 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Signals to Patterns: Non-Invasive Tuberculosis Detection from Cough Audio using Bandit Weighted Hyperbolic Prototypes
Jun 15, 2026In this study, we focus on cough-based tuberculosis screening (CBTS) and hypothesize that fusing speech/audio foundation representations with spectral descriptors will yield stronger screening performance. We expect this fusion to reveal complementary strengths: spectral features preserve fine-grained short-time acoustic detail in cough signals, while foundation embeddings capture higher-level temporal and event-level patterns learned from large-scale pretraining. To this end, we propose COBALT, a novel fusion framework based on codebook-aligned hyperbolic prototypes and bandit-style reliability weighting to integrate heterogeneous representations effectively. Using the CODA TB DREAM Challenge benchmark, COBALT consistently outperforms individual representations and a concatenation baseline, achieving the best overall performance when fusing MFCC with PaSST thereby establishing a new state-of-the-art on the benchmark.
Synergizing Zero-Shot Cross-Lingual Alzheimer Detection with Language-Invariant Multimodal Bi-Geometric Adversarial Learning
Jun 15, 2026In this work, we study zero-shot cross-lingual speech-based Alzheimer's disease detection (SADD). We hypothesize that learning language-invariant multimodal representations by fusing multilingual speech and text pretrained models is essential for reliable transfer to unseen languages, as the two modalities capture complementary acoustic and linguistic markers of cognitive impairment while adversarial learning suppresses language-specific confounds. Empirical results in zero-shot cross-lingual evaluation substantiate the hypothesis, showing that multimodal fusion consistently outperforms unimodal baselines. To this end, we propose ORBIT, a novel framework that combines cross-attentive fusion, multi-tap language adversaries, and complementary spherical--hyperbolic geometric learning with consensus clustering. Across settings, ORBIT achieves the strongest performance compared to unimodal models and simple concatenation-based fusion baselines.
Prosody as Supervision: Bridging the Non-Verbal--Verbal for Multilingual Speech Emotion Recognition
Apr 19, 2026In this work, we introduce a paralinguistic supervision paradigm for low-resource multilingual speech emotion recognition (LRM-SER) that leverages non-verbal vocalizations to exploit prosody-centric emotion cues. Unlike conventional SER systems that rely heavily on labeled verbal speech and suffer from poor cross-lingual transfer, our approach reformulates LRM-SER as non-verbal-to-verbal transfer, where supervision from a labeled non-verbal source domain is adapted to unlabeled verbal speech across multiple target languages. To this end, we propose NOVA ARC, a geometry-aware framework that models affective structure in the Poincaré ball, discretizes paralinguistic patterns via a hyperbolic vector-quantized prosody codebook, and captures emotion intensity through a hyperbolic emotion lens. For unsupervised adaptation, NOVA-ARC performs optimal transport based prototype alignment between source emotion prototypes and target utterances, inducing soft supervision for unlabeled speech while being stabilized through consistency regularization. Experiments show that NOVA-ARC delivers the strongest performance under both non-verbal-to-verbal adaptation and the complementary verbal-to-verbal transfer setting, consistently outperforming Euclidean counterparts and strong SSL baselines. To the best of our knowledge, this work is the first to move beyond verbal-speech-centric supervision by introducing a non-verbal-to-verbal transfer paradigm for SER.
HCFD: A Benchmark for Audio Deepfake Detection in Healthcare
Apr 19, 2026In this study, we present Healthcare Codec-Fake Detection (HCFD), a new task for detecting codec-fakes under pathological speech conditions. We intentionally focus on codec based synthetic speech in this work, since neural codec decoding forms a core building block in modern speech generation pipelines. First, we release Healthcare CodecFake, the first pathology-aware dataset containing paired real and NAC-synthesized speech across multipl clinical conditions and codec families. Our evaluations show that SOTA codec-fake detectors trained primarily on healthy speech perform poorly on Healthcare CodecFake, highlighting the need for HCFD-specific models. Second, we demonstrate that PaSST outperforms existing speech-based models for HCFD, benefiting from its patch-based spectro-temporal representation. Finally, we propose PHOENIX-Mamba, a geometry-aware framework that models codec-fakes as multiple self-discovered modes in hyperbolic space and achieves the strongest performance on HCFD across clinical conditions and codecs. Experiments on HCFK show that PHOENIX-Mamba (PaSST) achieves the best overall performance, reaching 97.04 Acc on E-Dep, 96.73 on E-Alz, and 96.57 on E-Dys, while maintaining strong results on Chinese with 94.41 (Dep), 94.40 (Alz), and 93.20 (Dys). This geometry-aware formulation enables self-discovered clustering of heterogeneous codec-fake modes in hyperbolic space, facilitating robust discrimination under pathological speech variability. PHOENIX-Mamba achieves topmost performance on the HCFD task across clinical conditions and codecs.
