 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValue Profiles for Encoding Human Variation
Mar 19, 2025Modelling human variation in rating tasks is crucial for enabling AI systems for personalization, pluralistic model alignment, and computational social science. We propose representing individuals using value profiles -- natural language descriptions of underlying values compressed from in-context demonstrations -- along with a steerable decoder model to estimate ratings conditioned on a value profile or other rater information. To measure the predictive information in rater representations, we introduce an information-theoretic methodology. We find that demonstrations contain the most information, followed by value profiles and then demographics. However, value profiles offer advantages in terms of scrutability, interpretability, and steerability due to their compressed natural language format. Value profiles effectively compress the useful information from demonstrations (>70% information preservation). Furthermore, clustering value profiles to identify similarly behaving individuals better explains rater variation than the most predictive demographic groupings. Going beyond test set performance, we show that the decoder models interpretably change ratings according to semantic profile differences, are well-calibrated, and can help explain instance-level disagreement by simulating an annotator population. These results demonstrate that value profiles offer novel, predictive ways to describe individual variation beyond demographics or group information.
Insights on Disagreement Patterns in Multimodal Safety Perception across Diverse Rater Groups
Oct 22, 2024



AI systems crucially rely on human ratings, but these ratings are often aggregated, obscuring the inherent diversity of perspectives in real-world phenomenon. This is particularly concerning when evaluating the safety of generative AI, where perceptions and associated harms can vary significantly across socio-cultural contexts. While recent research has studied the impact of demographic differences on annotating text, there is limited understanding of how these subjective variations affect multimodal safety in generative AI. To address this, we conduct a large-scale study employing highly-parallel safety ratings of about 1000 text-to-image (T2I) generations from a demographically diverse rater pool of 630 raters balanced across 30 intersectional groups across age, gender, and ethnicity. Our study shows that (1) there are significant differences across demographic groups (including intersectional groups) on how severe they assess the harm to be, and that these differences vary across different types of safety violations, (2) the diverse rater pool captures annotation patterns that are substantially different from expert raters trained on specific set of safety policies, and (3) the differences we observe in T2I safety are distinct from previously documented group level differences in text-based safety tasks. To further understand these varying perspectives, we conduct a qualitative analysis of the open-ended explanations provided by raters. This analysis reveals core differences into the reasons why different groups perceive harms in T2I generations. Our findings underscore the critical need for incorporating diverse perspectives into safety evaluation of generative AI ensuring these systems are truly inclusive and reflect the values of all users.
A (More) Realistic Evaluation Setup for Generalisation of Community Models on Malicious Content Detection
Apr 02, 2024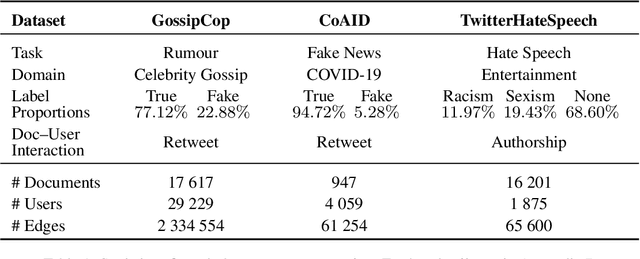
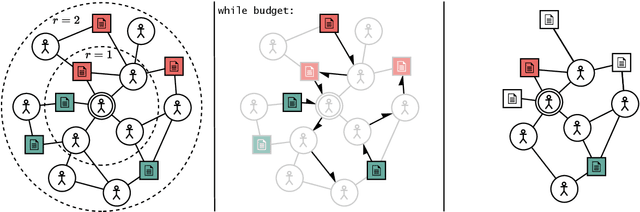
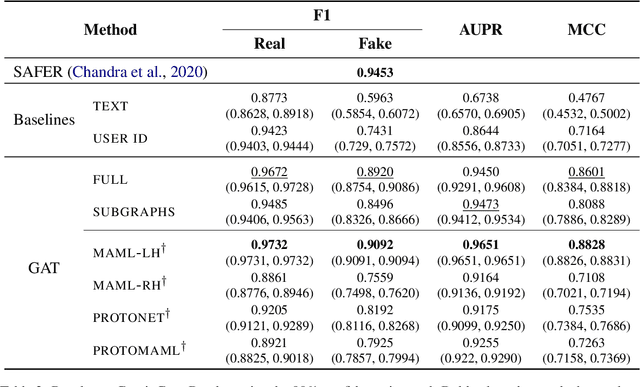
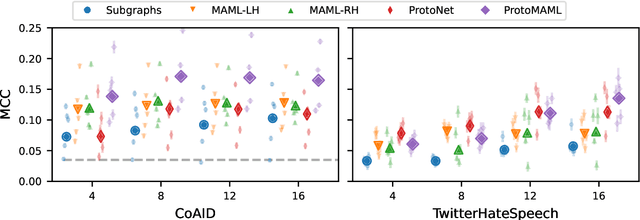
