 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgent-Testing Agent: A Meta-Agent for Automated Testing and Evaluation of Conversational AI Agents
Aug 24, 2025
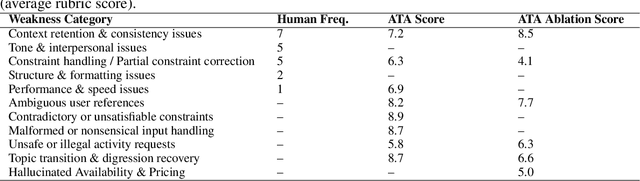
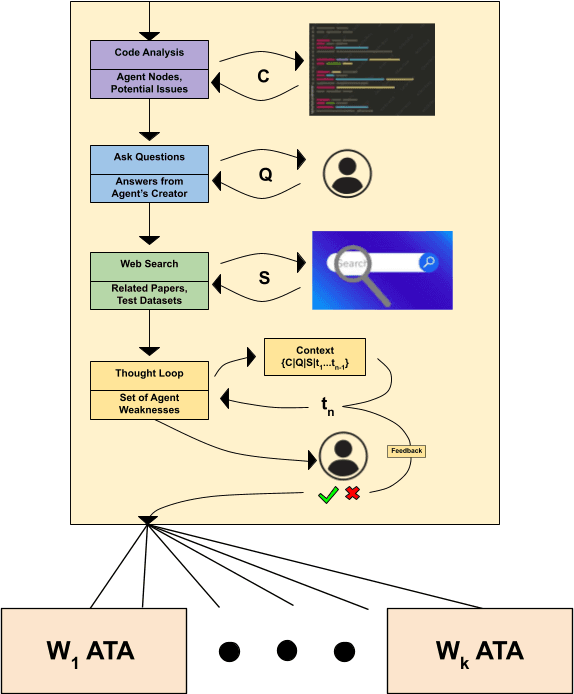
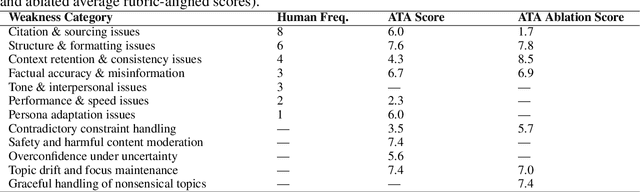
LLM agents are increasingly deployed to plan, retrieve, and write with tools, yet evaluation still leans on static benchmarks and small human studies. We present the Agent-Testing Agent (ATA), a meta-agent that combines static code analysis, designer interrogation, literature mining, and persona-driven adversarial test generation whose difficulty adapts via judge feedback. Each dialogue is scored with an LLM-as-a-Judge (LAAJ) rubric and used to steer subsequent tests toward the agent's weakest capabilities. On a travel planner and a Wikipedia writer, the ATA surfaces more diverse and severe failures than expert annotators while matching severity, and finishes in 20--30 minutes versus ten-annotator rounds that took days. Ablating code analysis and web search increases variance and miscalibration, underscoring the value of evidence-grounded test generation. The ATA outputs quantitative metrics and qualitative bug reports for developers. We release the full methodology and open-source implementation for reproducible agent testing: https://github.com/KhalilMrini/Agent-Testing-Agent
Fast Prompt Alignment for Text-to-Image Generation
Dec 11, 2024
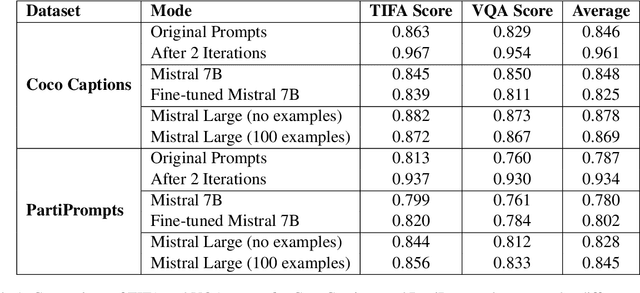
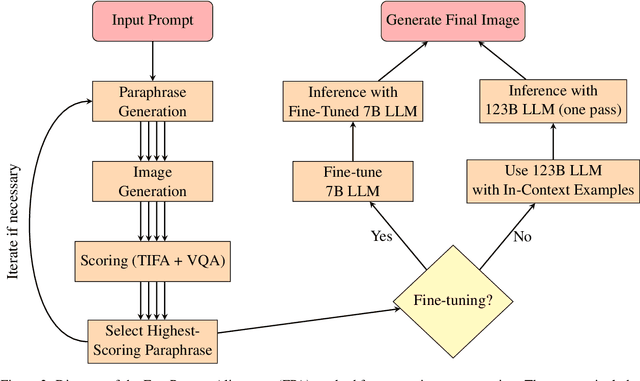
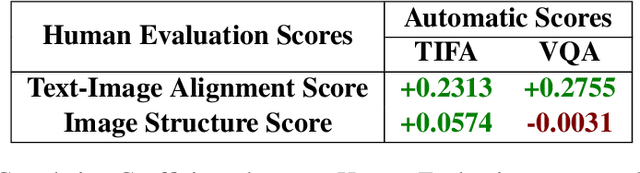
Text-to-image generation has advanced rapidly, yet aligning complex textual prompts with generated visuals remains challenging, especially with intricate object relationships and fine-grained details. This paper introduces Fast Prompt Alignment (FPA), a prompt optimization framework that leverages a one-pass approach, enhancing text-to-image alignment efficiency without the iterative overhead typical of current methods like OPT2I. FPA uses large language models (LLMs) for single-iteration prompt paraphrasing, followed by fine-tuning or in-context learning with optimized prompts to enable real-time inference, reducing computational demands while preserving alignment fidelity. Extensive evaluations on the COCO Captions and PartiPrompts datasets demonstrate that FPA achieves competitive text-image alignment scores at a fraction of the processing time, as validated through both automated metrics (TIFA, VQA) and human evaluation. A human study with expert annotators