 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Confidence Trap: Gender Bias and Predictive Certainty in LLMs
Jan 12, 2026The increased use of Large Language Models (LLMs) in sensitive domains leads to growing interest in how their confidence scores correspond to fairness and bias. This study examines the alignment between LLM-predicted confidence and human-annotated bias judgments. Focusing on gender bias, the research investigates probability confidence calibration in contexts involving gendered pronoun resolution. The goal is to evaluate if calibration metrics based on predicted confidence scores effectively capture fairness-related disparities in LLMs. The results show that, among the six state-of-the-art models, Gemma-2 demonstrates the worst calibration according to the gender bias benchmark. The primary contribution of this work is a fairness-aware evaluation of LLMs' confidence calibration, offering guidance for ethical deployment. In addition, we introduce a new calibration metric, Gender-ECE, designed to measure gender disparities in resolution tasks.
Towards Neural Audio Codec Source Parsing
Jun 14, 2025


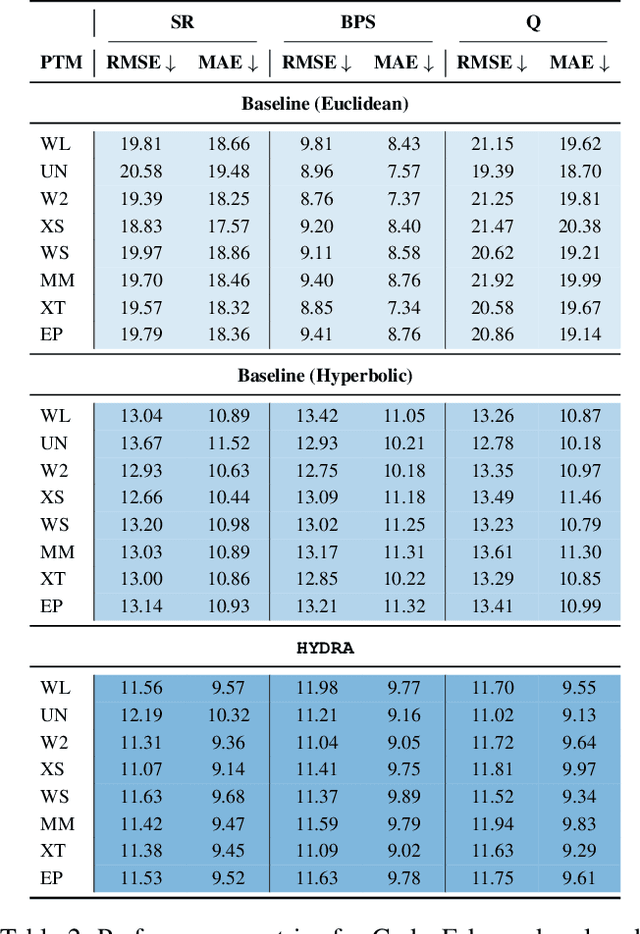
A new class of audio deepfakes-codecfakes (CFs)-has recently caught attention, synthesized by Audio Language Models that leverage neural audio codecs (NACs) in the backend. In response, the community has introduced dedicated benchmarks and tailored detection strategies. As the field advances, efforts have moved beyond binary detection toward source attribution, including open-set attribution, which aims to identify the NAC responsible for generation and flag novel, unseen ones during inference. This shift toward source attribution improves forensic interpretability and accountability. However, open-set attribution remains fundamentally limited: while it can detect that a NAC is unfamiliar, it cannot characterize or identify individual unseen codecs. It treats such inputs as generic ``unknowns'', lacking insight into their internal configuration. This leads to major shortcomings: limited generalization to new NACs and inability to resolve fine-grained variations within NAC families. To address these gaps, we propose Neural Audio Codec Source Parsing (NACSP) - a paradigm shift that reframes source attribution for CFs as structured regression over generative NAC parameters such as quantizers, bandwidth, and sampling rate. We formulate NACSP as a multi-task regression task for predicting these NAC parameters and establish the first comprehensive benchmark using various state-of-the-art speech pre-trained models (PTMs). To this end, we propose HYDRA, a novel framework that leverages hyperbolic geometry to disentangle complex latent properties from PTM representations. By employing task-specific attention over multiple curvature-aware hyperbolic subspaces, HYDRA enables superior multi-task generalization. Our extensive experiments show HYDRA achieves top results on benchmark CFs datasets compared to baselines operating in Euclidean space.
Investigating Prosodic Signatures via Speech Pre-Trained Models for Audio Deepfake Source Attribution
Dec 23, 2024



