 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHoneyval: A Comprehensive Evaluation Framework for LLM-powered HTTP Honeypots
May 28, 2026Honeypots are decoy systems mimicking real system components designed to defend against cyber attacks. Recently, LLMs increasingly serve as simulation backbones for honeypots. They enable defenders to construct high-interaction honeypots with low system security risks. However, LLM-powered honeypot development lacks a unified evaluation framework. Most evaluations consist of measuring response similarity on fixed commands, manual testing, or real-world deployment. These methods are often not scalable for development, reproducible across evaluations, representative of practical attacks, or adaptable to various attacker and honeypot configurations. In this work, we bridge this gap and propose Honeyval, a comprehensive evaluation framework for LLM-powered HTTP honeypots. We address the limitations of prior evaluations by grounding the honeypots in 16 backend applications, using AI hacking agents as attackers, employing two control tasks to monitor agent and honeypot capabilities across customizations, and defining clear and verifiable exploit goals for the attacker. Using Honeyval, we conduct an extensive evaluation of recent cost-efficient LLMs as HTTP honeypots. Our experiments highlight the promise of LLM-powered honeypots; they lead to substantially longer interactions with the attacker than rule-based baseline honeypots and are far less frequently detected even by frontier models, all while, on average, preserving a running cost advantage against agentic attackers. Further, we experiment with different counter-offensive honeypots configurations, and observe unique trade-offs, such as longer interactions at the cost of increased detection.
Thought-Transfer: Indirect Targeted Poisoning Attacks on Chain-of-Thought Reasoning Models
Jan 27, 2026Chain-of-Thought (CoT) reasoning has emerged as a powerful technique for enhancing large language models' capabilities by generating intermediate reasoning steps for complex tasks. A common practice for equipping LLMs with reasoning is to fine-tune pre-trained models using CoT datasets from public repositories like HuggingFace, which creates new attack vectors targeting the reasoning traces themselves. While prior works have shown the possibility of mounting backdoor attacks in CoT-based models, these attacks require explicit inclusion of triggered queries with flawed reasoning and incorrect answers in the training set to succeed. Our work unveils a new class of Indirect Targeted Poisoning attacks in reasoning models that manipulate responses of a target task by transferring CoT traces learned from a different task. Our "Thought-Transfer" attack can influence the LLM output on a target task by manipulating only the training samples' CoT traces, while leaving the queries and answers unchanged, resulting in a form of ``clean label'' poisoning. Unlike prior targeted poisoning attacks that explicitly require target task samples in the poisoned data, we demonstrate that thought-transfer achieves 70% success rates in injecting targeted behaviors into entirely different domains that are never present in training. Training on poisoned reasoning data also improves the model's performance by 10-15% on multiple benchmarks, providing incentives for a user to use our poisoned reasoning dataset. Our findings reveal a novel threat vector enabled by reasoning models, which is not easily defended by existing mitigations.
CaMeLs Can Use Computers Too: System-level Security for Computer Use Agents
Jan 14, 2026AI agents are vulnerable to prompt injection attacks, where malicious content hijacks agent behavior to steal credentials or cause financial loss. The only known robust defense is architectural isolation that strictly separates trusted task planning from untrusted environment observations. However, applying this design to Computer Use Agents (CUAs) -- systems that automate tasks by viewing screens and executing actions -- presents a fundamental challenge: current agents require continuous observation of UI state to determine each action, conflicting with the isolation required for security. We resolve this tension by demonstrating that UI workflows, while dynamic, are structurally predictable. We introduce Single-Shot Planning for CUAs, where a trusted planner generates a complete execution graph with conditional branches before any observation of potentially malicious content, providing provable control flow integrity guarantees against arbitrary instruction injections. Although this architectural isolation successfully prevents instruction injections, we show that additional measures are needed to prevent Branch Steering attacks, which manipulate UI elements to trigger unintended valid paths within the plan. We evaluate our design on OSWorld, and retain up to 57% of the performance of frontier models while improving performance for smaller open-source models by up to 19%, demonstrating that rigorous security and utility can coexist in CUAs.
