 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
Bias Mitigation Framework for Intersectional Subgroups in Neural Networks
Dec 26, 2022We propose a fairness-aware learning framework that mitigates intersectional subgroup bias associated with protected attributes. Prior research has primarily focused on mitigating one kind of bias by incorporating complex fairness-driven constraints into optimization objectives or designing additional layers that focus on specific protected attributes. We introduce a simple and generic bias mitigation approach that prevents models from learning relationships between protected attributes and output variable by reducing mutual information between them. We demonstrate that our approach is effective in reducing bias with little or no drop in accuracy. We also show that the models trained with our learning framework become causally fair and insensitive to the values of protected attributes. Finally, we validate our approach by studying feature interactions between protected and non-protected attributes. We demonstrate that these interactions are significantly reduced when applying our bias mitigation.
Prescriptive and Descriptive Approaches to Machine-Learning Transparency
Apr 27, 2022
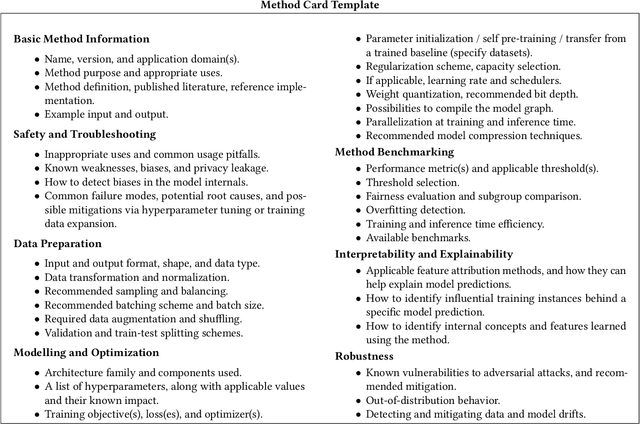
Specialized documentation techniques have been developed to communicate key facts about machine-learning (ML) systems and the datasets and models they rely on. Techniques such as Datasheets, FactSheets, and Model Cards have taken a mainly descriptive approach, providing various details about the system components. While the above information is essential for product developers and external experts to assess whether the ML system meets their requirements, other stakeholders might find it less actionable. In particular, ML engineers need guidance on how to mitigate potential shortcomings in order to fix bugs or improve the system's performance. We survey approaches that aim to provide such guidance in a prescriptive way. We further propose a preliminary approach, called Method Cards, which aims to increase the transparency and reproducibility of ML systems by providing prescriptive documentation of commonly-used ML methods and techniques. We showcase our proposal with an example in small object detection, and demonstrate how Method Cards can communicate key considerations for model developers. We further highlight avenues for improving the user experience of ML engineers based on Method Cards.