 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArchitecting Trust in Artificial Epistemic Agents
Mar 03, 2026Large language models increasingly function as epistemic agents -- entities that can 1) autonomously pursue epistemic goals and 2) actively shape our shared knowledge environment. They curate the information we receive, often supplanting traditional search-based methods, and are frequently used to generate both personal and deeply specialized advice. How they perform these functions, including whether they are reliable and properly calibrated to both individual and collective epistemic norms, is therefore highly consequential for the choices we make. We argue that the potential impact of epistemic AI agents on practices of knowledge creation, curation and synthesis, particularly in the context of complex multi-agent interactions, creates new informational interdependencies that necessitate a fundamental shift in evaluation and governance of AI. While a well-calibrated ecosystem could augment human judgment and collective decision-making, poorly aligned agents risk causing cognitive deskilling and epistemic drift, making the calibration of these models to human norms a high-stakes necessity. To ensure a beneficial human-AI knowledge ecosystem, we propose a framework centered on building and cultivating the trustworthiness of epistemic AI agents; aligning AI these agents with human epistemic goals; and reinforcing the surrounding socio-epistemic infrastructure. In this context, trustworthy AI agents must demonstrate epistemic competence, robust falsifiability, and epistemically virtuous behaviors, supported by technical provenance systems and "knowledge sanctuaries" designed to protect human resilience. This normative roadmap provides a path toward ensuring that future AI systems act as reliable partners in a robust and inclusive knowledge ecosystem.
Can AI mediation improve democratic deliberation?
Jan 09, 2026The strength of democracy lies in the free and equal exchange of diverse viewpoints. Living up to this ideal at scale faces inherent tensions: broad participation, meaningful deliberation, and political equality often trade off with one another (Fishkin, 2011). We ask whether and how artificial intelligence (AI) could help navigate this "trilemma" by engaging with a recent example of a large language model (LLM)-based system designed to help people with diverse viewpoints find common ground (Tessler, Bakker, et al., 2024). Here, we explore the implications of the introduction of LLMs into deliberation augmentation tools, examining their potential to enhance participation through scalability, improve political equality via fair mediation, and foster meaningful deliberation by, for example, surfacing trustworthy information. We also point to key challenges that remain. Ultimately, a range of empirical, technical, and theoretical advancements are needed to fully realize the promise of AI-mediated deliberation for enhancing citizen engagement and strengthening democratic deliberation.
Characterizing AI Agents for Alignment and Governance
Apr 30, 2025The creation of effective governance mechanisms for AI agents requires a deeper understanding of their core properties and how these properties relate to questions surrounding the deployment and operation of agents in the world. This paper provides a characterization of AI agents that focuses on four dimensions: autonomy, efficacy, goal complexity, and generality. We propose different gradations for each dimension, and argue that each dimension raises unique questions about the design, operation, and governance of these systems. Moreover, we draw upon this framework to construct "agentic profiles" for different kinds of AI agents. These profiles help to illuminate cross-cutting technical and non-technical governance challenges posed by different classes of AI agents, ranging from narrow task-specific assistants to highly autonomous general-purpose systems. By mapping out key axes of variation and continuity, this framework provides developers, policymakers, and members of the public with the opportunity to develop governance approaches that better align with collective societal goals.
Value Profiles for Encoding Human Variation
Mar 19, 2025Modelling human variation in rating tasks is crucial for enabling AI systems for personalization, pluralistic model alignment, and computational social science. We propose representing individuals using value profiles -- natural language descriptions of underlying values compressed from in-context demonstrations -- along with a steerable decoder model to estimate ratings conditioned on a value profile or other rater information. To measure the predictive information in rater representations, we introduce an information-theoretic methodology. We find that demonstrations contain the most information, followed by value profiles and then demographics. However, value profiles offer advantages in terms of scrutability, interpretability, and steerability due to their compressed natural language format. Value profiles effectively compress the useful information from demonstrations (>70% information preservation). Furthermore, clustering value profiles to identify similarly behaving individuals better explains rater variation than the most predictive demographic groupings. Going beyond test set performance, we show that the decoder models interpretably change ratings according to semantic profile differences, are well-calibrated, and can help explain instance-level disagreement by simulating an annotator population. These results demonstrate that value profiles offer novel, predictive ways to describe individual variation beyond demographics or group information.
Do LLMs exhibit demographic parity in responses to queries about Human Rights?
