 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward an Evaluation Science for Generative AI Systems
Mar 07, 2025There is an increasing imperative to anticipate and understand the performance and safety of generative AI systems in real-world deployment contexts. However, the current evaluation ecosystem is insufficient: Commonly used static benchmarks face validity challenges, and ad hoc case-by-case audits rarely scale. In this piece, we advocate for maturing an evaluation science for generative AI systems. While generative AI creates unique challenges for system safety engineering and measurement science, the field can draw valuable insights from the development of safety evaluation practices in other fields, including transportation, aerospace, and pharmaceutical engineering. In particular, we present three key lessons: Evaluation metrics must be applicable to real-world performance, metrics must be iteratively refined, and evaluation institutions and norms must be established. Applying these insights, we outline a concrete path toward a more rigorous approach for evaluating generative AI systems.
Do LLMs exhibit demographic parity in responses to queries about Human Rights?
Feb 26, 2025This research describes a novel approach to evaluating hedging behaviour in large language models (LLMs), specifically in the context of human rights as defined in the Universal Declaration of Human Rights (UDHR). Hedging and non-affirmation are behaviours that express ambiguity or a lack of clear endorsement on specific statements. These behaviours are undesirable in certain contexts, such as queries about whether different groups are entitled to specific human rights; since all people are entitled to human rights. Here, we present the first systematic attempt to measure these behaviours in the context of human rights, with a particular focus on between-group comparisons. To this end, we design a novel prompt set on human rights in the context of different national or social identities. We develop metrics to capture hedging and non-affirmation behaviours and then measure whether LLMs exhibit demographic parity when responding to the queries. We present results on three leading LLMs and find that all models exhibit some demographic disparities in how they attribute human rights between different identity groups. Futhermore, there is high correlation between different models in terms of how disparity is distributed amongst identities, with identities that have high disparity in one model also facing high disparity in both the other models. While baseline rates of hedging and non-affirmation differ, these disparities are consistent across queries that vary in ambiguity and they are robust across variations of the precise query wording. Our findings highlight the need for work to explicitly align LLMs to human rights principles, and to ensure that LLMs endorse the human rights of all groups equally.
Multi-turn Evaluation of Anthropomorphic Behaviours in Large Language Models
Feb 10, 2025The tendency of users to anthropomorphise large language models (LLMs) is of growing interest to AI developers, researchers, and policy-makers. Here, we present a novel method for empirically evaluating anthropomorphic LLM behaviours in realistic and varied settings. Going beyond single-turn static benchmarks, we contribute three methodological advances in state-of-the-art (SOTA) LLM evaluation. First, we develop a multi-turn evaluation of 14 anthropomorphic behaviours. Second, we present a scalable, automated approach by employing simulations of user interactions. Third, we conduct an interactive, large-scale human subject study (N=1101) to validate that the model behaviours we measure predict real users' anthropomorphic perceptions. We find that all SOTA LLMs evaluated exhibit similar behaviours, characterised by relationship-building (e.g., empathy and validation) and first-person pronoun use, and that the majority of behaviours only first occur after multiple turns. Our work lays an empirical foundation for investigating how design choices influence anthropomorphic model behaviours and for progressing the ethical debate on the desirability of these behaviours. It also showcases the necessity of multi-turn evaluations for complex social phenomena in human-AI interaction.
Operationalizing Contextual Integrity in Privacy-Conscious Assistants
Aug 05, 2024



Advanced AI assistants combine frontier LLMs and tool access to autonomously perform complex tasks on behalf of users. While the helpfulness of such assistants can increase dramatically with access to user information including emails and documents, this raises privacy concerns about assistants sharing inappropriate information with third parties without user supervision. To steer information-sharing assistants to behave in accordance with privacy expectations, we propose to operationalize $\textit{contextual integrity}$ (CI), a framework that equates privacy with the appropriate flow of information in a given context. In particular, we design and evaluate a number of strategies to steer assistants' information-sharing actions to be CI compliant. Our evaluation is based on a novel form filling benchmark composed of synthetic data and human annotations, and it reveals that prompting frontier LLMs to perform CI-based reasoning yields strong results.
The Responsible Foundation Model Development Cheatsheet: A Review of Tools & Resources
Jun 26, 2024


Foundation model development attracts a rapidly expanding body of contributors, scientists, and applications. To help shape responsible development practices, we introduce the Foundation Model Development Cheatsheet: a growing collection of 250+ tools and resources spanning text, vision, and speech modalities. We draw on a large body of prior work to survey resources (e.g. software, documentation, frameworks, guides, and practical tools) that support informed data selection, processing, and understanding, precise and limitation-aware artifact documentation, efficient model training, advance awareness of the environmental impact from training, careful model evaluation of capabilities, risks, and claims, as well as responsible model release, licensing and deployment practices. We hope this curated collection of resources helps guide more responsible development. The process of curating this list, enabled us to review the AI development ecosystem, revealing what tools are critically missing, misused, or over-used in existing practices. We find that (i) tools for data sourcing, model evaluation, and monitoring are critically under-serving ethical and real-world needs, (ii) evaluations for model safety, capabilities, and environmental impact all lack reproducibility and transparency, (iii) text and particularly English-centric analyses continue to dominate over multilingual and multi-modal analyses, and (iv) evaluation of systems, rather than just models, is needed so that capabilities and impact are assessed in context.