further reveals a strong correlation between human alignment judgments and automated scores, underscoring the robustness of FPA's improvements. The proposed method showcases a scalable, efficient alternative to iterative prompt optimization, enabling broader applicability in real-time, high-demand settings. The codebase is provided to facilitate further research: https://github.com/tiktok/fast_prompt_alignment
Finetuned Multimodal Language Models Are High-Quality Image-Text Data Filters
Mar 05, 2024



We propose a novel framework for filtering image-text data by leveraging fine-tuned Multimodal Language Models (MLMs). Our approach outperforms predominant filtering methods (e.g., CLIPScore) via integrating the recent advances in MLMs. We design four distinct yet complementary metrics to holistically measure the quality of image-text data. A new pipeline is established to construct high-quality instruction data for fine-tuning MLMs as data filters. Comparing with CLIPScore, our MLM filters produce more precise and comprehensive scores that directly improve the quality of filtered data and boost the performance of pre-trained models. We achieve significant improvements over CLIPScore on popular foundation models (i.e., CLIP and BLIP2) and various downstream tasks. Our MLM filter can generalize to different models and tasks, and be used as a drop-in replacement for CLIPScore. An additional ablation study is provided to verify our design choices for the MLM filter.
InfiMM-Eval: Complex Open-Ended Reasoning Evaluation For Multi-Modal Large Language Models
Dec 04, 2023
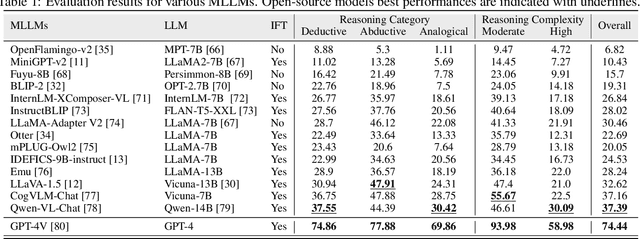
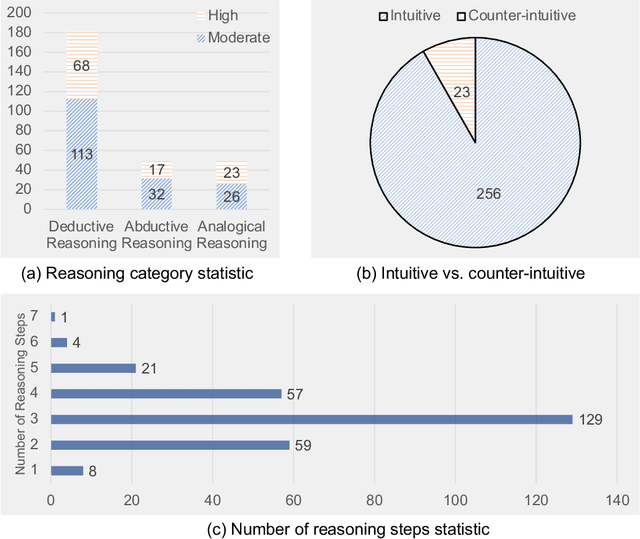
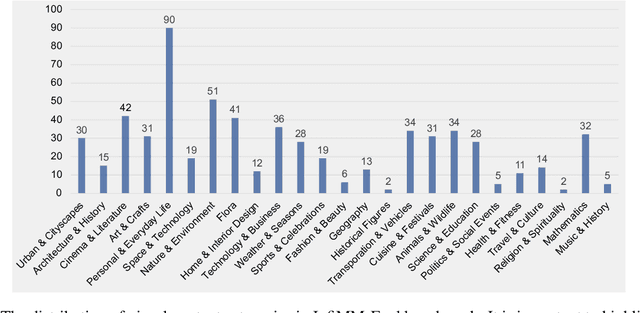
Multi-modal Large Language Models (MLLMs) are increasingly prominent in the field of artificial intelligence. These models not only excel in traditional vision-language tasks but also demonstrate impressive performance in contemporary multi-modal benchmarks. Although many of these benchmarks attempt to holistically evaluate MLLMs, they typically concentrate on basic reasoning tasks, often yielding only simple yes/no or multi-choice responses. These methods naturally lead to confusion and difficulties in conclusively determining the reasoning capabilities of MLLMs. To mitigate this issue, we manually curate a benchmark dataset specifically designed for MLLMs, with a focus on complex reasoning tasks. Our benchmark comprises three key reasoning categories: deductive, abductive, and analogical reasoning. The queries in our