Community models for malicious content detection, which take into account the context from a social graph alongside the content itself, have shown remarkable performance on benchmark datasets. Yet, misinformation and hate speech continue to propagate on social media networks. This mismatch can be partially attributed to the limitations of current evaluation setups that neglect the rapid evolution of online content and the underlying social graph. In this paper, we propose a novel evaluation setup for model generalisation based on our few-shot subgraph sampling approach. This setup tests for generalisation through few labelled examples in local explorations of a larger graph, emulating more realistic application settings. We show this to be a challenging inductive setup, wherein strong performance on the training graph is not indicative of performance on unseen tasks, domains, or graph structures. Lastly, we show that graph meta-learners trained with our proposed few-shot subgraph sampling outperform standard community models in the inductive setup. We make our code publicly available.
Investigating the Robustness of Sequential Recommender Systems Against Training Data Perturbations: an Empirical Study
Jul 24, 2023Sequential Recommender Systems (SRSs) have been widely used to model user behavior over time, but their robustness in the face of perturbations to training data is a critical issue. In this paper, we conduct an empirical study to investigate the effects of removing items at different positions within a temporally ordered sequence. We evaluate two different SRS models on multiple datasets, measuring their performance using Normalized Discounted Cumulative Gain (NDCG) and Rank Sensitivity List metrics. Our results demonstrate that removing items at the end of the sequence significantly impacts performance, with NDCG decreasing up to 60\%, while removing items from the beginning or middle has no significant effect. These findings highlight the importance of considering the position of the perturbed items in the training data and shall inform the design of more robust SRSs.
Llama 2: Open Foundation and Fine-Tuned Chat Models
Jul 19, 2023



In this work, we develop and release Llama 2, a collection of pretrained and fine-tuned large language models (LLMs) ranging in scale from 7 billion to 70 billion parameters. Our fine-tuned LLMs, called Llama 2-Chat, are optimized for dialogue use cases. Our models outperform open-source chat models on most benchmarks we tested, and based on our human evaluations for helpfulness and safety, may be a suitable substitute for closed-source models. We provide a detailed description of our approach to fine-tuning and safety improvements of Llama 2-Chat in order to enable the community to build on our work and contribute to the responsible development of LLMs.
Scientific and Creative Analogies in Pretrained Language Models
Nov 28, 2022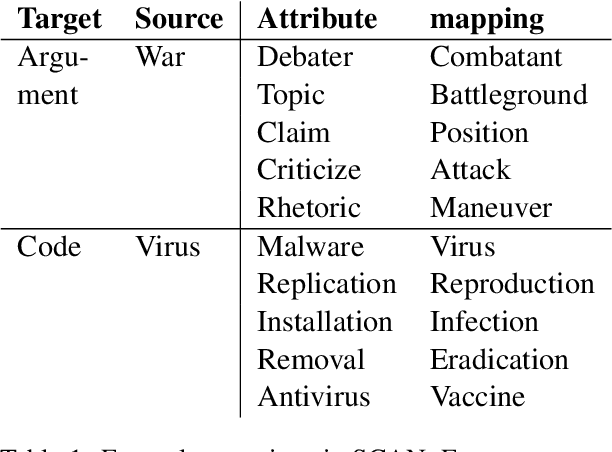
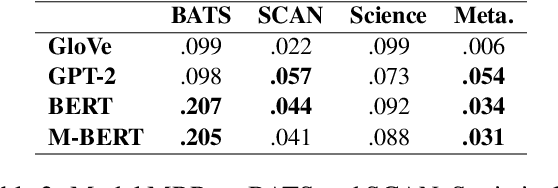
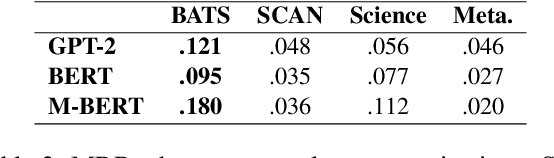
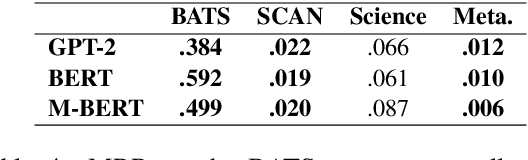
This paper examines the encoding of analogy in large-scale pretrained language models, such as BERT and GPT-2. Existing analogy datasets typically focus on a limited set of analogical relations, with a high similarity of the two domains between which the analogy holds. As a more realistic setup, we introduce the Scientific and Creative Analogy dataset (SCAN), a novel analogy dataset containing systematic mappings of multiple attributes and relational structures across dissimilar domains. Using this dataset, we test the analogical reasoning capabilities of several widely-used pretrained language models (LMs). We find that state-of-the-art LMs achieve low performance on these complex analogy tasks, highlighting the challenges still posed by analogy understanding.