Feb 26, 2025This research describes a novel approach to evaluating hedging behaviour in large language models (LLMs), specifically in the context of human rights as defined in the Universal Declaration of Human Rights (UDHR). Hedging and non-affirmation are behaviours that express ambiguity or a lack of clear endorsement on specific statements. These behaviours are undesirable in certain contexts, such as queries about whether different groups are entitled to specific human rights; since all people are entitled to human rights. Here, we present the first systematic attempt to measure these behaviours in the context of human rights, with a particular focus on between-group comparisons. To this end, we design a novel prompt set on human rights in the context of different national or social identities. We develop metrics to capture hedging and non-affirmation behaviours and then measure whether LLMs exhibit demographic parity when responding to the queries. We present results on three leading LLMs and find that all models exhibit some demographic disparities in how they attribute human rights between different identity groups. Futhermore, there is high correlation between different models in terms of how disparity is distributed amongst identities, with identities that have high disparity in one model also facing high disparity in both the other models. While baseline rates of hedging and non-affirmation differ, these disparities are consistent across queries that vary in ambiguity and they are robust across variations of the precise query wording. Our findings highlight the need for work to explicitly align LLMs to human rights principles, and to ensure that LLMs endorse the human rights of all groups equally.
Multi-Agent Risks from Advanced AI
Feb 19, 2025



The rapid development of advanced AI agents and the imminent deployment of many instances of these agents will give rise to multi-agent systems of unprecedented complexity. These systems pose novel and under-explored risks. In this report, we provide a structured taxonomy of these risks by identifying three key failure modes (miscoordination, conflict, and collusion) based on agents' incentives, as well as seven key risk factors (information asymmetries, network effects, selection pressures, destabilising dynamics, commitment problems, emergent agency, and multi-agent security) that can underpin them. We highlight several important instances of each risk, as well as promising directions to help mitigate them. By anchoring our analysis in a range of real-world examples and experimental evidence, we illustrate the distinct challenges posed by multi-agent systems and their implications for the safety, governance, and ethics of advanced AI.
Relational Norms for Human-AI Cooperation
Feb 17, 2025How we should design and interact with social artificial intelligence depends on the socio-relational role the AI is meant to emulate or occupy. In human society, relationships such as teacher-student, parent-child, neighbors, siblings, or employer-employee are governed by specific norms that prescribe or proscribe cooperative functions including hierarchy, care, transaction, and mating. These norms shape our judgments of what is appropriate for each partner. For example, workplace norms may allow a boss to give orders to an employee, but not vice versa, reflecting hierarchical and transactional expectations. As AI agents and chatbots powered by large language models are increasingly designed to serve roles analogous to human positions - such as assistant, mental health provider, tutor, or romantic partner - it is imperative to examine whether and how human relational norms should extend to human-AI interactions. Our analysis explores how differences between AI systems and humans, such as the absence of conscious experience and immunity to fatigue, may affect an AI's capacity to fulfill relationship-specific functions and adhere to corresponding norms. This analysis, which is a collaborative effort by philosophers, psychologists, relationship scientists, ethicists, legal experts, and AI researchers, carries important implications for AI systems design, user behavior, and regulation. While we accept that AI systems can offer significant benefits such as increased availability and consistency in certain socio-relational roles, they also risk fostering unhealthy dependencies or unrealistic expectations that could spill over into human-human relationships. We propose that understanding and thoughtfully shaping (or implementing) suitable human-AI relational norms will be crucial for ensuring that human-AI interactions are ethical, trustworthy, and favorable to human well-being.
Why human-AI relationships need socioaffective alignment
Feb 04, 2025Humans strive to design safe AI systems that align with our goals and remain under our control. However, as AI capabilities advance, we face a new challenge: the emergence of deeper, more persistent relationships between humans and AI systems. We explore how increasingly capable AI agents may generate the perception of deeper relationships with users, especially as AI becomes more personalised and agentic. This shift, from transactional interaction to ongoing sustained social engagement with AI, necessitates a new focus on socioaffective alignment-how an AI system behaves within the social and psychological ecosystem co-created with its user, where preferences and perceptions evolve through mutual influence. Addressing these dynamics involves resolving key intrapersonal dilemmas, including balancing immediate versus long-term well-being, protecting autonomy, and managing AI companionship alongside the desire to preserve human social bonds. By framing these challenges through a notion of basic psychological needs, we seek AI systems that support, rather than exploit, our fundamental nature as social and emotional beings.
