 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradients Look Alike: Sensitivity is Often Overestimated in DP-SGD
Jul 01, 2023



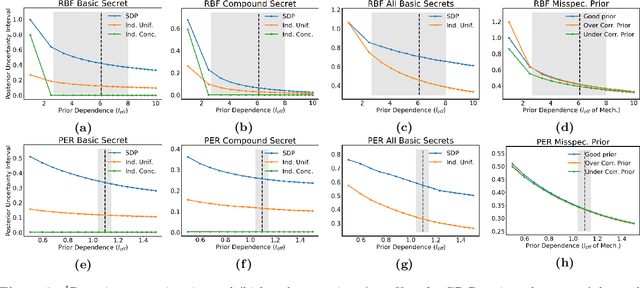
Differentially private stochastic gradient descent (DP-SGD) is the canonical algorithm for private deep learning. While it is known that its privacy analysis is tight in the worst-case, several empirical results suggest that when training on common benchmark datasets, the models obtained leak significantly less privacy for many datapoints. In this paper, we develop a new analysis for DP-SGD that captures the intuition that points with similar neighbors in the dataset enjoy better privacy than outliers. Formally, this is done by modifying the per-step privacy analysis of DP-SGD to introduce a dependence on the distribution of model updates computed from a training dataset. We further develop a new composition theorem to effectively use this new per-step analysis to reason about an entire training run. Put all together, our evaluation shows that this novel DP-SGD analysis allows us to now formally show that DP-SGD leaks significantly less privacy for many datapoints. In particular, we observe that correctly classified points obtain better privacy guarantees than misclassified points.
Do SSL Models Have Déjà Vu? A Case of Unintended Memorization in Self-supervised Learning
Apr 28, 2023
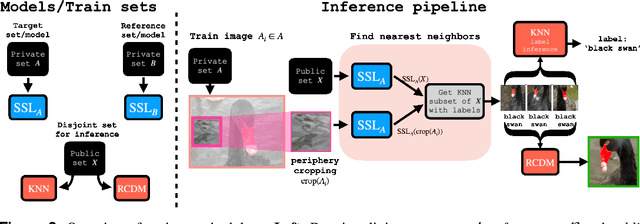
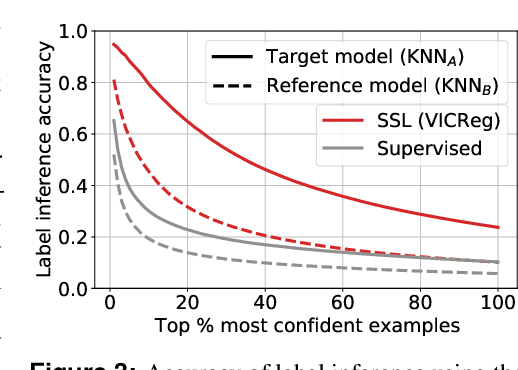
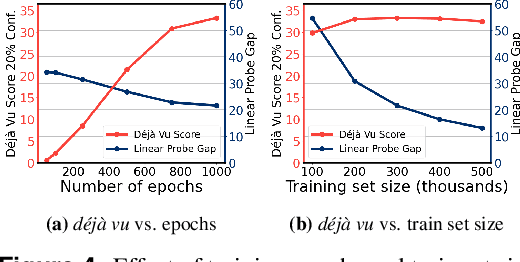
Self-supervised learning (SSL) algorithms can produce useful image representations by learning to associate different parts of natural images with one another. However, when taken to the extreme, SSL models can unintendedly memorize specific parts in individual training samples rather than learning semantically meaningful associations. In this work, we perform a systematic study of the unintended memorization of image-specific information in SSL models -- which we refer to as d\'ej\`a vu memorization. Concretely, we show that given the trained model and a crop of a training image containing only the background (e.g., water, sky, grass), it is possible to infer the foreground object with high accuracy or even visually reconstruct it. Furthermore, we show that d\'ej\`a vu memorization is common to different SSL algorithms, is exacerbated by certain design choices, and cannot be detected by conventional techniques for evaluating representation quality. Our study of d\'ej\`a vu memorization reveals previously unknown privacy risks in SSL models, as well as suggests potential practical mitigation strategies. Code is available at https://github.com/facebookresearch/DejaVu.