dataset are intentionally constructed to engage the reasoning capabilities of MLLMs in the process of generating answers. For a fair comparison across various MLLMs, we incorporate intermediate reasoning steps into our evaluation criteria. In instances where an MLLM is unable to produce a definitive answer, its reasoning ability is evaluated by requesting intermediate reasoning steps. If these steps align with our manual annotations, appropriate scores are assigned. This evaluation scheme resembles methods commonly used in human assessments, such as exams or assignments, and represents what we consider a more effective assessment technique compared with existing benchmarks. We evaluate a selection of representative MLLMs using this rigorously developed open-ended multi-step elaborate reasoning benchmark, designed to challenge and accurately measure their reasoning capabilities. The code and data will be released at https://infimm.github.io/InfiMM-Eval/
Medical Question Understanding and Answering with Knowledge Grounding and Semantic Self-Supervision
Sep 30, 2022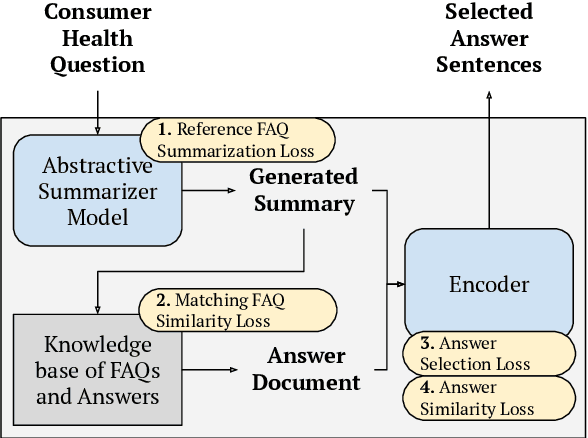
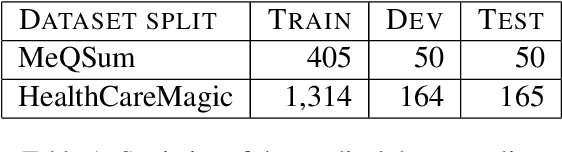
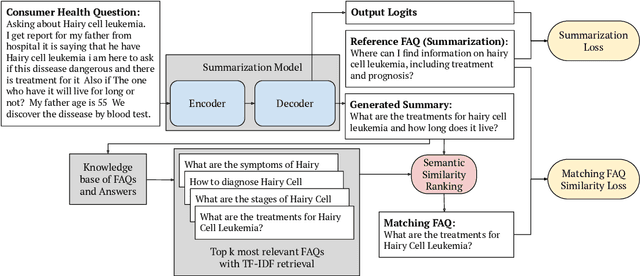

Current medical question answering systems have difficulty processing long, detailed and informally worded questions submitted by patients, called Consumer Health Questions (CHQs). To address this issue, we introduce a medical question understanding and answering system with knowledge grounding and semantic self-supervision. Our system is a pipeline that first summarizes a long, medical, user-written question, using a supervised summarization loss. Then, our system performs a two-step retrieval to return answers. The system first matches the summarized user question with an FAQ from a trusted medical knowledge base, and then retrieves a fixed number of relevant sentences from the corresponding answer document. In the absence of labels for question matching or answer relevance, we design 3 novel, self-supervised and semantically-guided losses. We evaluate our model against two strong retrieval-based question answering baselines. Evaluators ask their own questions and rate the answers retrieved by our baselines and own system according to their relevance. They find that our system retrieves more relevant answers, while achieving speeds 20 times faster. Our self-supervised losses also help the summarizer achieve higher scores in ROUGE, as well as in human evaluation metrics. We release our code to encourage further research.