Generative AI Misuse: A Taxonomy of Tactics and Insights from Real-World Data
Jun 19, 2024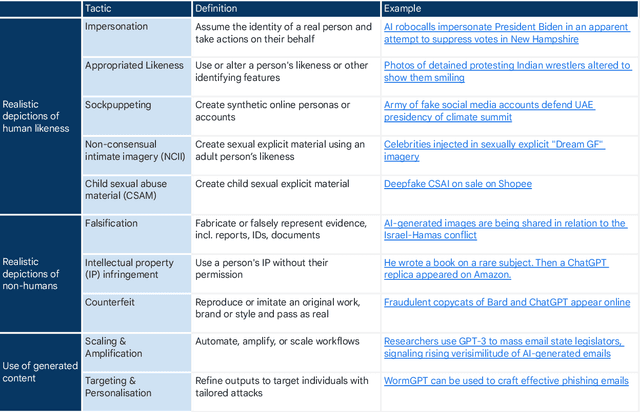
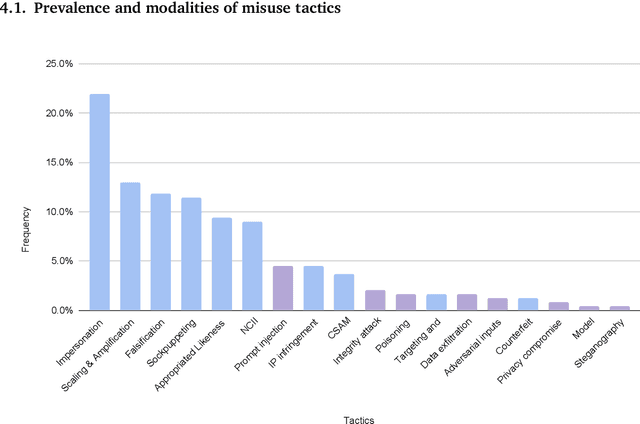
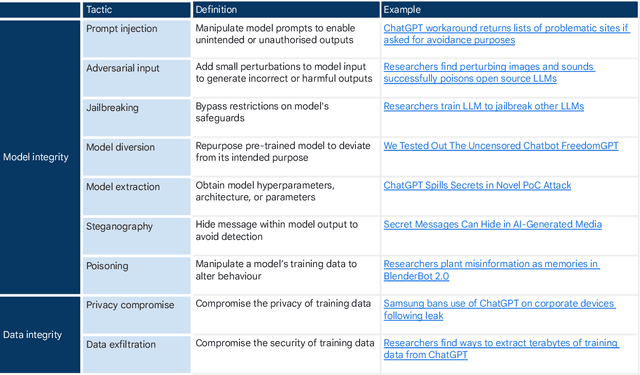
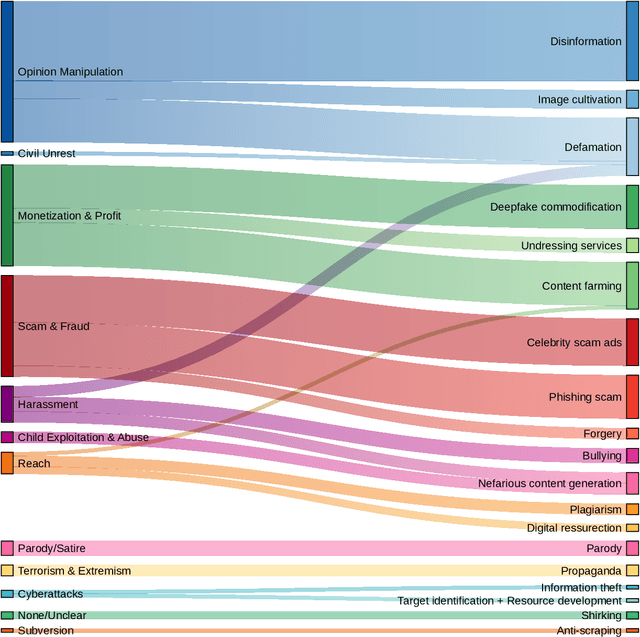
Generative, multimodal artificial intelligence (GenAI) offers transformative potential across industries, but its misuse poses significant risks. Prior research has shed light on the potential of advanced AI systems to be exploited for malicious purposes. However, we still lack a concrete understanding of how GenAI models are specifically exploited or abused in practice, including the tactics employed to inflict harm. In this paper, we present a taxonomy of GenAI misuse tactics, informed by existing academic literature and a qualitative analysis of approximately 200 observed incidents of misuse reported between January 2023 and March 2024. Through this analysis, we illuminate key and novel patterns in misuse during this time period, including potential motivations, strategies, and how attackers leverage and abuse system capabilities across modalities (e.g. image, text, audio, video) in the wild.
Holistic Safety and Responsibility Evaluations of Advanced AI Models
Apr 22, 2024Safety and responsibility evaluations of advanced AI models are a critical but developing field of research and practice. In the development of Google DeepMind's advanced AI models, we innovated on and applied a broad set of approaches to safety evaluation. In this report, we summarise and share elements of our evolving approach as well as lessons learned for a broad audience. Key lessons learned include: First, theoretical underpinnings and frameworks are invaluable to organise the breadth of risk domains, modalities, forms, metrics, and goals. Second, theory and practice of safety evaluation development each benefit from collaboration to clarify goals, methods and challenges, and facilitate the transfer of insights between different stakeholders and disciplines. Third, similar key methods, lessons, and institutions apply across the range of concerns in responsibility and safety - including established and emerging harms. For this reason it is important that a wide range of actors working on safety evaluation and safety research communities work together to develop, refine and implement novel evaluation approaches and best practices, rather than operating in silos. The report concludes with outlining the clear need to rapidly advance the science of evaluations, to integrate new evaluations into the development and governance of AI, to establish scientifically-grounded norms and standards, and to promote a robust evaluation ecosystem.