Sentence-level Privacy for Document Embeddings
May 10, 2022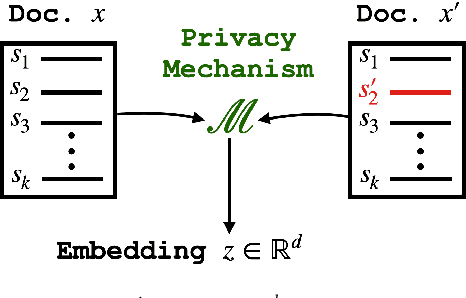
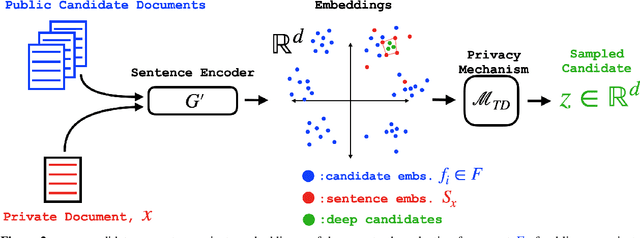
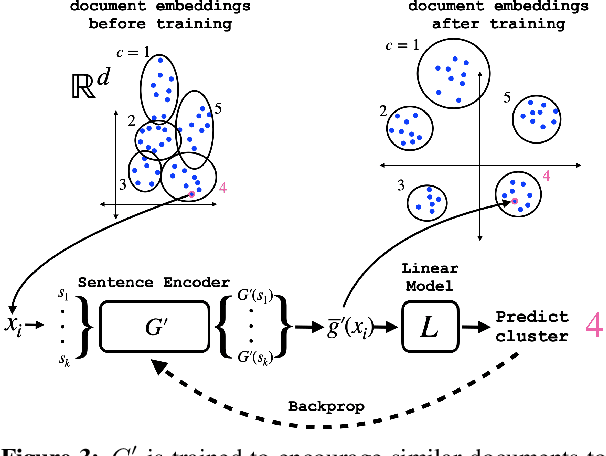
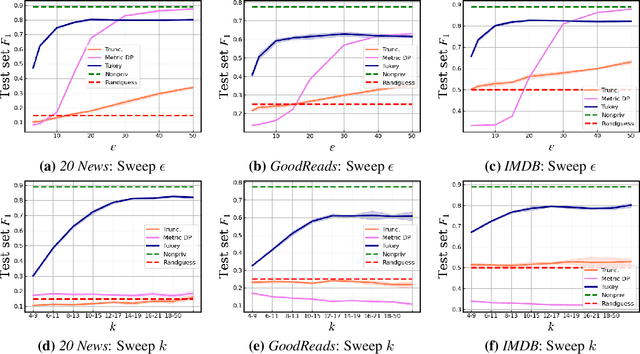
User language data can contain highly sensitive personal content. As such, it is imperative to offer users a strong and interpretable privacy guarantee when learning from their data. In this work, we propose SentDP: pure local differential privacy at the sentence level for a single user document. We propose a novel technique, DeepCandidate, that combines concepts from robust statistics and language modeling to produce high-dimensional, general-purpose $\epsilon$-SentDP document embeddings. This guarantees that any single sentence in a document can be substituted with any other sentence while keeping the embedding $\epsilon$-indistinguishable. Our experiments indicate that these private document embeddings are useful for downstream tasks like sentiment analysis and topic classification and even outperform baseline methods with weaker guarantees like word-level Metric DP.