DIVINE: Coordinating Multimodal Disentangled Representations for Oro-Facial Neurological Disorder Assessment
Jan 11, 2026In this study, we present a multimodal framework for predicting neuro-facial disorders by capturing both vocal and facial cues. We hypothesize that explicitly disentangling shared and modality-specific representations within multimodal foundation model embeddings can enhance clinical interpretability and generalization. To validate this hypothesis, we propose DIVINE a fully disentangled multimodal framework that operates on representations extracted from state-of-the-art (SOTA) audio and video foundation models, incorporating hierarchical variational bottlenecks, sparse gated fusion, and learnable symptom tokens. DIVINE operates in a multitask learning setup to jointly predict diagnostic categories (Healthy Control,ALS, Stroke) and severity levels (Mild, Moderate, Severe). The model is trained using synchronized audio and video inputs and evaluated on the Toronto NeuroFace dataset under full (audio-video) as well as single-modality (audio-only and video-only) test conditions. Our proposed approach, DIVINE achieves SOTA result, with the DeepSeek-VL2 and TRILLsson combination reaching 98.26% accuracy and 97.51% F1-score. Under modality-constrained scenarios, the framework performs well, showing strong generalization when tested with video-only or audio-only inputs. It consistently yields superior performance compared to unimodal models and baseline fusion techniques. To the best of our knowledge, DIVINE is the first framework that combines cross-modal disentanglement, adaptive fusion, and multitask learning to comprehensively assess neurological disorders using synchronized speech and facial video.
Bridging Attribution and Open-Set Detection using Graph-Augmented Instance Learning in Synthetic Speech
Jan 11, 2026We propose a unified framework for not only attributing synthetic speech to its source but also for detecting speech generated by synthesizers that were not encountered during training. This requires methods that move beyond simple detection to support both detailed forensic analysis and open-set generalization. To address this, we introduce SIGNAL, a hybrid framework that combines speech foundation models (SFMs) with graph-based modeling and open-set-aware inference. Our framework integrates Graph Neural Networks (GNNs) and a k-Nearest Neighbor (KNN) classifier, allowing it to capture meaningful relationships between utterances and recognize speech that doesn`t belong to any known generator. It constructs a query-conditioned graph over generator class prototypes, enabling the GNN to reason over relationships among candidate generators, while the KNN branch supports open-set detection via confidence-based thresholding. We evaluate SIGNAL using the DiffSSD dataset, which offers a diverse mix of real speech and synthetic audio from both open-source and commercial diffusion-based TTS systems. To further assess generalization, we also test on the SingFake benchmark. Our results show that SIGNAL consistently improves performance across both tasks, with Mamba-based embeddings delivering especially strong results. To the best of our knowledge, this is the first study to unify graph-based learning and open-set detection for tracing synthetic speech back to its origin.
Curved Worlds, Clear Boundaries: Generalizing Speech Deepfake Detection using Hyperbolic and Spherical Geometry Spaces
Nov 13, 2025In this work, we address the challenge of generalizable audio deepfake detection (ADD) across diverse speech synthesis paradigms-including conventional text-to-speech (TTS) systems and modern diffusion or flow-matching (FM) based generators. Prior work has mostly targeted individual synthesis families and often fails to generalize across paradigms due to overfitting to generation-specific artifacts. We hypothesize that synthetic speech, irrespective of its generative origin, leaves behind shared structural distortions in the embedding space that can be aligned through geometry-aware modeling. To this end, we propose RHYME, a unified detection framework that fuses utterance-level embeddings from diverse pretrained speech encoders using non-Euclidean projections. RHYME maps representations into hyperbolic and spherical manifolds-where hyperbolic geometry excels at modeling hierarchical generator families, and spherical projections capture angular, energy-invariant cues such as periodic vocoder artifacts. The fused representation is obtained via Riemannian barycentric averaging, enabling synthesis-invariant alignment. RHYME outperforms individual PTMs and homogeneous fusion baselines, achieving top performance and setting new state-of-the-art in cross-paradigm ADD.
Towards Attribution of Generators and Emotional Manipulation in Cross-Lingual Synthetic Speech using Geometric Learning
Nov 13, 2025



In this work, we address the problem of finegrained traceback of emotional and manipulation characteristics from synthetically manipulated speech. We hypothesize that combining semantic-prosodic cues captured by Speech Foundation Models (SFMs) with fine-grained spectral dynamics from auditory representations can enable more precise tracing of both emotion and manipulation source. To validate this hypothesis, we introduce MiCuNet, a novel multitask framework for fine-grained tracing of emotional and manipulation attributes in synthetically generated speech. Our approach integrates SFM embeddings with spectrogram-based auditory features through a mixed-curvature projection mechanism that spans Hyperbolic, Euclidean, and Spherical spaces guided by a learnable temporal gating mechanism. Our proposed method adopts a multitask learning setup to simultaneously predict original emotions, manipulated emotions, and manipulation sources on the EmoFake dataset (EFD) across both English and Chinese subsets. MiCuNet yields consistent improvements, consistently surpassing conventional fusion strategies. To the best of our knowledge, this work presents the first study to explore a curvature-adaptive framework specifically tailored for multitask tracking in synthetic speech.
