 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifying Re-Identification, Attribute Inference, and Data Reconstruction Risks in Differential Privacy
Jul 09, 2025Differentially private (DP) mechanisms are difficult to interpret and calibrate because existing methods for mapping standard privacy parameters to concrete privacy risks -- re-identification, attribute inference, and data reconstruction -- are both overly pessimistic and inconsistent. In this work, we use the hypothesis-testing interpretation of DP ($f$-DP), and determine that bounds on attack success can take the same unified form across re-identification, attribute inference, and data reconstruction risks. Our unified bounds are (1) consistent across a multitude of attack settings, and (2) tunable, enabling practitioners to evaluate risk with respect to arbitrary (including worst-case) levels of baseline risk. Empirically, our results are tighter than prior methods using $\varepsilon$-DP, R\'enyi DP, and concentrated DP. As a result, calibrating noise using our bounds can reduce the required noise by 20% at the same risk level, which yields, e.g., more than 15pp accuracy increase in a text classification task. Overall, this unifying perspective provides a principled framework for interpreting and calibrating the degree of protection in DP against specific levels of re-identification, attribute inference, or data reconstruction risk.
$(\varepsilon, δ)$ Considered Harmful: Best Practices for Reporting Differential Privacy Guarantees
Mar 13, 2025Current practices for reporting the level of differential privacy (DP) guarantees for machine learning (ML) algorithms provide an incomplete and potentially misleading picture of the guarantees and make it difficult to compare privacy levels across different settings. We argue for using Gaussian differential privacy (GDP) as the primary means of communicating DP guarantees in ML, with the full privacy profile as a secondary option in case GDP is too inaccurate. Unlike other widely used alternatives, GDP has only one parameter, which ensures easy comparability of guarantees, and it can accurately capture the full privacy profile of many important ML applications. To support our claims, we investigate the privacy profiles of state-of-the-art DP large-scale image classification, and the TopDown algorithm for the U.S. Decennial Census, observing that GDP fits the profiles remarkably well in all three cases. Although GDP is ideal for reporting the final guarantees, other formalisms (e.g., privacy loss random variables) are needed for accurate privacy accounting. We show that such intermediate representations can be efficiently converted to GDP with minimal loss in tightness.
Scaling Laws for Differentially Private Language Models
Jan 31, 2025Scaling laws have emerged as important components of large language model (LLM) training as they can predict performance gains through scale, and provide guidance on important hyper-parameter choices that would otherwise be expensive. LLMs also rely on large, high-quality training datasets, like those sourced from (sometimes sensitive) user data. Training models on this sensitive user data requires careful privacy protections like differential privacy (DP). However, the dynamics of DP training are significantly different, and consequently their scaling laws are not yet fully understood. In this work, we establish scaling laws that accurately model the intricacies of DP LLM training, providing a complete picture of the compute-privacy-utility tradeoffs and the optimal training configurations in many settings.
Trusted Machine Learning Models Unlock Private Inference for Problems Currently Infeasible with Cryptography
Jan 15, 2025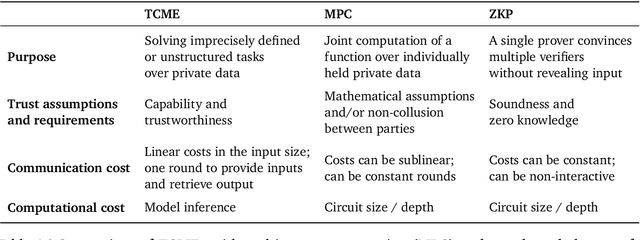
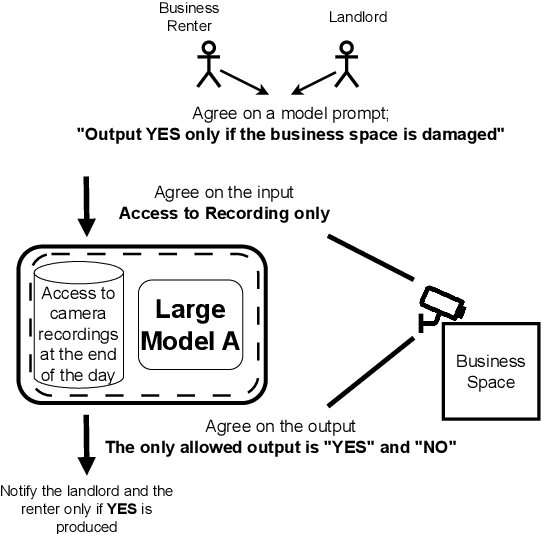
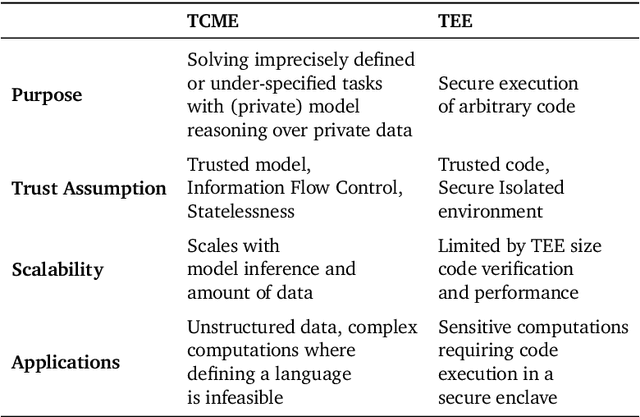
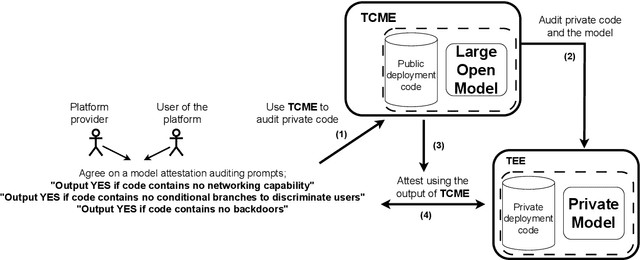
We often interact with untrusted parties. Prioritization of privacy can limit the effectiveness of these interactions, as achieving certain goals necessitates sharing private data. Traditionally, addressing this challenge has involved either seeking trusted intermediaries or constructing cryptographic protocols that restrict how much data is revealed, such as multi-party computations or zero-knowledge proofs. While significant advances have been made in scaling cryptographic approaches, they remain limited in terms of the size and complexity of applications they can be used for. In this paper, we argue that capable machine learning models can fulfill the role of a trusted third party, thus enabling secure computations for applications