvocationProbe: Instigating Hate Speech Dataset from Twitter
Oct 25, 2024In the recent years online social media platforms has been flooded with hateful remarks such as racism, sexism, homophobia etc. As a result, there have been many measures taken by various social media platforms to mitigate the spread of hate-speech over the internet. One particular concept within the domain of hate speech is instigating hate, which involves provoking hatred against a particular community, race, colour, gender, religion or ethnicity. In this work, we introduce \textit{ProvocationProbe} - a dataset designed to explore what distinguishes instigating hate speech from general hate speech. For this study, we collected around twenty thousand tweets from Twitter, encompassing a total of nine global controversies. These controversies span various themes including racism, politics, and religion. In this paper, i) we present an annotated dataset after comprehensive examination of all the controversies, ii) we also highlight the difference between hate speech and instigating hate speech by identifying distinguishing features, such as targeted identity attacks and reasons for hate.
Analyzing Toxicity in Deep Conversations: A Reddit Case Study
Apr 11, 2024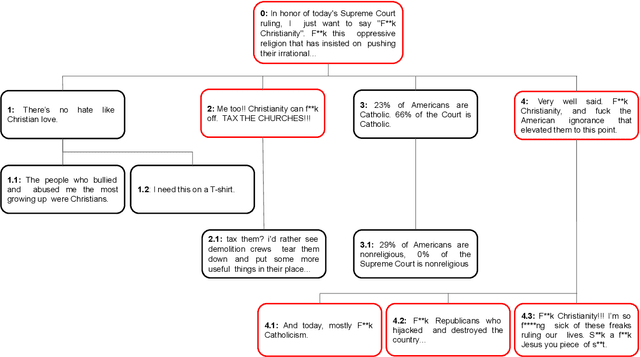
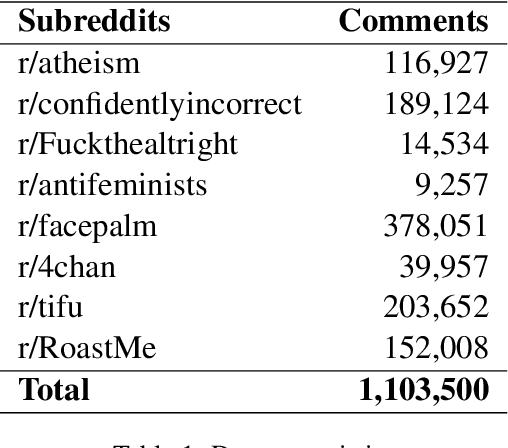
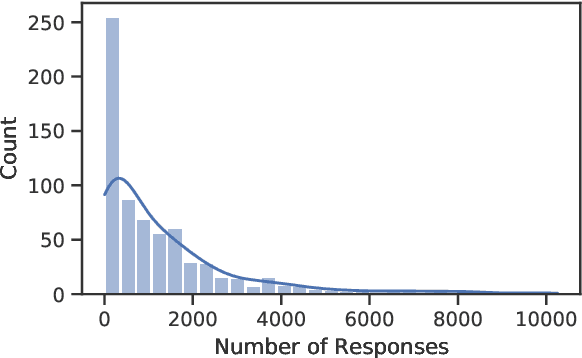
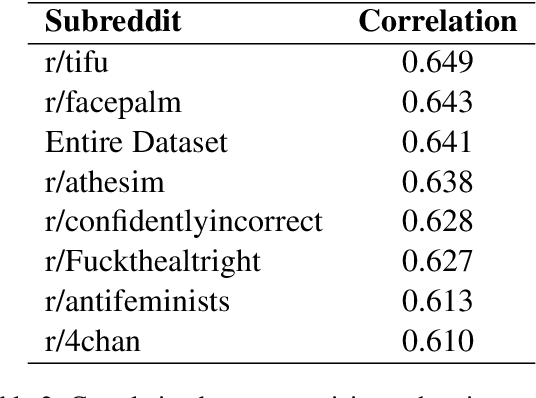
Online social media has become increasingly popular in recent years due to its ease of access and ability to connect with others. One of social media's main draws is its anonymity, allowing users to share their thoughts and opinions without fear of judgment or retribution. This anonymity has also made social media prone to harmful content, which requires moderation to ensure responsible and productive use. Several methods using artificial intelligence have been employed to detect harmful content. However, conversation and contextual analysis of hate speech are still understudied. Most promising works only analyze a single text at a time rather than the conversation supporting it. In this work, we employ a tree-based approach to understand how users behave concerning toxicity in public conversation settings. To this end, we collect both the posts and the comment sections of the top 100 posts from 8 Reddit communities that allow profanity, totaling over 1 million responses. We find that toxic comments increase the likelihood of subsequent toxic comments being produced in online conversations. Our analysis also shows that immediate context plays a vital role in shaping a response rather than the original post. We also study the effect of consensual profanity and observe overlapping similarities with non-consensual profanity in terms of user behavior and patterns.