Sentence-level Privacy for Document Embeddings
May 10, 2022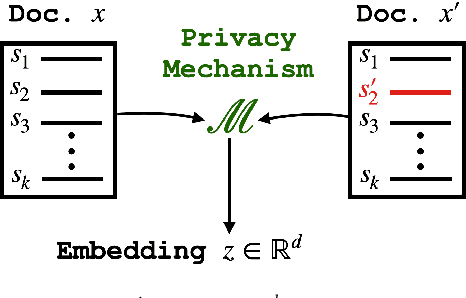
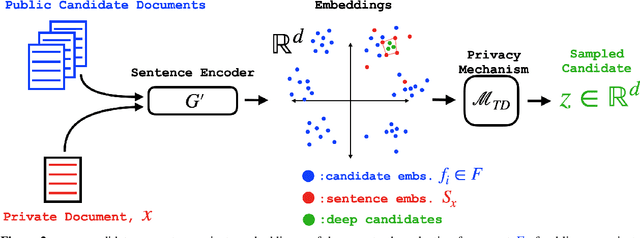
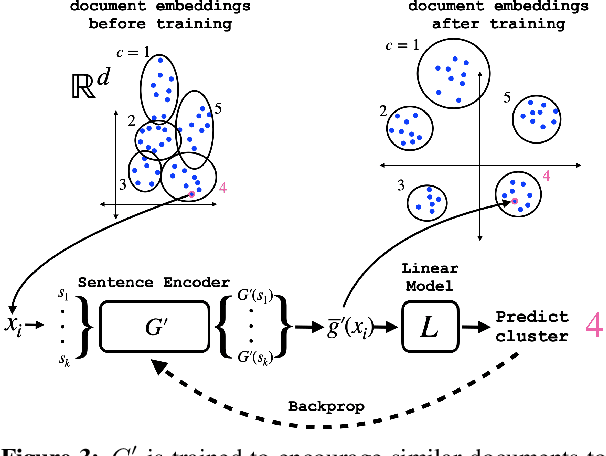
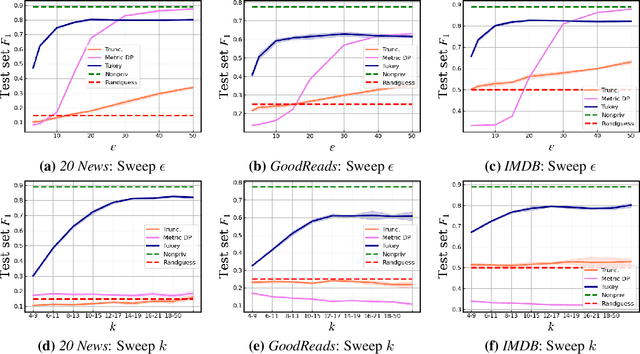
User language data can contain highly sensitive personal content. As such, it is imperative to offer users a strong and interpretable privacy guarantee when learning from their data. In this work, we propose SentDP: pure local differential privacy at the sentence level for a single user document. We propose a novel technique, DeepCandidate, that combines concepts from robust statistics and language modeling to produce high-dimensional, general-purpose $\epsilon$-SentDP document embeddings. This guarantees that any single sentence in a document can be substituted with any other sentence while keeping the embedding $\epsilon$-indistinguishable. Our experiments indicate that these private document embeddings are useful for downstream tasks like sentiment analysis and topic classification and even outperform baseline methods with weaker guarantees like word-level Metric DP.
