 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Student Perception on Gen AI Adoption in Higher Education: A Descriptive Study
Mar 29, 2026The rapid proliferation of Generative Artificial Intelligence (GenAI) is reshaping pedagogical practices and assessment models in higher education. While institutional and educator perspectives on GenAI integration are increasingly documented, the student perspective remains comparatively underexplored. This study examines how students perceive, use, and evaluate GenAI within their academic practices, focusing on usage patterns, perceived benefits, and expectations for institutional support. Data were collected through a questionnaire administered to 436 postgraduate Computer Science students at the University of Hertfordshire and analysed using descriptive methods. The findings reveal a Confidence-Competence Paradox: although more than 60% of students report high familiarity with tools such as ChatGPT, daily academic use remains limited and confidence in effective application is only moderate. Students primarily employ GenAI for cognitive scaffolding tasks, including concept clarification and brainstorming, rather than fully automated content generation. At the same time, respondents express concerns regarding data privacy, reliability of AI-generated information, and the potential erosion of critical thinking skills. The results also indicate strong student support for integrating AI literacy into curricula and programme Knowledge, Skills, and Behaviours (KSBs). Overall, the study suggests that universities should move beyond a policing approach to GenAI and adopt a pedagogical framework that emphasises AI literacy, ethical guidance, and equitable access to AI tools.
Paired and Unpaired Image to Image Translation using Generative Adversarial Networks
May 22, 2025Image to image translation is an active area of research in the field of computer vision, enabling the generation of new images with different styles, textures, or resolutions while preserving their characteristic properties. Recent architectures leverage Generative Adversarial Networks (GANs) to transform input images from one domain to another. In this work, we focus on the study of both paired and unpaired image translation across multiple image domains. For the paired task, we used a conditional GAN model, and for the unpaired task, we trained it using cycle consistency loss. We experimented with different types of loss functions, multiple Patch-GAN sizes, and model architectures. New quantitative metrics - precision, recall, and FID score - were used for analysis. In addition, a qualitative study of the results of different experiments was conducted.
Benchmarking the Effectiveness of Classification Algorithms and SVM Kernels for Dry Beans
Jul 15, 2023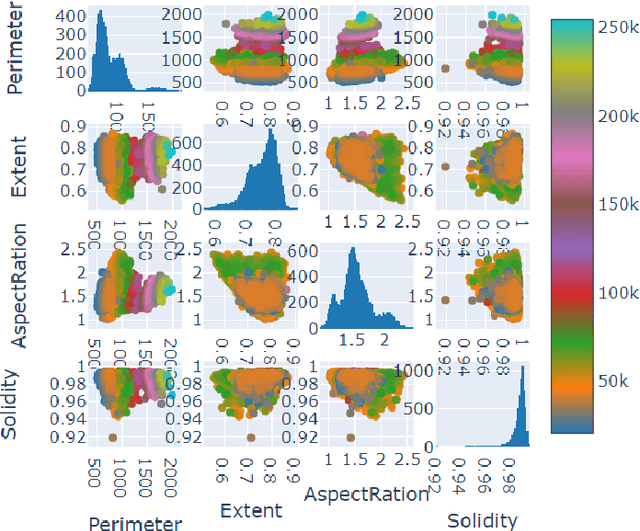
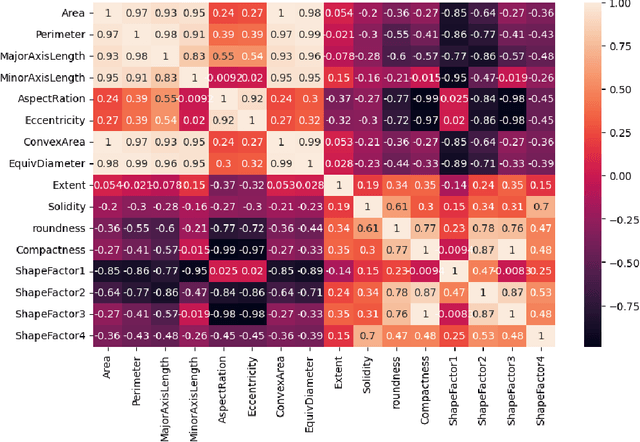

Plant breeders and agricultural researchers can increase crop productivity by identifying desirable features, disease resistance, and nutritional content by analysing the Dry Bean dataset. This study analyses and compares different Support Vector Machine (SVM) classification algorithms, namely linear, polynomial, and radial basis function (RBF), along with other popular classification algorithms. The analysis is performed on the Dry Bean Dataset, with PCA (Principal Component Analysis) conducted as a preprocessing step for dimensionality reduction. The primary evaluation metric used is accuracy, and the RBF SVM kernel algorithm achieves the highest Accuracy of 93.34%, Precision of 92.61%, Recall of 92.35% and F1 Score as 91.40%. Along with adept visualization and empirical analysis, this study offers valuable guidance by emphasizing the importance of considering different SVM algorithms for complex and non-linear structured datasets.