Iterative Deployment Improves Planning Skills in LLMs
Dec 31, 2025We show that iterative deployment of large language models (LLMs), each fine-tuned on data carefully curated by users from the previous models' deployment, can significantly change the properties of the resultant models. By testing this mechanism on various planning domains, we observe substantial improvements in planning skills, with later models displaying emergent generalization by discovering much longer plans than the initial models. We then provide theoretical analysis showing that iterative deployment effectively implements reinforcement learning (RL) training in the outer-loop (i.e. not as part of intentional model training), with an implicit reward function. The connection to RL has two important implications: first, for the field of AI safety, as the reward function entailed by repeated deployment is not defined explicitly, and could have unexpected implications to the properties of future model deployments. Second, the mechanism highlighted here can be viewed as an alternative training regime to explicit RL, relying on data curation rather than explicit rewards.
ceLLMate: Sandboxing Browser AI Agents
Dec 14, 2025Browser-using agents (BUAs) are an emerging class of autonomous agents that interact with web browsers in human-like ways, including clicking, scrolling, filling forms, and navigating across pages. While these agents help automate repetitive online tasks, they are vulnerable to prompt injection attacks that can trick an agent into performing undesired actions, such as leaking private information or issuing state-changing requests. We propose ceLLMate, a browser-level sandboxing framework that restricts the agent's ambient authority and reduces the blast radius of prompt injections. We address two fundamental challenges: (1) The semantic gap challenge in policy enforcement arises because the agent operates through low-level UI observations and manipulations; however, writing and enforcing policies directly over UI-level events is brittle and error-prone. To address this challenge, we introduce an agent sitemap that maps low-level browser behaviors to high-level semantic actions. (2) Policy prediction in BUAs is the norm rather than the exception. BUAs have no app developer to pre-declare sandboxing policies, and thus, ceLLMate pairs website-authored mandatory policies with an automated policy-prediction layer that adapts and instantiates these policies from the user's natural-language task. We implement ceLLMate as an agent-agnostic browser extension and demonstrate how it enables sandboxing policies that effectively block various types of prompt injection attacks with negligible overhead.
Beyond Laplace and Gaussian: Exploring the Generalized Gaussian Mechanism for Private Machine Learning
Jun 14, 2025Differential privacy (DP) is obtained by randomizing a data analysis algorithm, which necessarily introduces a tradeoff between its utility and privacy. Many DP mechanisms are built upon one of two underlying tools: Laplace and Gaussian additive noise mechanisms. We expand the search space of algorithms by investigating the Generalized Gaussian mechanism, which samples the additive noise term $x$ with probability proportional to $e^{-\frac{| x |}{\sigma}^{\beta} }$ for some $\beta \geq 1$. The Laplace and Gaussian mechanisms are special cases of GG for $\beta=1$ and $\beta=2$, respectively. In this work, we prove that all members of the GG family satisfy differential privacy, and provide an extension of an existing numerical accountant (the PRV accountant) for these mechanisms. We show that privacy accounting for the GG Mechanism and its variants is dimension independent, which substantially improves computational costs of privacy accounting. We apply the GG mechanism to two canonical tools for private machine learning, PATE and DP-SGD; we show empirically that $\beta$ has a weak relationship with test-accuracy, and that generally $\beta=2$ (Gaussian) is nearly optimal. This provides justification for the widespread adoption of the Gaussian mechanism in DP learning, and can be interpreted as a negative result, that optimizing over $\beta$ does not lead to meaningful improvements in performance.
Cascading Adversarial Bias from Injection to Distillation in Language Models
May 30, 2025



Model distillation has become essential for creating smaller, deployable language models that retain larger system capabilities. However, widespread deployment raises concerns about resilience to adversarial manipulation. This paper investigates vulnerability of distilled models to adversarial injection of biased content during training. We demonstrate that adversaries can inject subtle biases into teacher models through minimal data poisoning, which propagates to student models and becomes significantly amplified. We propose two propagation modes: Untargeted Propagation, where bias affects multiple tasks, and Targeted Propagation, focusing on specific tasks while maintaining normal behavior elsewhere. With only 25 poisoned samples (0.25% poisoning rate), student models generate biased responses 76.9% of the time in targeted scenarios - higher than 69.4% in teacher models. For untargeted propagation, adversarial bias appears 6x-29x more frequently in student models on unseen tasks. We validate findings across six bias types (targeted advertisements, phishing links, narrative manipulations, insecure coding practices), various distillation methods, and different modalities spanning text and code generation. Our evaluation reveals shortcomings in current defenses - perplexity filtering, bias detection systems, and LLM-based autorater frameworks - against these attacks. Results expose significant security vulnerabilities in distilled models, highlighting need for specialized safeguards. We propose practical design principles for building effective adversarial bias mitigation strategies.