Detection, Disambiguation, Re-ranking: Autoregressive Entity Linking as a Multi-Task Problem
Apr 12, 2022
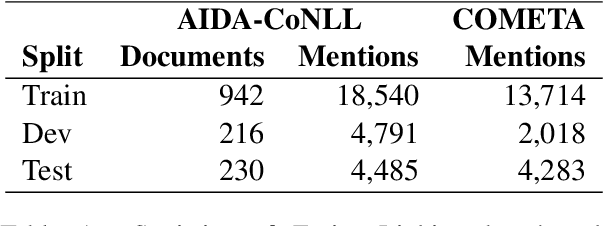
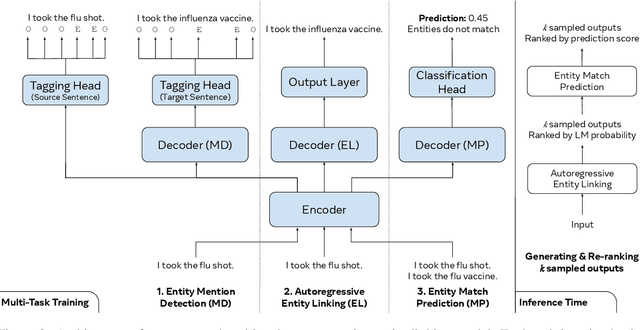
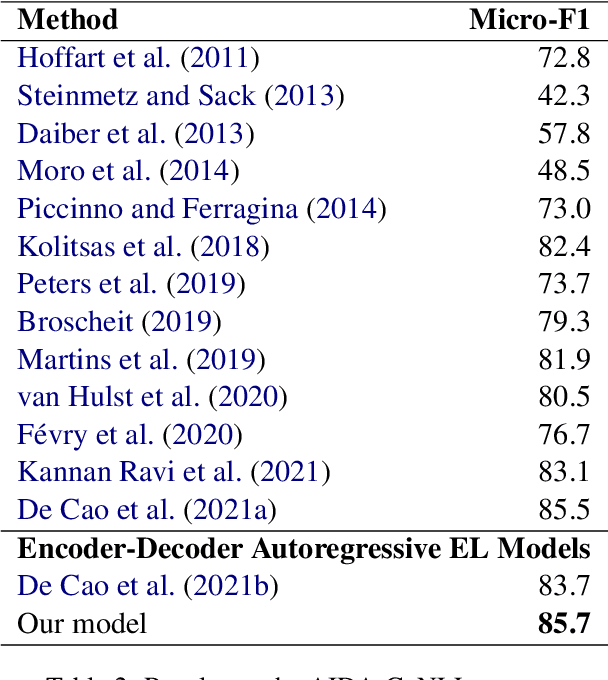
We propose an autoregressive entity linking model, that is trained with two auxiliary tasks, and learns to re-rank generated samples at inference time. Our proposed novelties address two weaknesses in the literature. First, a recent method proposes to learn mention detection and then entity candidate selection, but relies on predefined sets of candidates. We use encoder-decoder autoregressive entity linking in order to bypass this need, and propose to train mention detection as an auxiliary task instead. Second, previous work suggests that re-ranking could help correct prediction errors. We add a new, auxiliary task, match prediction, to learn re-ranking. Without the use of a knowledge base or candidate sets, our model sets a new state of the art in two benchmark datasets of entity linking: COMETA in the biomedical domain, and AIDA-CoNLL in the news domain. We show through ablation studies that each of the two auxiliary tasks increases performance, and that re-ranking is an important factor to the increase. Finally, our low-resource experimental results suggest that performance on the main task benefits from the knowledge learned by the auxiliary tasks, and not just from the additional training data.