Medical Question Understanding and Answering with Knowledge Grounding and Semantic Self-Supervision
Sep 30, 2022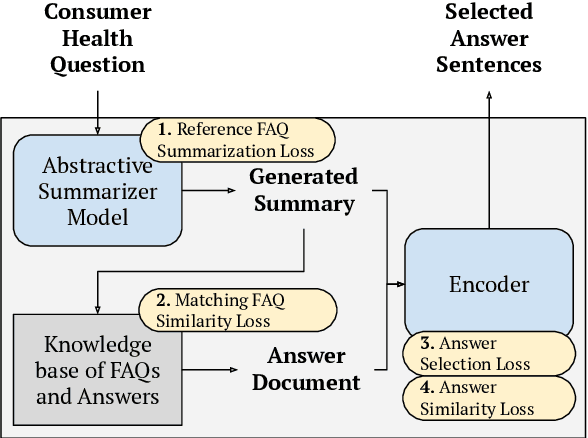
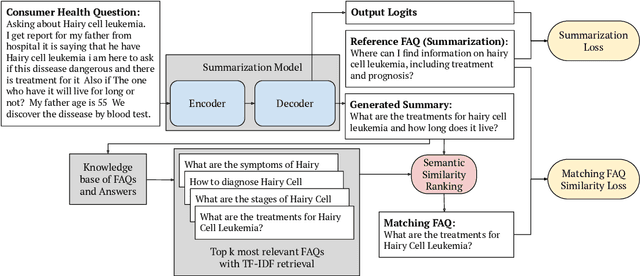

Current medical question answering systems have difficulty processing long, detailed and informally worded questions submitted by patients, called Consumer Health Questions (CHQs). To address this issue, we introduce a medical question understanding and answering system with knowledge grounding and semantic self-supervision. Our system is a pipeline that first summarizes a long, medical, user-written question, using a supervised summarization loss. Then, our system performs a two-step retrieval to return answers. The system first matches the summarized user question with an FAQ from a trusted medical knowledge base, and then retrieves a fixed number of relevant sentences from the corresponding answer document. In the absence of labels for question matching or answer relevance, we design 3 novel, self-supervised and semantically-guided losses. We evaluate our model against two strong retrieval-based question answering baselines. Evaluators ask their own questions and rate the answers retrieved by our baselines and own system according to their relevance. They find that our system retrieves more relevant answers, while achieving speeds 20 times faster. Our self-supervised losses also help the summarizer achieve higher scores in ROUGE, as well as in human evaluation metrics. We release our code to encourage further research.
Prediction of COVID-19 using chest X-ray images
Apr 08, 2022COVID-19, also known as Novel Coronavirus Disease, is a highly contagious disease that first surfaced in China in late 2019. SARS-CoV-2 is a coronavirus that belongs to the vast family of coronaviruses that causes this disease. The sickness originally appeared in Wuhan, China in December 2019 and quickly spread to over 213 nations, becoming a global pandemic. Fever, dry cough, and tiredness are the most typical COVID-19 symptoms. Aches, pains, and difficulty breathing are some of the other symptoms that patients may face. The majority of these symptoms are indicators of respiratory infections and lung abnormalities, which radiologists can identify. Chest x-rays of COVID-19 patients seem similar, with patchy and hazy lungs rather than clear and healthy lungs. On x-rays, however, pneumonia and other chronic lung disorders can resemble COVID-19. Trained radiologists must be able to distinguish between COVID-19 and an illness that is less contagious. Our AI algorithm seeks to give doctors a quantitative estimate of the risk of deterioration. So that patients at high risk of deterioration can be triaged and treated efficiently. The method could be particularly useful in pandemic hotspots when screening upon admission is important for allocating limited resources like hospital beds.