Revisiting The Classics: A Study on Identifying and Rectifying Gender Stereotypes in Rhymes and Poems
Mar 25, 2024



Rhymes and poems are a powerful medium for transmitting cultural norms and societal roles. However, the pervasive existence of gender stereotypes in these works perpetuates biased perceptions and limits the scope of individuals' identities. Past works have shown that stereotyping and prejudice emerge in early childhood, and developmental research on causal mechanisms is critical for understanding and controlling stereotyping and prejudice. This work contributes by gathering a dataset of rhymes and poems to identify gender stereotypes and propose a model with 97% accuracy to identify gender bias. Gender stereotypes were rectified using a Large Language Model (LLM) and its effectiveness was evaluated in a comparative survey against human educator rectifications. To summarize, this work highlights the pervasive nature of gender stereotypes in literary works and reveals the potential of LLMs to rectify gender stereotypes. This study raises awareness and promotes inclusivity within artistic expressions, making a significant contribution to the discourse on gender equality.
Misinformation Concierge: A Proof-of-Concept with Curated Twitter Dataset on COVID-19 Vaccination
Aug 25, 2023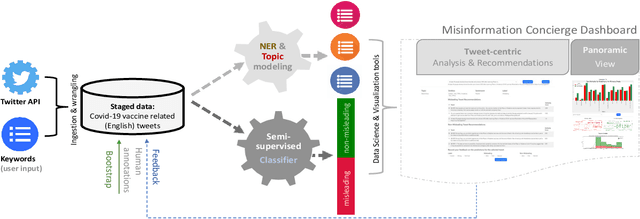
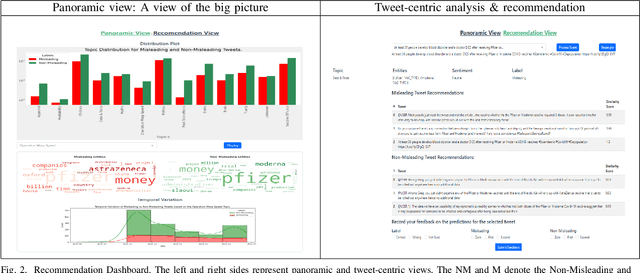
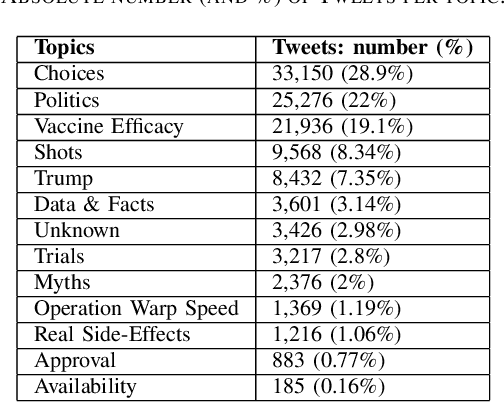
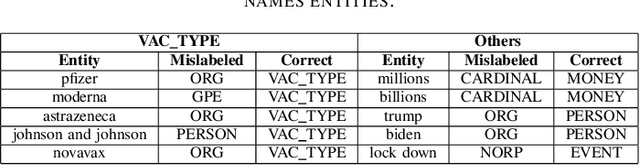
We demonstrate the Misinformation Concierge, a proof-of-concept that provides actionable intelligence on misinformation prevalent in social media. Specifically, it uses language processing and machine learning tools to identify subtopics of discourse and discern non/misleading posts; presents statistical reports for policy-makers to understand the big picture of prevalent misinformation in a timely manner; and recommends rebuttal messages for specific pieces of misinformation, identified from within the corpus of data - providing means to intervene and counter misinformation promptly. The Misinformation Concierge proof-of-concept using a curated dataset is accessible at: https://demo-frontend-uy34.onrender.com/
Multi-site Diagnostic Classification Of Schizophrenia Using 3D CNN On Aggregated Task-based fMRI Data
Oct 11, 2022
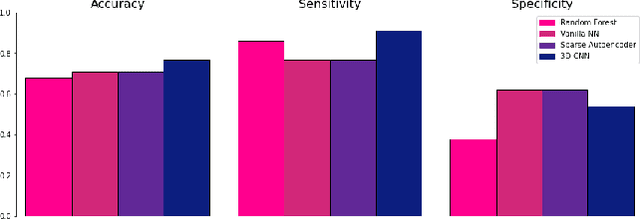
In spite of years of research, the mechanisms that underlie the development of schizophrenia, as well as its relapse, symptomatology, and treatment, continue to be a mystery. The absence of appropriate analytic tools to deal with the variable and complicated nature of schizophrenia may be one of the factors that contribute to the development of this disorder. Deep learning is a subfield of artificial intelligence that was inspired by the nervous system. In recent years, deep learning has made it easier to model and analyse complicated, high-dimensional, and nonlinear systems. Research on schizophrenia is one of the many areas of study that has been revolutionised as a result of the outstanding accuracy that deep learning algorithms have demonstrated in classification and prediction tasks. Deep learning has the potential to become a powerful tool for understanding the mechanisms that are at the root of schizophrenia. In addition, a growing variety of techniques aimed at improving model interpretability and causal reasoning are contributing to this trend. Using multi-site fMRI data and a variety of deep learning approaches, this study seeks to identify different types of schizophrenia. Our proposed method of temporal aggregation of the 4D fMRI data outperforms existing work. In addition, this study aims to shed light on the strength of connections between various brain areas in schizophrenia individuals.