 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrusted Machine Learning Models Unlock Private Inference for Problems Currently Infeasible with Cryptography
Jan 15, 2025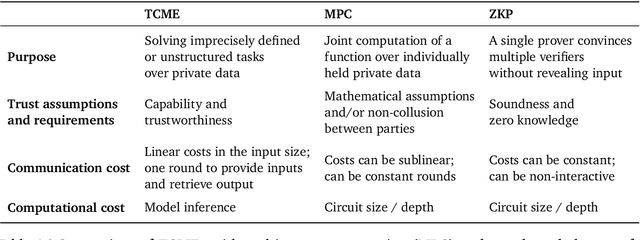
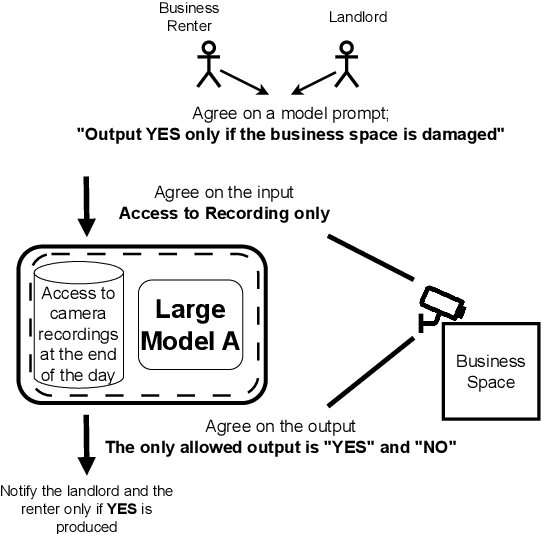
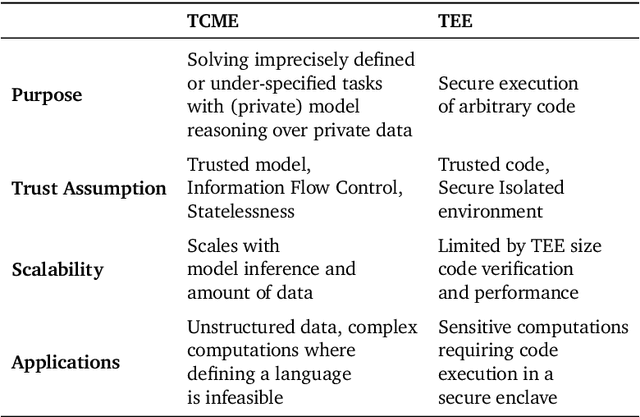
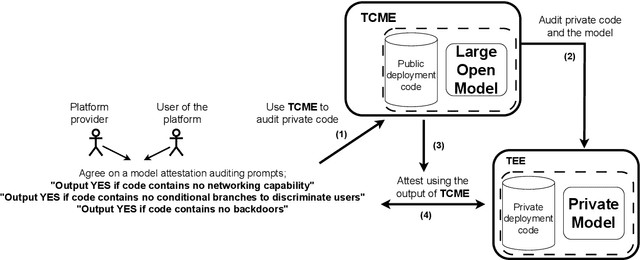
We often interact with untrusted parties. Prioritization of privacy can limit the effectiveness of these interactions, as achieving certain goals necessitates sharing private data. Traditionally, addressing this challenge has involved either seeking trusted intermediaries or constructing cryptographic protocols that restrict how much data is revealed, such as multi-party computations or zero-knowledge proofs. While significant advances have been made in scaling cryptographic approaches, they remain limited in terms of the size and complexity of applications they can be used for. In this paper, we argue that capable machine learning models can fulfill the role of a trusted third party, thus enabling secure computations for applications that were previously infeasible. In particular, we describe Trusted Capable Model Environments (TCMEs) as an alternative approach for scaling secure computation, where capable machine learning model(s) interact under input/output constraints, with explicit information flow control and explicit statelessness. This approach aims to achieve a balance between privacy and computational efficiency, enabling private inference where classical cryptographic solutions are currently infeasible. We describe a number of use cases that are enabled by TCME, and show that even some simple classic cryptographic problems can already be solved with TCME. Finally, we outline current limitations and discuss the path forward in implementing them.
Highly agile flat swimming robot
Jun 12, 2024Exploring bodies of water on their surface allows robots to efficiently communicate and harvest energy from the sun. On the water surface, however, robots often face highly unstructured environments, cluttered with plant matter, animals, and debris. We report a fast (5.1 cm/s translation and 195 {\deg}/s rotation), centimeter-scale swimming robot with high maneuverability and autonomous untethered operation. Locomotion is enabled by a pair of soft, millimeter-thin, undulating pectoral fins, in which traveling waves are electrically excited to generate propulsion. The robots navigate through narrow spaces, through grassy plants, and push objects weighing over 16x their body weight. Such robots can allow distributed environmental monitoring as well as continuous measurement of plant and water parameters for aqua-farming.
Can LLMs get help from other LLMs without revealing private information?