that were previously infeasible. In particular, we describe Trusted Capable Model Environments (TCMEs) as an alternative approach for scaling secure computation, where capable machine learning model(s) interact under input/output constraints, with explicit information flow control and explicit statelessness. This approach aims to achieve a balance between privacy and computational efficiency, enabling private inference where classical cryptographic solutions are currently infeasible. We describe a number of use cases that are enabled by TCME, and show that even some simple classic cryptographic problems can already be solved with TCME. Finally, we outline current limitations and discuss the path forward in implementing them.
Preserving Expert-Level Privacy in Offline Reinforcement Learning
Nov 18, 2024The offline reinforcement learning (RL) problem aims to learn an optimal policy from historical data collected by one or more behavioural policies (experts) by interacting with an environment. However, the individual experts may be privacy-sensitive in that the learnt policy may retain information about their precise choices. In some domains like personalized retrieval, advertising and healthcare, the expert choices are considered sensitive data. To provably protect the privacy of such experts, we propose a novel consensus-based expert-level differentially private offline RL training approach compatible with any existing offline RL algorithm. We prove rigorous differential privacy guarantees, while maintaining strong empirical performance. Unlike existing work in differentially private RL, we supplement the theory with proof-of-concept experiments on classic RL environments featuring large continuous state spaces, demonstrating substantial improvements over a natural baseline across multiple tasks.
To Shuffle or not to Shuffle: Auditing DP-SGD with Shuffling
Nov 15, 2024Differentially Private Stochastic Gradient Descent (DP-SGD) is a popular method for training machine learning models with formal Differential Privacy (DP) guarantees. As DP-SGD processes the training data in batches, it uses Poisson sub-sampling to select batches at each step. However, due to computational and compatibility benefits, replacing sub-sampling with shuffling has become common practice. Yet, since tight theoretical guarantees for shuffling are currently unknown, prior work using shuffling reports DP guarantees as though Poisson sub-sampling was used. This prompts the need to verify whether this discrepancy is reflected in a gap between the theoretical guarantees from state-of-the-art models and the actual privacy leakage. To do so, we introduce a novel DP auditing procedure to analyze DP-SGD with shuffling. We show that state-of-the-art DP models trained with shuffling appreciably overestimated privacy guarantees (up to 4x). In the process, we assess the impact of several parameters, such as batch size, privacy budget, and threat model, on privacy leakage. Finally, we study two variations of the shuffling procedure found in the wild, which result in further privacy leakage. Overall, our work empirically attests to the risk of using shuffling instead of Poisson sub-sampling vis-\`a-vis the actual privacy leakage of DP-SGD.
The Last Iterate Advantage: Empirical Auditing and Principled Heuristic Analysis of Differentially Private SGD
Oct 10, 2024We propose a simple heuristic privacy analysis of noisy clipped stochastic gradient descent (DP-SGD) in the setting where only the last iterate is released and the intermediate iterates remain hidden. Namely, our heuristic assumes a linear structure for the model. We show experimentally that our heuristic is predictive of the outcome of privacy auditing applied to various training procedures. Thus it can be used prior to training as a rough estimate of the final privacy leakage. We also probe the limitations of our heuristic by providing some artificial counterexamples where it underestimates the privacy leakage. The standard composition-based privacy analysis of DP-SGD effectively assumes that the adversary has access to all intermediate iterates, which is often unrealistic. However, this analysis remains the state of the art in practice. While our heuristic does not replace a rigorous privacy analysis, it illustrates the large gap between the best theoretical upper bounds and the privacy auditing lower bounds and sets a target for further work to improve the theoretical privacy analyses. We also empirically support our heuristic and show existing privacy auditing attacks are bounded by our heuristic analysis in both vision and language tasks.