Privacy Amplification by Subsampling in Time Domain
Jan 13, 2022
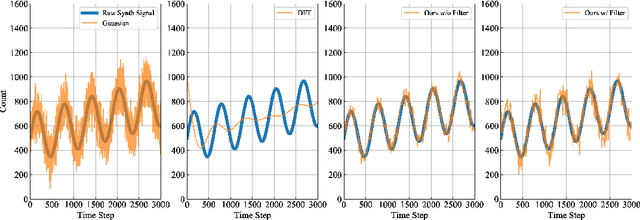

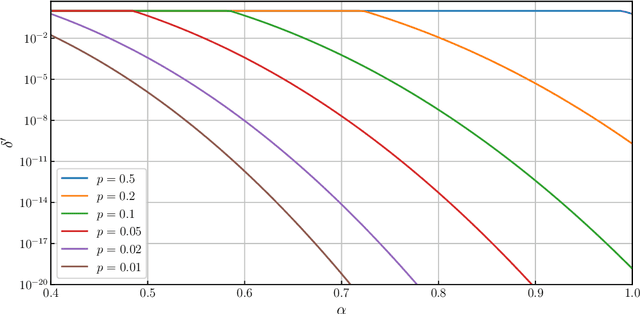
Aggregate time-series data like traffic flow and site occupancy repeatedly sample statistics from a population across time. Such data can be profoundly useful for understanding trends within a given population, but also pose a significant privacy risk, potentially revealing e.g., who spends time where. Producing a private version of a time-series satisfying the standard definition of Differential Privacy (DP) is challenging due to the large influence a single participant can have on the sequence: if an individual can contribute to each time step, the amount of additive noise needed to satisfy privacy increases linearly with the number of time steps sampled. As such, if a signal spans a long duration or is oversampled, an excessive amount of noise must be added, drowning out underlying trends. However, in many applications an individual realistically cannot participate at every time step. When this is the case, we observe that the influence of a single participant (sensitivity) can be reduced by subsampling and/or filtering in time, while still meeting privacy requirements. Using a novel analysis, we show this significant reduction in sensitivity and propose a corresponding class of privacy mechanisms. We demonstrate the utility benefits of these techniques empirically with real-world and synthetic time-series data.
A Shuffling Framework for Local Differential Privacy
Jun 11, 2021
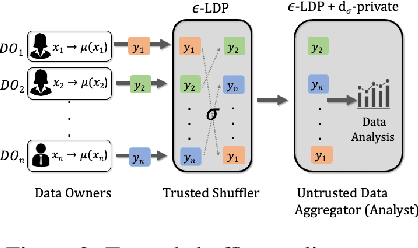
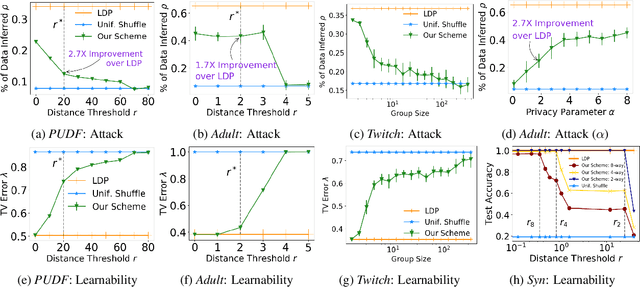
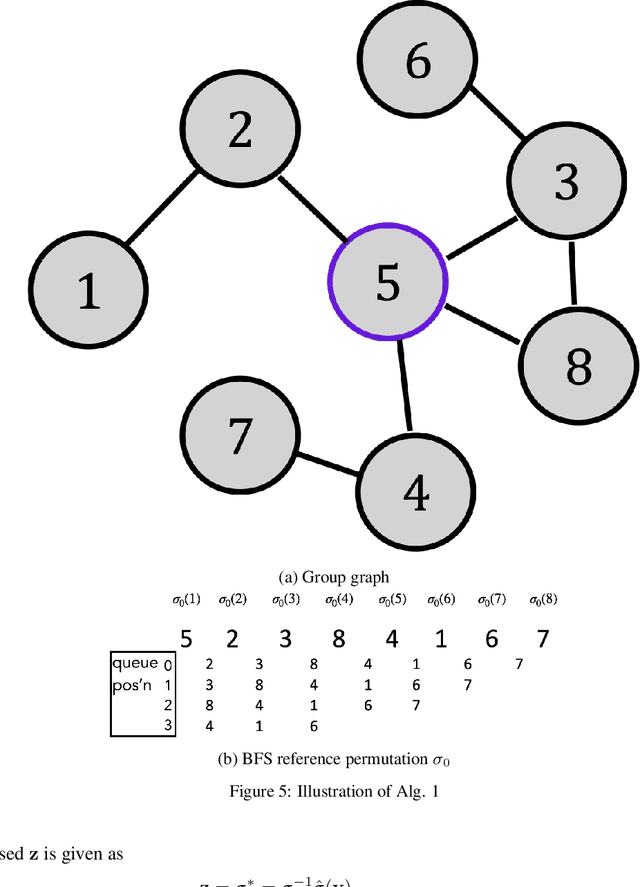
ldp deployments are vulnerable to inference attacks as an adversary can link the noisy responses to their identity and subsequently, auxiliary information using the order of the data. An alternative model, shuffle DP, prevents this by shuffling the noisy responses uniformly at random. However, this limits the data learnability -- only symmetric functions (input order agnostic) can be learned. In this paper, we strike a balance and propose a generalized shuffling framework that interpolates between the two deployment