In this work, we investigate various state-of-the-art (SOTA) speech pre-trained models (PTMs) for their capability to capture prosodic signatures of the generative sources for audio deepfake source attribution (ADSD). These prosodic characteristics can be considered one of major signatures for ADSD, which is unique to each source. So better is the PTM at capturing prosodic signs better the ADSD performance. We consider various SOTA PTMs that have shown top performance in different prosodic tasks for our experiments on benchmark datasets, ASVSpoof 2019 and CFAD. x-vector (speaker recognition PTM) attains the highest performance in comparison to all the PTMs considered despite consisting lowest model parameters. This higher performance can be due to its speaker recognition pre-training that enables it for capturing unique prosodic characteristics of the sources in a better way. Further, motivated from tasks such as audio deepfake detection and speech recognition, where fusion of PTMs representations lead to improved performance, we explore the same and propose FINDER for effective fusion of such representations. With fusion of Whisper and x-vector representations through FINDER, we achieved the topmost performance in comparison to all the individual PTMs as well as baseline fusion techniques and attaining SOTA performance.
ProvocationProbe: Instigating Hate Speech Dataset from Twitter
Oct 25, 2024In the recent years online social media platforms has been flooded with hateful remarks such as racism, sexism, homophobia etc. As a result, there have been many measures taken by various social media platforms to mitigate the spread of hate-speech over the internet. One particular concept within the domain of hate speech is instigating hate, which involves provoking hatred against a particular community, race, colour, gender, religion or ethnicity. In this work, we introduce \textit{ProvocationProbe} - a dataset designed to explore what distinguishes instigating hate speech from general hate speech. For this study, we collected around twenty thousand tweets from Twitter, encompassing a total of nine global controversies. These controversies span various themes including racism, politics, and religion. In this paper, i) we present an annotated dataset after comprehensive examination of all the controversies, ii) we also highlight the difference between hate speech and instigating hate speech by identifying distinguishing features, such as targeted identity attacks and reasons for hate.
SeQuiFi: Mitigating Catastrophic Forgetting in Speech Emotion Recognition with Sequential Class-Finetuning
Oct 16, 2024

In this work, we introduce SeQuiFi, a novel approach for mitigating catastrophic forgetting (CF) in speech emotion recognition (SER). SeQuiFi adopts a sequential class-finetuning strategy, where the model is fine-tuned incrementally on one emotion class at a time, preserving and enhancing retention for each class. While various state-of-the-art (SOTA) methods, such as regularization-based, memory-based, and weight-averaging techniques, have been proposed to address CF, it still remains a challenge, particularly with diverse and multilingual datasets. Through extensive experiments, we demonstrate that SeQuiFi significantly outperforms both vanilla fine-tuning and SOTA continual learning techniques in terms of accuracy and F1 scores on multiple benchmark SER datasets, including CREMA-D, RAVDESS, Emo-DB, MESD, and SHEMO, covering different languages.
Beyond Speech and More: Investigating the Emergent Ability of Speech Foundation Models for Classifying Physiological Time-Series Signals
Oct 16, 2024