Rethinking Self-Attention: An Interpretable Self-Attentive Encoder-Decoder Parser
Nov 10, 2019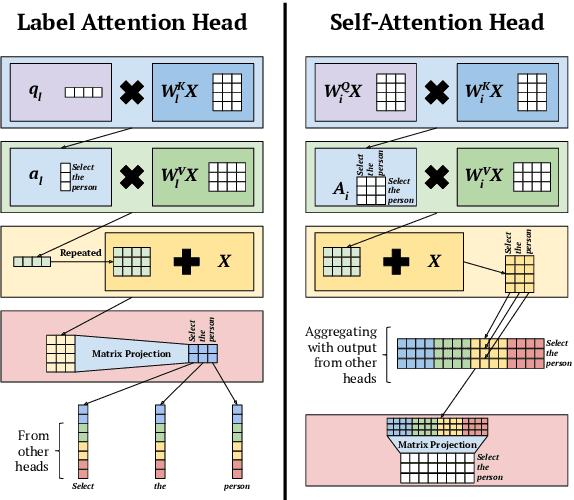
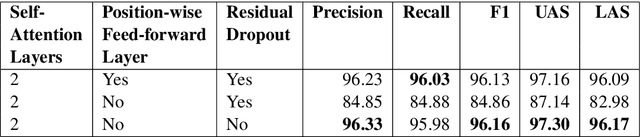
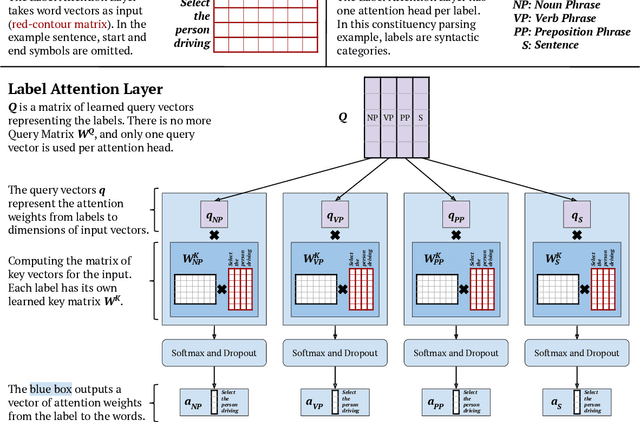
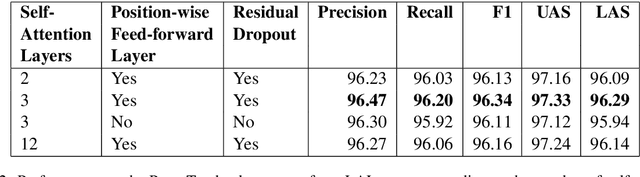
Attention mechanisms have improved the performance of NLP tasks while providing for appearance of model interpretability. Self-attention is currently widely used in NLP models, however it is difficult to interpret due to the numerous attention distributions. We hypothesize that model representations can benefit from label-specific information, while facilitating interpretation of predictions. We introduce the Label Attention Layer: a new form of self-attention where attention heads represent labels. We validate our hypothesis by running experiments in constituency and dependency parsing and show our new model obtains new state-of-the-art results for both tasks on the English Penn Treebank. Our neural parser obtains 96.34 F1 score for constituency parsing, and 97.33 UAS and 96.29 LAS for dependency parsing. Additionally, our model requires fewer layers, therefore, fewer parameters compared to existing work.
Structure Tree-LSTM: Structure-aware Attentional Document Encoders
Feb 26, 2019

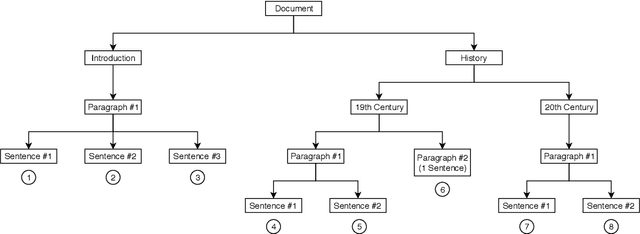
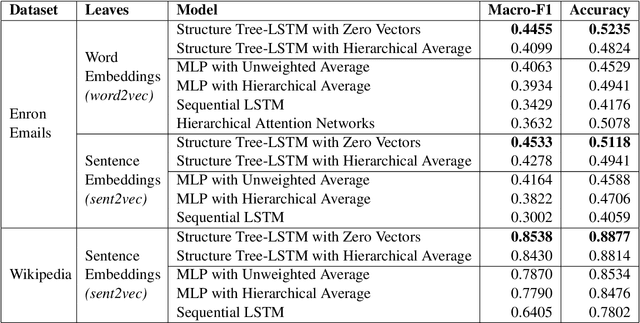
We propose a method to create document representations that reflect their internal structure. We modify Tree-LSTMs to hierarchically merge basic elements like words and sentences into blocks of increasing complexity. Our Structure Tree-LSTM implements a hierarchical attention mechanism over individual components and combinations thereof. We thus emphasize the usefulness of Tree-LSTMs for texts larger than a sentence. We show that structure-aware encoders can be used to improve the performance of document classification. We demonstrate that our method is resilient to changes to the basic building blocks, as it performs well with both sentence and word embeddings. The Structure Tree-LSTM outperforms all the baselines on two datasets when structural clues like sections are available, but also in the presence of mere paragraphs. On a third dataset from the medical domain, our model achieves competitive performance with the state of the art. This result shows the Structure Tree-LSTM can leverage dependency relations other than text structure, such as a set of reports on the same patient.