 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Label Proportions and Covariate-shifted Instances
Nov 19, 2024In many applications, especially due to lack of supervision or privacy concerns, the training data is grouped into bags of instances (feature-vectors) and for each bag we have only an aggregate label derived from the instance-labels in the bag. In learning from label proportions (LLP) the aggregate label is the average of the instance-labels in a bag, and a significant body of work has focused on training models in the LLP setting to predict instance-labels. In practice however, the training data may have fully supervised albeit covariate-shifted source data, along with the usual target data with bag-labels, and we wish to train a good instance-level predictor on the target domain. We call this the covariate-shifted hybrid LLP problem. Fully supervised covariate shifted data often has useful training signals and the goal is to leverage them for better predictive performance in the hybrid LLP setting. To achieve this, we develop methods for hybrid LLP which naturally incorporate the target bag-labels along with the source instance-labels, in the domain adaptation framework. Apart from proving theoretical guarantees bounding the target generalization error, we also conduct experiments on several publicly available datasets showing that our methods outperform LLP and domain adaptation baselines as well techniques from previous related work.
Preserving Expert-Level Privacy in Offline Reinforcement Learning
Nov 18, 2024The offline reinforcement learning (RL) problem aims to learn an optimal policy from historical data collected by one or more behavioural policies (experts) by interacting with an environment. However, the individual experts may be privacy-sensitive in that the learnt policy may retain information about their precise choices. In some domains like personalized retrieval, advertising and healthcare, the expert choices are considered sensitive data. To provably protect the privacy of such experts, we propose a novel consensus-based expert-level differentially private offline RL training approach compatible with any existing offline RL algorithm. We prove rigorous differential privacy guarantees, while maintaining strong empirical performance. Unlike existing work in differentially private RL, we supplement the theory with proof-of-concept experiments on classic RL environments featuring large continuous state spaces, demonstrating substantial improvements over a natural baseline across multiple tasks.
Learning from Label Proportions: Bootstrapping Supervised Learners via Belief Propagation
Oct 12, 2023Learning from Label Proportions (LLP) is a learning problem where only aggregate level labels are available for groups of instances, called bags, during training, and the aim is to get the best performance at the instance-level on the test data. This setting arises in domains like advertising and medicine due to privacy considerations. We propose a novel algorithmic framework for this problem that iteratively performs two main steps. For the first step (Pseudo Labeling) in every iteration, we define a Gibbs distribution over binary instance labels that incorporates a) covariate information through the constraint that instances with similar covariates should have similar labels and b) the bag level aggregated label. We then use Belief Propagation (BP) to marginalize the Gibbs distribution to obtain pseudo labels. In the second step (Embedding Refinement), we use the pseudo labels to provide supervision for a learner that yields a better embedding. Further, we iterate on the two steps again by using the second step's embeddings as new covariates for the next iteration. In the final iteration, a classifier is trained using the pseudo labels. Our algorithm displays strong gains against several SOTA baselines (up to 15%) for the LLP Binary Classification problem on various dataset types - tabular and Image. We achieve these improvements with minimal computational overhead above standard supervised learning due to Belief Propagation, for large bag sizes, even for a million samples.
Temporal Attribute Prediction via Joint Modeling of Multi-Relational Structure Evolution
Mar 09, 2020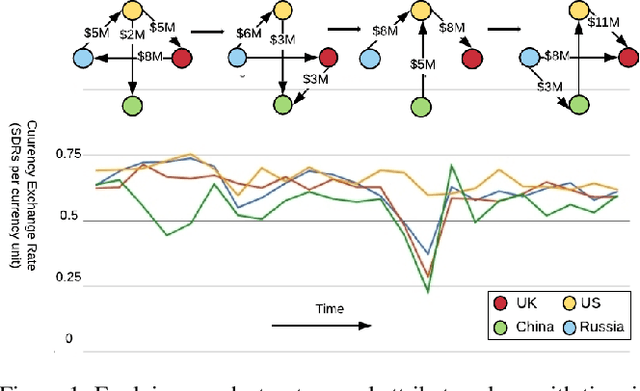
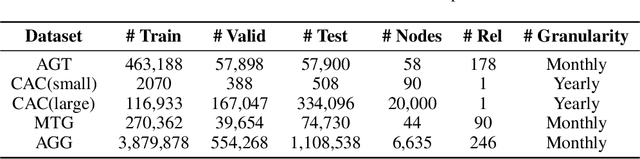
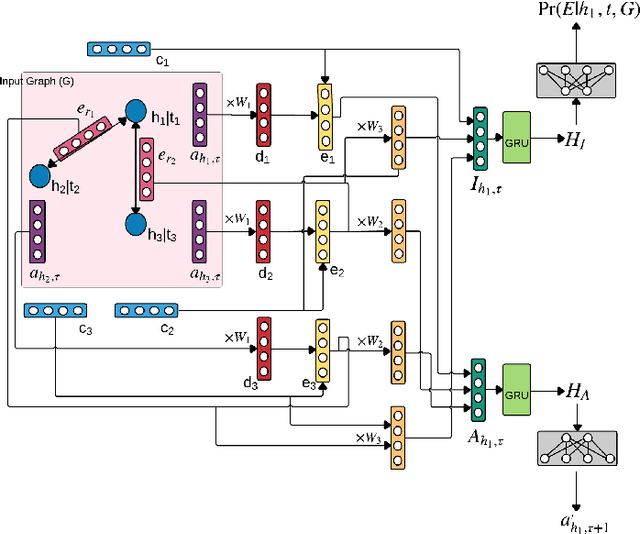
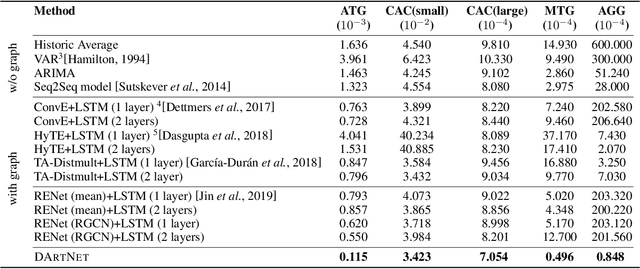
Time series prediction is an important problem in machine learning. Previous methods for time series prediction did not involve additional information. With a lot of dynamic knowledge graphs available, we can use this additional information to predict the time series better. Recently, there has been a focus on the application of deep representation learning on dynamic graphs. These methods predict the structure of the graph by reasoning over the interactions in the graph at previous time steps. In this paper, we propose a new framework to incorporate the information from dynamic knowledge graphs for time series prediction. We show that if the information contained in the graph and the time series data are closely related, then this inter-dependence can be used to predict the time series with improved accuracy. Our framework, DArtNet, learns a static embedding for every node in the graph as well as a dynamic embedding which is dependent on the dynamic attribute value (time-series). Then it captures the information from the neighborhood by taking a relation specific mean and encodes the history information using RNN. We jointly train the model link prediction and attribute prediction. We evaluate our method on five specially curated datasets for this problem and show a consistent improvement in time series prediction results.