RerrFact: Reduced Evidence Retrieval Representations for Scientific Claim Verification
Feb 05, 2022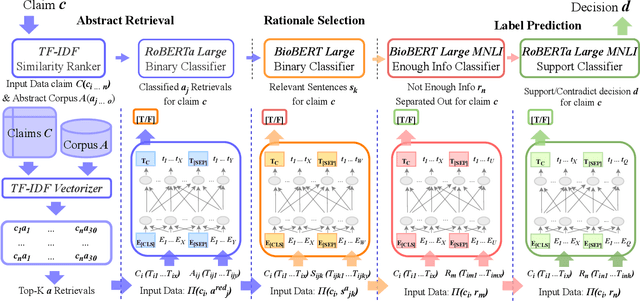



Exponential growth in digital information outlets and the race to publish has made scientific misinformation more prevalent than ever. However, the task to fact-verify a given scientific claim is not straightforward even for researchers. Scientific claim verification requires in-depth knowledge and great labor from domain experts to substantiate supporting and refuting evidence from credible scientific sources. The SciFact dataset and corresponding task provide a benchmarking leaderboard to the community to develop automatic scientific claim verification systems via extracting and assimilating relevant evidence rationales from source abstracts. In this work, we propose a modular approach that sequentially carries out binary classification for every prediction subtask as in the SciFact leaderboard. Our simple classifier-based approach uses reduced abstract representations to retrieve relevant abstracts. These are further used to train the relevant rationale-selection model. Finally, we carry out two-step stance predictions that first differentiate non-relevant rationales and then identify supporting or refuting rationales for a given claim. Experimentally, our system RerrFact with no fine-tuning, simple design, and a fraction of model parameters fairs competitively on the leaderboard against large-scale, modular, and joint modeling approaches. We make our codebase available at https://github.com/ashishrana160796/RerrFact.
Anomalous Motion Detection on Highway Using Deep Learning
Jun 15, 2020



Research in visual anomaly detection draws much interest due to its applications in surveillance. Common datasets for evaluation are constructed using a stationary camera overlooking a region of interest. Previous research has shown promising results in detecting spatial as well as temporal anomalies in these settings. The advent of self-driving cars provides an opportunity to apply visual anomaly detection in a more dynamic application yet no dataset exists in this type of environment. This paper presents a new anomaly detection dataset - the Highway Traffic Anomaly (HTA) dataset - for the problem of detecting anomalous traffic patterns from dash cam videos of vehicles on highways. We evaluate state-of-the-art deep learning anomaly detection models and propose novel variations to these methods. Our results show that state-of-the-art models built for settings with a stationary camera do not translate well to a more dynamic environment. The proposed variations to these SoTA methods show promising results on the new HTA dataset.