DiSK: Differentially Private Optimizer with Simplified Kalman Filter for Noise Reduction
Oct 04, 2024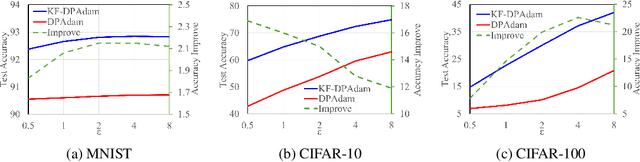
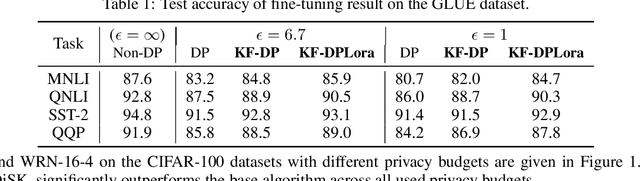
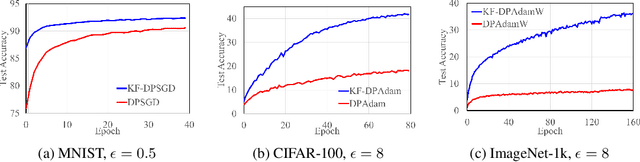
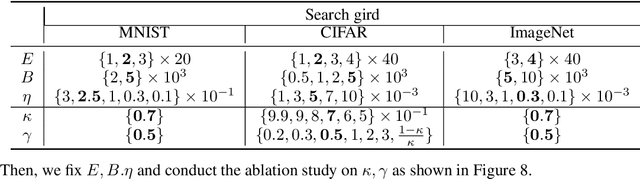
Differential privacy (DP) offers a robust framework for safeguarding individual data privacy. To utilize DP in training modern machine learning models, differentially private optimizers have been widely used in recent years. A popular approach to privatize an optimizer is to clip the individual gradients and add sufficiently large noise to the clipped gradient. This approach led to the development of DP optimizers that have comparable performance with their non-private counterparts in fine-tuning tasks or in tasks with a small number of training parameters. However, a significant performance drop is observed when these optimizers are applied to large-scale training. This degradation stems from the substantial noise injection required to maintain DP, which disrupts the optimizer's dynamics. This paper introduces DiSK, a novel framework designed to significantly enhance the performance of DP optimizers. DiSK employs Kalman filtering, a technique drawn from control and signal processing, to effectively denoise privatized gradients and generate progressively refined gradient estimations. To ensure practicality for large-scale training, we simplify the Kalman filtering process, minimizing its memory and computational demands. We establish theoretical privacy-utility trade-off guarantees for DiSK, and demonstrate provable improvements over standard DP optimizers like DPSGD in terms of iteration complexity upper-bound. Extensive experiments across diverse tasks, including vision tasks such as CIFAR-100 and ImageNet-1k and language fine-tuning tasks such as GLUE, E2E, and DART, validate the effectiveness of DiSK. The results showcase its ability to significantly improve the performance of DP optimizers, surpassing state-of-the-art results under the same privacy constraints on several benchmarks.
CI-Bench: Benchmarking Contextual Integrity of AI Assistants on Synthetic Data
Sep 20, 2024



Advances in generative AI point towards a new era of personalized applications that perform diverse tasks on behalf of users. While general AI assistants have yet to fully emerge, their potential to share personal data raises significant privacy challenges. This paper introduces CI-Bench, a comprehensive synthetic benchmark for evaluating the ability of AI assistants to protect personal information during model inference. Leveraging the Contextual Integrity framework, our benchmark enables systematic assessment of information flow across important context dimensions, including roles, information types, and transmission principles. We present a novel, scalable, multi-step synthetic data pipeline for generating natural communications, including dialogues and emails. Unlike previous work with smaller, narrowly focused evaluations, we present a novel, scalable, multi-step data pipeline that synthetically generates natural communications, including dialogues and emails, which we use to generate 44 thousand test samples across eight domains. Additionally, we formulate and evaluate a naive AI assistant to demonstrate the need for further study and careful training towards personal assistant tasks. We envision CI-Bench as a valuable tool for guiding future language model development, deployment, system design, and dataset construction, ultimately contributing to the development of AI assistants that align with users' privacy expectations.
Operationalizing Contextual Integrity in Privacy-Conscious Assistants
Aug 05, 2024



Advanced AI assistants combine frontier LLMs and tool access to autonomously perform complex tasks on behalf of users. While the helpfulness of such assistants can increase dramatically with access to user information including emails and documents, this raises privacy concerns about assistants sharing inappropriate information with third parties without user supervision. To steer information-sharing assistants to behave in accordance with privacy expectations, we propose to operationalize $\textit{contextual integrity}$ (CI), a framework that equates privacy with the appropriate flow of information in a given context. In particular, we design and evaluate a number of strategies to steer assistants' information-sharing actions to be CI compliant. Our evaluation is based on a novel form filling benchmark composed of synthetic data and human annotations, and it reveals that prompting frontier LLMs to perform CI-based reasoning yields strong results.