Avengers Assemble: Amalgamation of Non-Semantic Features for Depression Detection
Sep 22, 2024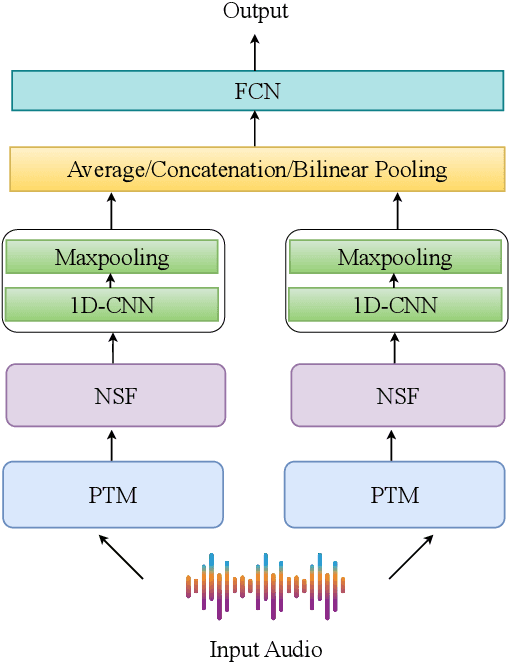
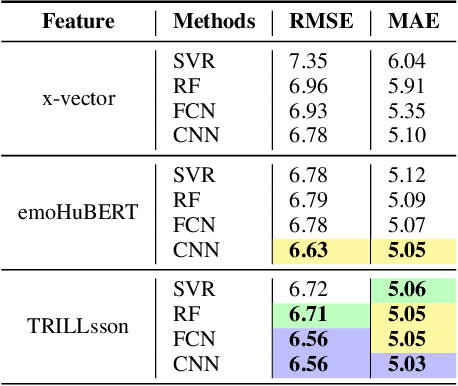
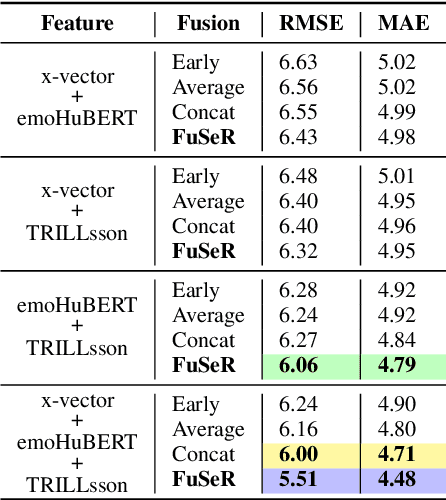
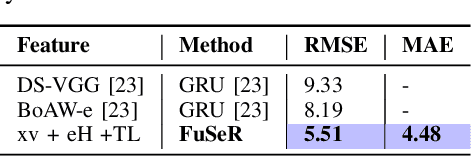
In this study, we address the challenge of depression detection from speech, focusing on the potential of non-semantic features (NSFs) to capture subtle markers of depression. While prior research has leveraged various features for this task, NSFs-extracted from pre-trained models (PTMs) designed for non-semantic tasks such as paralinguistic speech processing (TRILLsson), speaker recognition (x-vector), and emotion recognition (emoHuBERT)-have shown significant promise. However, the potential of combining these diverse features has not been fully explored. In this work, we demonstrate that the amalgamation of NSFs results in complementary behavior, leading to enhanced depression detection performance. Furthermore, to our end, we introduce a simple novel framework, FuSeR, designed to effectively combine these features. Our results show that FuSeR outperforms models utilizing individual NSFs as well as baseline fusion techniques and obtains state-of-the-art (SOTA) performance in E-DAIC benchmark with RMSE of 5.51 and MAE of 4.48, establishing it as a robust approach for depression detection.
Speech Recognition Transformers: Topological-lingualism Perspective
Aug 27, 2024



Transformers have evolved with great success in various artificial intelligence tasks. Thanks to our recent prevalence of self-attention mechanisms, which capture long-term dependency, phenomenal outcomes in speech processing and recognition tasks have been produced. The paper presents a comprehensive survey of transformer techniques oriented in speech modality. The main contents of this survey include (1) background of traditional ASR, end-to-end transformer ecosystem, and speech transformers (2) foundational models in a speech via lingualism paradigm, i.e., monolingual, bilingual, multilingual, and cross-lingual (3) dataset and languages, acoustic features, architecture, decoding, and evaluation metric from a specific topological lingualism perspective (4) popular speech transformer toolkit for building end-to-end ASR systems. Finally, highlight the discussion of open challenges and potential research directions for the community to conduct further research in this domain.