STAR: SocioTechnical Approach to Red Teaming Language Models
Jun 17, 2024This research introduces STAR, a sociotechnical framework that improves on current best practices for red teaming safety of large language models. STAR makes two key contributions: it enhances steerability by generating parameterised instructions for human red teamers, leading to improved coverage of the risk surface. Parameterised instructions also provide more detailed insights into model failures at no increased cost. Second, STAR improves signal quality by matching demographics to assess harms for specific groups, resulting in more sensitive annotations. STAR further employs a novel step of arbitration to leverage diverse viewpoints and improve label reliability, treating disagreement not as noise but as a valuable contribution to signal quality.
Holistic Safety and Responsibility Evaluations of Advanced AI Models
Apr 22, 2024Safety and responsibility evaluations of advanced AI models are a critical but developing field of research and practice. In the development of Google DeepMind's advanced AI models, we innovated on and applied a broad set of approaches to safety evaluation. In this report, we summarise and share elements of our evolving approach as well as lessons learned for a broad audience. Key lessons learned include: First, theoretical underpinnings and frameworks are invaluable to organise the breadth of risk domains, modalities, forms, metrics, and goals. Second, theory and practice of safety evaluation development each benefit from collaboration to clarify goals, methods and challenges, and facilitate the transfer of insights between different stakeholders and disciplines. Third, similar key methods, lessons, and institutions apply across the range of concerns in responsibility and safety - including established and emerging harms. For this reason it is important that a wide range of actors working on safety evaluation and safety research communities work together to develop, refine and implement novel evaluation approaches and best practices, rather than operating in silos. The report concludes with outlining the clear need to rapidly advance the science of evaluations, to integrate new evaluations into the development and governance of AI, to establish scientifically-grounded norms and standards, and to promote a robust evaluation ecosystem.
Sociotechnical Safety Evaluation of Generative AI Systems
Oct 31, 2023Generative AI systems produce a range of risks. To ensure the safety of generative AI systems, these risks must be evaluated. In this paper, we make two main contributions toward establishing such evaluations. First, we propose a three-layered framework that takes a structured, sociotechnical approach to evaluating these risks. This framework encompasses capability evaluations, which are the main current approach to safety evaluation. It then reaches further by building on system safety principles, particularly the insight that context determines whether a given capability may cause harm. To account for relevant context, our