ReFactorGNNs: Revisiting Factorisation-based Models from a Message-Passing Perspective
Jul 21, 2022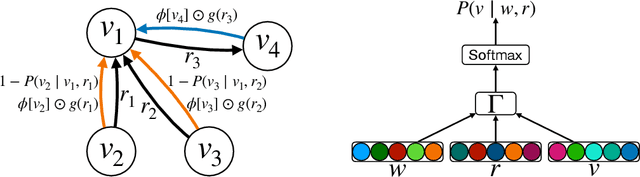

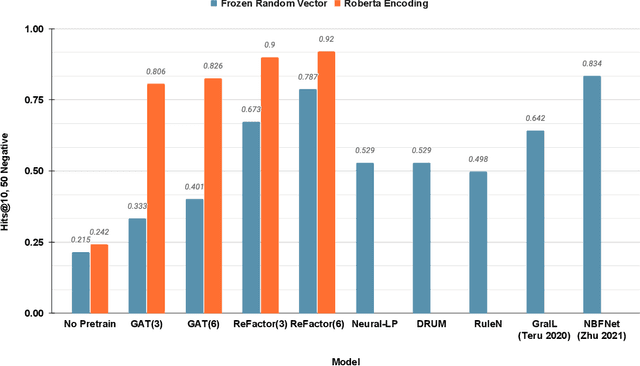

Factorisation-based Models (FMs), such as DistMult, have enjoyed enduring success for Knowledge Graph Completion (KGC) tasks, often outperforming Graph Neural Networks (GNNs). However, unlike GNNs, FMs struggle to incorporate node features and to generalise to unseen nodes in inductive settings. Our work bridges the gap between FMs and GNNs by proposing ReFactorGNNs. This new architecture draws upon both modelling paradigms, which previously were largely thought of as disjoint. Concretely, using a message-passing formalism, we show how FMs can be cast as GNNs by reformulating the gradient descent procedure as message-passing operations, which forms the basis of our ReFactorGNNs. Across a multitude of well-established KGC benchmarks, our ReFactorGNNs achieve comparable transductive performance to FMs, and state-of-the-art inductive performance while using an order of magnitude fewer parameters.