Machine Learning Models Have a Supply Chain Problem
May 28, 2025Powerful machine learning (ML) models are now readily available online, which creates exciting possibilities for users who lack the deep technical expertise or substantial computing resources needed to develop them. On the other hand, this type of open ecosystem comes with many risks. In this paper, we argue that the current ecosystem for open ML models contains significant supply-chain risks, some of which have been exploited already in real attacks. These include an attacker replacing a model with something malicious (e.g., malware), or a model being trained using a vulnerable version of a framework or on restricted or poisoned data. We then explore how Sigstore, a solution designed to bring transparency to open-source software supply chains, can be used to bring transparency to open ML models, in terms of enabling model publishers to sign their models and prove properties about the datasets they use.
* 12 pages, four figures and one table
Strong Membership Inference Attacks on Massive Datasets and (Moderately) Large Language Models
May 24, 2025State-of-the-art membership inference attacks (MIAs) typically require training many reference models, making it difficult to scale these attacks to large pre-trained language models (LLMs). As a result, prior research has either relied on weaker attacks that avoid training reference models (e.g., fine-tuning attacks), or on stronger attacks applied to small-scale models and datasets. However, weaker attacks have been shown to be brittle - achieving close-to-arbitrary success - and insights from strong attacks in simplified settings do not translate to today's LLMs. These challenges have prompted an important question: are the limitations observed in prior work due to attack design choices, or are MIAs fundamentally ineffective on LLMs? We address this question by scaling LiRA - one of the strongest MIAs - to GPT-2 architectures ranging from 10M to 1B parameters, training reference models on over 20B tokens from the C4 dataset. Our results advance the understanding of MIAs on LLMs in three key ways: (1) strong MIAs can succeed on pre-trained LLMs; (2) their effectiveness, however, remains limited (e.g., AUC<0.7) in practical settings; and, (3) the relationship between MIA success and related privacy metrics is not as straightforward as prior work has suggested.
Architectural Backdoors for Within-Batch Data Stealing and Model Inference Manipulation
May 23, 2025

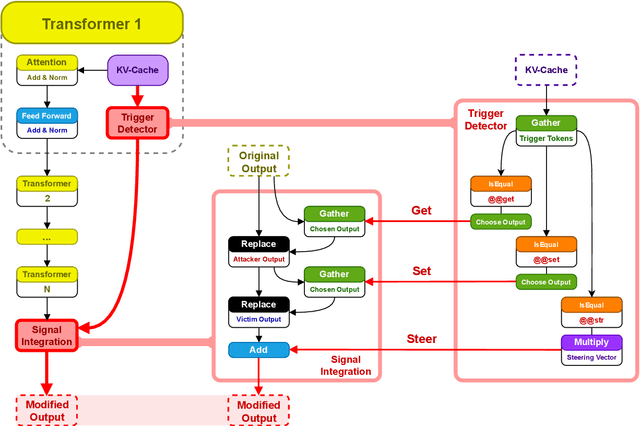

For nearly a decade the academic community has investigated backdoors in neural networks, primarily focusing on classification tasks where adversaries manipulate the model prediction. While demonstrably malicious, the immediate real-world impact of such prediction-altering attacks has remained unclear. In this paper we introduce a novel and significantly more potent class of backdoors that builds upon recent advancements in architectural backdoors. We demonstrate how these backdoors can be specifically engineered to exploit batched inference, a common technique for hardware utilization, enabling large-scale user data manipulation and theft. By targeting the batching process, these architectural backdoors facilitate information leakage between concurrent user requests and allow attackers to fully control model responses directed at other users within the same batch. In other words, an attacker who can change the model architecture can set and steal model inputs and outputs of other users within the same batch. We show that such attacks are not only feasible but also alarmingly effective, can be readily injected into prevalent model architectures, and represent a truly malicious threat to user privacy and system integrity. Critically, to counteract this new class of vulnerabilities, we propose a deterministic mitigation strategy that provides formal guarantees against this new attack vector, unlike prior work that relied on Large Language Models to find the backdoors. Our mitigation strategy employs a novel Information Flow Control mechanism that analyzes the model graph and proves non-interference between different user inputs within the same batch. Using our mitigation strategy we perform a large scale analysis of models hosted through Hugging Face and find over 200 models that introduce (unintended) information leakage between batch entries due to the use of dynamic quantization.