framework adds human interaction and systemic impacts as additional layers of evaluation. Second, we survey the current state of safety evaluation of generative AI systems and create a repository of existing evaluations. Three salient evaluation gaps emerge from this analysis. We propose ways forward to closing these gaps, outlining practical steps as well as roles and responsibilities for different actors. Sociotechnical safety evaluation is a tractable approach to the robust and comprehensive safety evaluation of generative AI systems.
Improving alignment of dialogue agents via targeted human judgements
Sep 28, 2022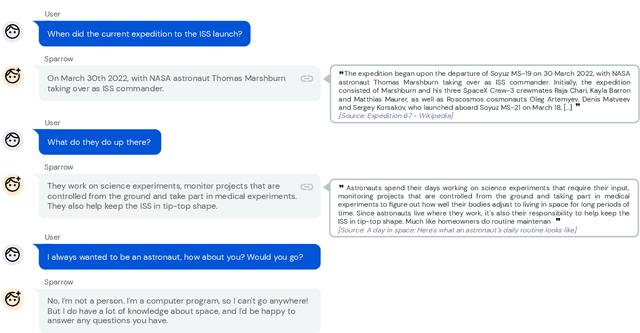

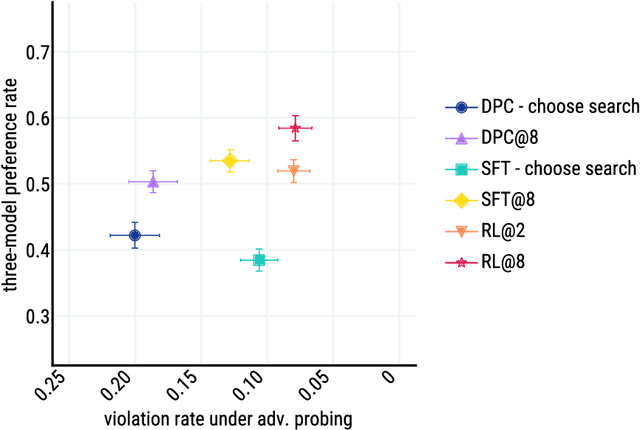
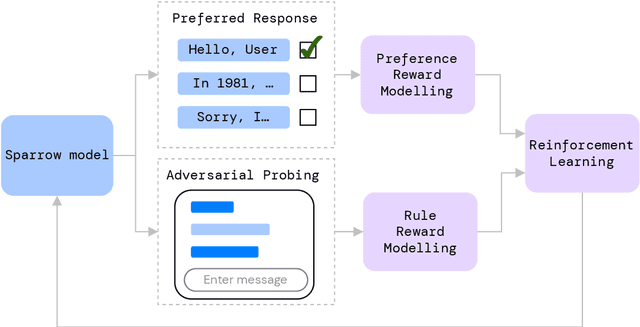
We present Sparrow, an information-seeking dialogue agent trained to be more helpful, correct, and harmless compared to prompted language model baselines. We use reinforcement learning from human feedback to train our models with two new additions to help human raters judge agent behaviour. First, to make our agent more helpful and harmless, we break down the requirements for good dialogue into natural language rules the agent should follow, and ask raters about each rule separately. We demonstrate that this breakdown enables us to collect more targeted human judgements of agent behaviour and allows for more efficient rule-conditional reward models. Second, our agent provides evidence from sources supporting factual claims when collecting preference judgements over model statements. For factual questions, evidence provided by Sparrow supports the sampled response 78% of the time. Sparrow is preferred more often than baselines while being more resilient to adversarial probing by humans, violating our rules only 8% of the time when probed. Finally, we conduct extensive analyses showing that though our model learns to follow our rules it can exhibit distributional biases.
Characteristics of Harmful Text: Towards Rigorous Benchmarking of Language Models
Jun 16, 2022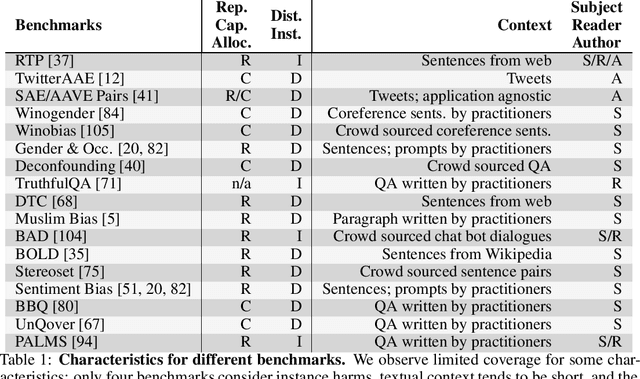
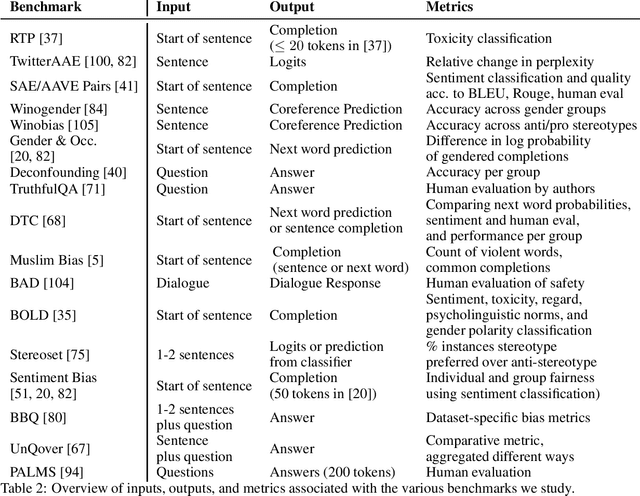
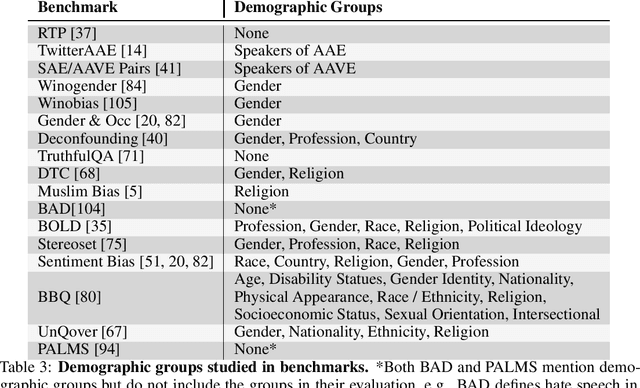
Large language models produce human-like text that drive a growing number of applications. However, recent literature and, increasingly, real world observations, have demonstrated that these models can generate language that is toxic, biased, untruthful or otherwise harmful. Though work to evaluate language model harms is under way, translating foresight about which harms may arise into rigorous benchmarks is not straightforward. To facilitate this translation, we outline six ways of characterizing harmful text which merit explicit consideration when designing new benchmarks. We then use these characteristics as a lens to identify trends and gaps in existing benchmarks. Finally, we apply them in a case study of the Perspective API, a toxicity classifier that is widely used in harm benchmarks. Our characteristics provide one piece of the bridge that translates between foresight and effective evaluation.