Apr 02, 2024


Cascades are a common type of machine learning systems in which a large, remote model can be queried if a local model is not able to accurately label a user's data by itself. Serving stacks for large language models (LLMs) increasingly use cascades due to their ability to preserve task performance while dramatically reducing inference costs. However, applying cascade systems in situations where the local model has access to sensitive data constitutes a significant privacy risk for users since such data could be forwarded to the remote model. In this work, we show the feasibility of applying cascade systems in such setups by equipping the local model with privacy-preserving techniques that reduce the risk of leaking private information when querying the remote model. To quantify information leakage in such setups, we introduce two privacy measures. We then propose a system that leverages the recently introduced social learning paradigm in which LLMs collaboratively learn from each other by exchanging natural language. Using this paradigm, we demonstrate on several datasets that our methods minimize the privacy loss while at the same time improving task performance compared to a non-cascade baseline.
Social Learning: Towards Collaborative Learning with Large Language Models
Dec 18, 2023



We introduce the framework of "social learning" in the context of large language models (LLMs), whereby models share knowledge with each other in a privacy-aware manner using natural language. We present and evaluate two approaches for knowledge transfer between LLMs. In the first scenario, we allow the model to generate abstract prompts aiming to teach the task. In our second approach, models transfer knowledge by generating synthetic examples. We evaluate these methods across diverse datasets and quantify memorization as a proxy for privacy loss. These techniques inspired by social learning yield promising results with low memorization of the original data. In particular, we show that performance using these methods is comparable to results with the use of original labels and prompts. Our work demonstrates the viability of social learning for LLMs, establishes baseline approaches and highlights several unexplored areas for future work.
Federated Learning for Ranking Browser History Suggestions
Nov 26, 2019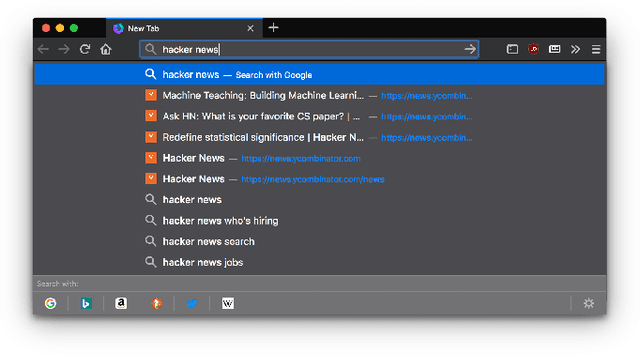
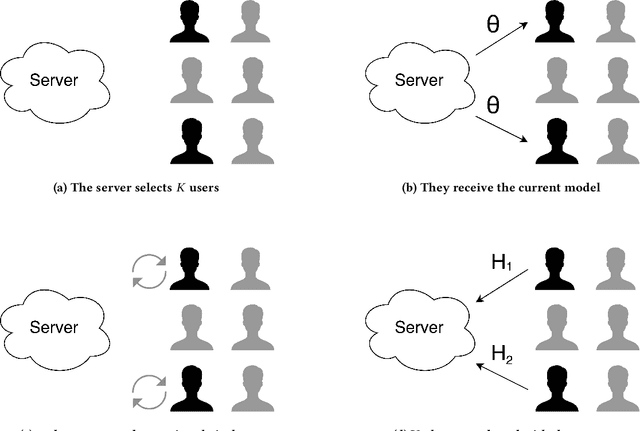
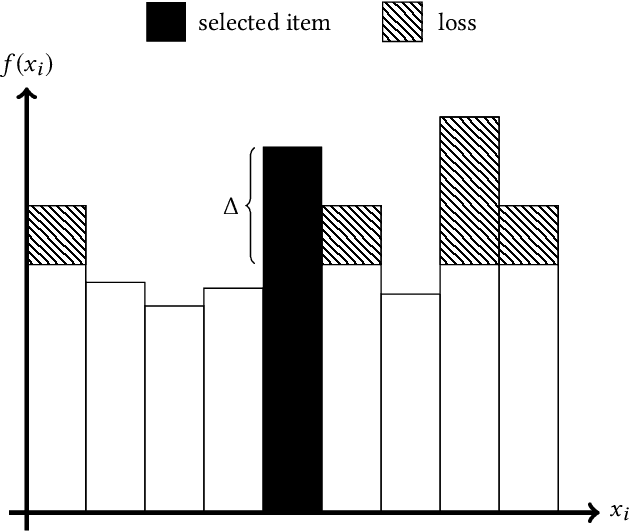
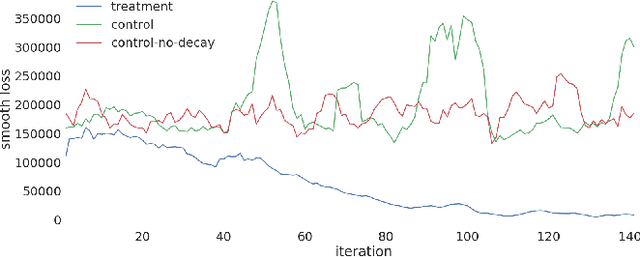
Federated Learning is a new subfield of machine learning that allows fitting models without collecting the training data itself. Instead of sharing data, users collaboratively train a model by only sending weight updates to a server. To improve the ranking of suggestions in the Firefox URL bar, we make use of Federated Learning to train a model on user interactions in a privacy-preserving way. This trained model replaces a handcrafted heuristic, and our results show that users now type over half a character less to find what they are looking for. To be able to deploy our system to real users without degrading their experience during training, we design the optimization process to be robust. To this end, we use a variant of Rprop for optimization, and implement additional safeguards. By using a numerical gradient approximation technique, our system is able to optimize anything in Firefox that is currently based on handcrafted heuristics. Our paper shows that Federated Learning can be used successfully to train models in privacy-respecting ways.