Exploring Cell counting with Neural Arithmetic Logic Units
Apr 14, 2020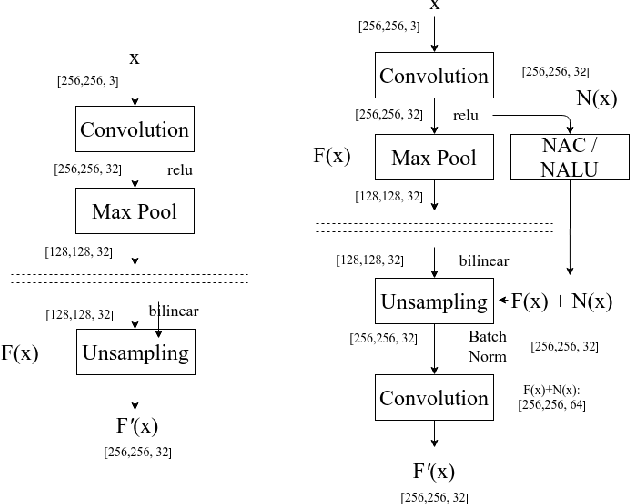
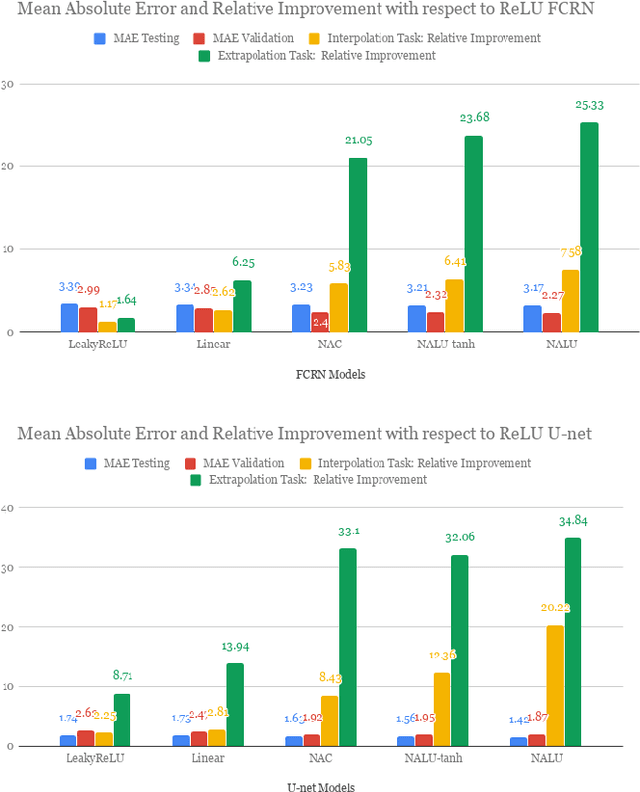
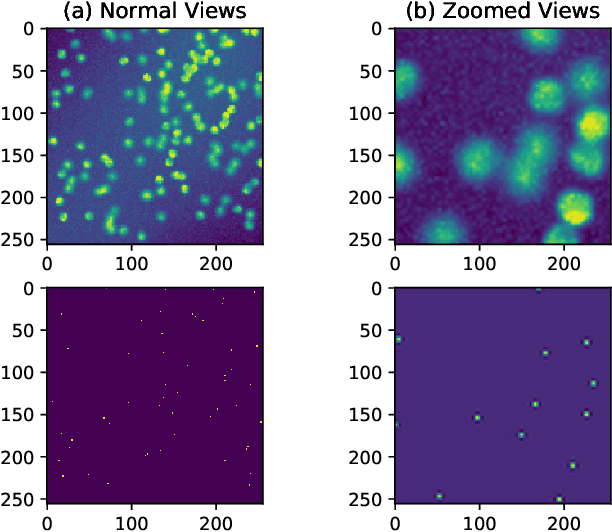
The big problem for neural network models which are trained to count instances is that whenever test range goes high training range generalization error increases i.e. they are not good generalizers outside training range. Consider the case of automating cell counting process where more dense images with higher cell counts are commonly encountered as compared to images used in training data. By making better predictions for higher ranges of cell count we are aiming to create better generalization systems for cell counting. With architecture proposal of neural arithmetic logic units (NALU) for arithmetic operations, task of counting has become feasible for higher numeric ranges which were not included in training data with better accuracy. As a part of our study we used these units and different other activation functions for learning cell counting task with two different architectures namely Fully Convolutional Regression Network and U-Net. These numerically biased units are added in the form of residual concatenated layers to original architectures and a comparative experimental study is done with these newly proposed changes . This comparative study is described in terms of optimizing regression loss problem from these models trained with extensive data augmentation techniques. We were able to achieve better results in our experiments of cell counting tasks with introduction of these numerically biased units to already existing architectures in the form of residual layer concatenation connections. Our results confirm that above stated numerically biased units does help models to learn numeric quantities for better generalization results.