Despite being trained exclusively on speech data, speech foundation models (SFMs) like Whisper have shown impressive performance in non-speech tasks such as audio classification. This is partly because speech shares some common traits with audio, enabling SFMs to transfer effectively. In this study, we push the boundaries by evaluating SFMs on a more challenging out-of-domain (OOD) task: classifying physiological time-series signals. We test two key hypotheses: first, that SFMs can generalize to physiological signals by capturing shared temporal patterns; second, that multilingual SFMs will outperform others due to their exposure to greater variability during pre-training, leading to more robust, generalized representations. Our experiments, conducted for stress recognition using ECG (Electrocardiogram), EMG (Electromyography), and EDA (Electrodermal Activity) signals, reveal that models trained on SFM-derived representations outperform those trained on raw physiological signals. Among all models, multilingual SFMs achieve the highest accuracy, supporting our hypothesis and demonstrating their OOD capabilities. This work positions SFMs as promising tools for new uncharted domains beyond speech.
Multi-View Multi-Task Modeling with Speech Foundation Models for Speech Forensic Tasks
Oct 16, 2024



Speech forensic tasks (SFTs), such as automatic speaker recognition (ASR), speech emotion recognition (SER), gender recognition (GR), and age estimation (AE), find use in different security and biometric applications. Previous works have applied various techniques, with recent studies focusing on applying speech foundation models (SFMs) for improved performance. However, most prior efforts have centered on building individual models for each task separately, despite the inherent similarities among these tasks. This isolated approach results in higher computational resource requirements, increased costs, time consumption, and maintenance challenges. In this study, we address these challenges by employing a multi-task learning strategy. Firstly, we explore the various state-of-the-art (SOTA) SFMs by extracting their representations for learning these SFTs and investigating their effectiveness at each task specifically. Secondly, we analyze the performance of the extracted representations on the SFTs in a multi-task learning framework. We observe a decline in performance when SFTs are modeled together compared to individual task-specific models, and as a remedy, we propose multi-view learning (MVL). Views are representations from different SFMs transformed into distinct abstract spaces by characteristics unique to each SFM. By leveraging MVL, we integrate these diverse representations to capture complementary information across tasks, enhancing the shared learning process. We introduce a new framework called TANGO (Task Alignment with iNter-view Gated Optimal transport) to implement this approach. With TANGO, we achieve the topmost performance in comparison to individual SFM representations as well as baseline fusion techniques across benchmark datasets such as CREMA-D, emo-DB, and BAVED.
Representation Loss Minimization with Randomized Selection Strategy for Efficient Environmental Fake Audio Detection
Sep 24, 2024