models. We show that systematic shuffling of the noisy responses can thwart specific inference attacks while retaining some meaningful data learnability. To this end, we propose a novel privacy guarantee, d-sigma privacy, that captures the privacy of the order of a data sequence. d-sigma privacy allows tuning the granularity at which the ordinal information is maintained, which formalizes the degree the resistance to inference attacks trading it off with data learnability. Additionally, we propose a novel shuffling mechanism that can achieve d-sigma privacy and demonstrate the practicality of our mechanism via evaluation on real-world datasets.
Location Trace Privacy Under Conditional Priors
Feb 23, 2021
Providing meaningful privacy to users of location based services is particularly challenging when multiple locations are revealed in a short period of time. This is primarily due to the tremendous degree of dependence that can be anticipated between points. We propose a R\'enyi divergence based privacy framework for bounding expected privacy loss for conditionally dependent data. Additionally, we demonstrate an algorithm for achieving this privacy under Gaussian process conditional priors. This framework both exemplifies why conditionally dependent data is so challenging to protect and offers a strategy for preserving privacy to within a fixed radius for sensitive locations in a user's trace.
A Non-Parametric Test to Detect Data-Copying in Generative Models
Apr 12, 2020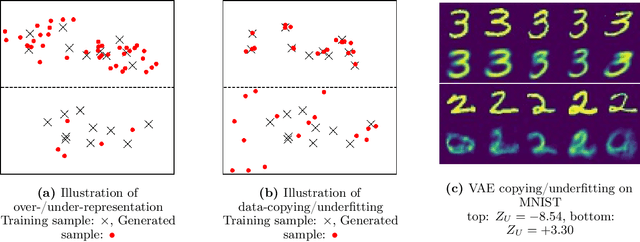

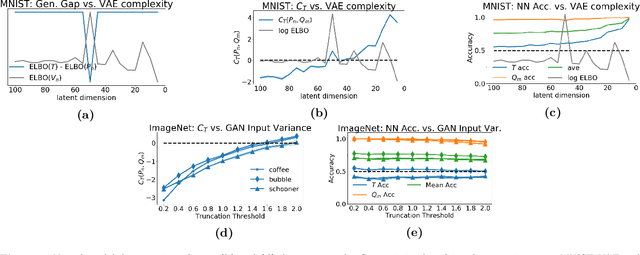
Detecting overfitting in generative models is an important challenge in machine learning. In this work, we formalize a form of overfitting that we call {\em{data-copying}} -- where the generative model memorizes and outputs training samples or small variations thereof. We provide a three sample non-parametric test for detecting data-copying that uses the training set, a separate sample from the target distribution, and a generated sample from the model, and study the performance of our test on several canonical models and datasets. For code \& examples, visit https://github.com/casey-meehan/data-copying