Prescriptive and Descriptive Approaches to Machine-Learning Transparency
Apr 27, 2022
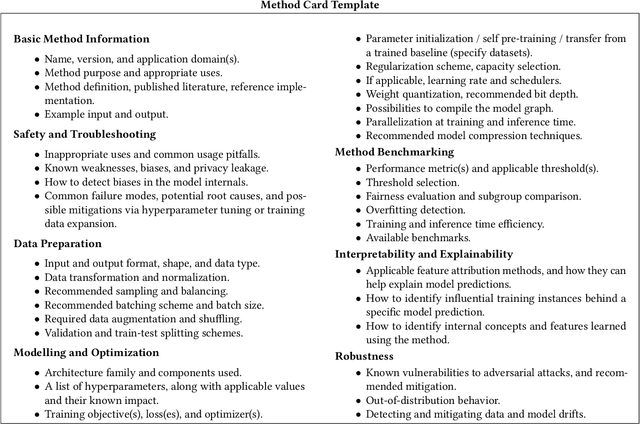
Specialized documentation techniques have been developed to communicate key facts about machine-learning (ML) systems and the datasets and models they rely on. Techniques such as Datasheets, FactSheets, and Model Cards have taken a mainly descriptive approach, providing various details about the system components. While the above information is essential for product developers and external experts to assess whether the ML system meets their requirements, other stakeholders might find it less actionable. In particular, ML engineers need guidance on how to mitigate potential shortcomings in order to fix bugs or improve the system's performance. We survey approaches that aim to provide such guidance in a prescriptive way. We further propose a preliminary approach, called Method Cards, which aims to increase the transparency and reproducibility of ML systems by providing prescriptive documentation of commonly-used ML methods and techniques. We showcase our proposal with an example in small object detection, and demonstrate how Method Cards can communicate key considerations for model developers. We further highlight avenues for improving the user experience of ML engineers based on Method Cards.
Ruddit: Norms of Offensiveness for English Reddit Comments
Jun 11, 2021
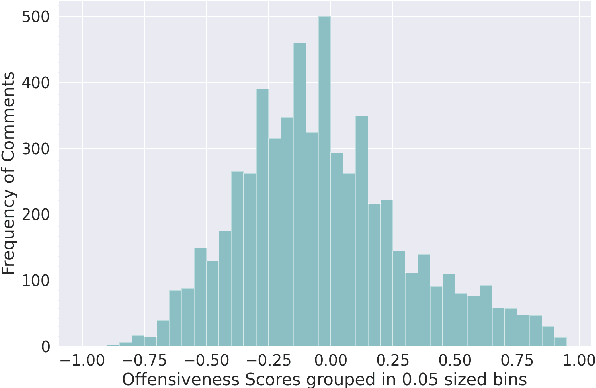

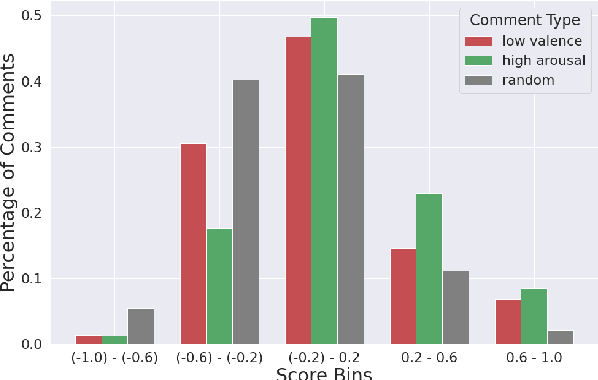
On social media platforms, hateful and offensive language negatively impact the mental well-being of users and the participation of people from diverse backgrounds. Automatic methods to detect offensive language have largely relied on datasets with categorical labels. However, comments can vary in their degree of offensiveness. We create the first dataset of English language Reddit comments that has fine-grained, real-valued scores between -1 (maximally supportive) and 1 (maximally offensive). The dataset was annotated using Best--Worst Scaling, a form of comparative annotation that has been shown to alleviate known biases of using rating scales. We show that the method produces highly reliable offensiveness scores. Finally, we evaluate the ability of widely-used neural models to predict offensiveness scores on this new dataset.
Modeling Users and Online Communities for Abuse Detection: A Position on Ethics and Explainability
Apr 14, 2021Abuse on the Internet is an important societal problem of our time. Millions of Internet users face harassment, racism, personal attacks, and other types of abuse across various platforms. The psychological effects of abuse on individuals can be profound and lasting. Consequently, over the past few years, there has been a substantial research effort towards automated abusive language detection in the field of NLP. In this position paper, we discuss the role that modeling of users and online communities plays in abuse detection. Specifically, we review and analyze the state of the art methods that leverage user or community information to enhance the understanding and detection of abusive language. We then explore the ethical challenges of incorporating user and community information, laying out considerations to guide future research. Finally, we address the topic of explainability in abusive language detection, proposing properties that an explainable method should aim to exhibit. We describe how user and community information can facilitate the realization of these properties and discuss the effective operationalization of explainability in view of the properties.