The adaptation of foundation models has significantly advanced environmental audio deepfake detection (EADD), a rapidly growing area of research. These models are typically fine-tuned or utilized in their frozen states for downstream tasks. However, the dimensionality of their representations can substantially lead to a high parameter count of downstream models, leading to higher computational demands. So, a general way is to compress these representations by leveraging state-of-the-art (SOTA) unsupervised dimensionality reduction techniques (PCA, SVD, KPCA, GRP) for efficient EADD. However, with the application of such techniques, we observe a drop in performance. So in this paper, we show that representation vectors contain redundant information, and randomly selecting 40-50% of representation values and building downstream models on it preserves or sometimes even improves performance. We show that such random selection preserves more performance than the SOTA dimensionality reduction techniques while reducing model parameters and inference time by almost over half.
Avengers Assemble: Amalgamation of Non-Semantic Features for Depression Detection
Sep 22, 2024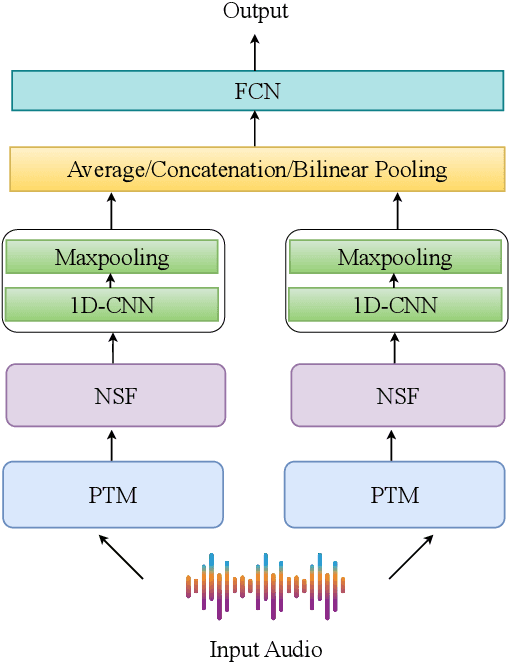
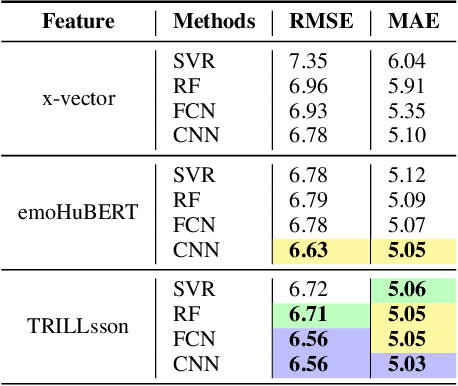
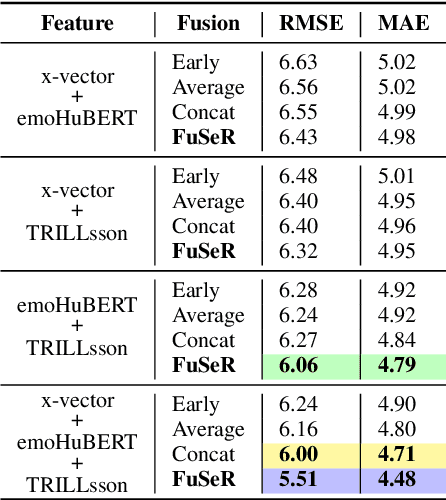
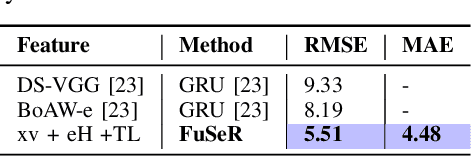
In this study, we address the challenge of depression detection from speech, focusing on the potential of non-semantic features (NSFs) to capture subtle markers of depression. While prior research has leveraged various features for this task, NSFs-extracted from pre-trained models (PTMs) designed for non-semantic tasks such as paralinguistic speech processing (TRILLsson), speaker recognition (x-vector), and emotion recognition (emoHuBERT)-have shown significant promise. However, the potential of combining these diverse features has not been fully explored. In this work, we demonstrate that the amalgamation of NSFs results in complementary behavior, leading to enhanced depression detection performance. Furthermore, to our end, we introduce a simple novel framework, FuSeR, designed to effectively combine these features. Our results show that FuSeR outperforms models utilizing individual NSFs as well as baseline fusion techniques and obtains state-of-the-art (SOTA) performance in E-DAIC benchmark with RMSE of 5.51 and MAE of 4.48, establishing it as a robust approach for depression detection.
Are Music Foundation Models Better at Singing Voice Deepfake Detection? Far-Better Fuse them with Speech Foundation Models
Sep 21, 2024



In this study, for the first time, we extensively investigate whether music foundation models (MFMs) or speech foundation models (SFMs) work better for singing voice deepfake detection (SVDD), which has recently attracted attention in the research community. For this, we perform a comprehensive comparative study of state-of-the-art (SOTA) MFMs (MERT variants and music2vec) and SFMs (pre-trained for general speech representation learning as well as speaker recognition). We show that speaker recognition SFM representations perform the best amongst all the foundation models (FMs), and this performance can be attributed to its higher efficacy in capturing the pitch, tone, intensity, etc, characteristics present in singing voices. To our end, we also explore the fusion of FMs for exploiting their complementary behavior for improved SVDD, and we propose a novel framework, FIONA for the same. With FIONA, through the synchronization of x-vector (speaker recognition SFM) and MERT-v1-330M (MFM), we report the best performance with the lowest Equal Error Rate (EER) of 13.74 %, beating all the individual FMs as well as baseline FM fusions and achieving SOTA results.