 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
On Symmetries in Convolutional Weights
Mar 24, 2025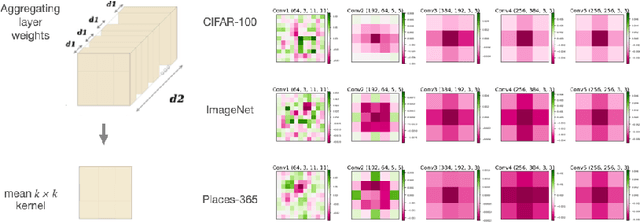

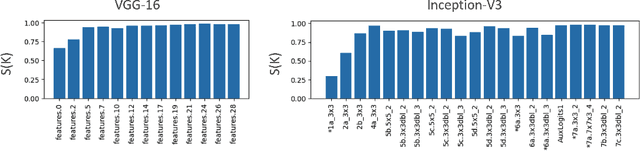
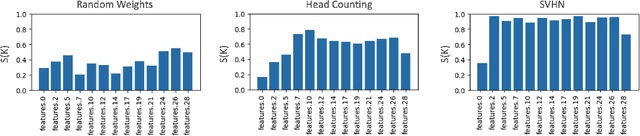
We explore the symmetry of the mean k x k weight kernel in each layer of various convolutional neural networks. Unlike individual neurons, the mean kernels in internal layers tend to be symmetric about their centers instead of favoring specific directions. We investigate why this symmetry emerges in various datasets and models, and how it is impacted by certain architectural choices. We show how symmetry correlates with desirable properties such as shift and flip consistency, and might constitute an inherent inductive bias in convolutional neural networks.
Using Captum to Explain Generative Language Models
Dec 09, 2023Captum is a comprehensive library for model explainability in PyTorch, offering a range of methods from the interpretability literature to enhance users' understanding of PyTorch models. In this paper, we introduce new features in Captum that are specifically designed to analyze the behavior of generative language models. We provide an overview of the available functionalities and example applications of their potential for understanding learned associations within generative language models.
Bias Mitigation Framework for Intersectional Subgroups in Neural Networks
Dec 26, 2022We propose a fairness-aware learning framework that mitigates intersectional subgroup bias associated with protected attributes. Prior research has primarily focused on mitigating one kind of bias by incorporating complex fairness-driven constraints into optimization objectives or designing additional layers that focus on specific protected attributes. We introduce a simple and generic bias mitigation approach that prevents models from learning relationships between protected attributes and output variable by reducing mutual information between them. We demonstrate that our approach is effective in reducing bias with little or no drop in accuracy. We also show that the models trained with our learning framework become causally fair and insensitive to the values of protected attributes. Finally, we validate our approach by studying feature interactions between protected and non-protected attributes. We demonstrate that these interactions are significantly reduced when applying our bias mitigation.
Investigating sanity checks for saliency maps with image and text classification
Jun 08, 2021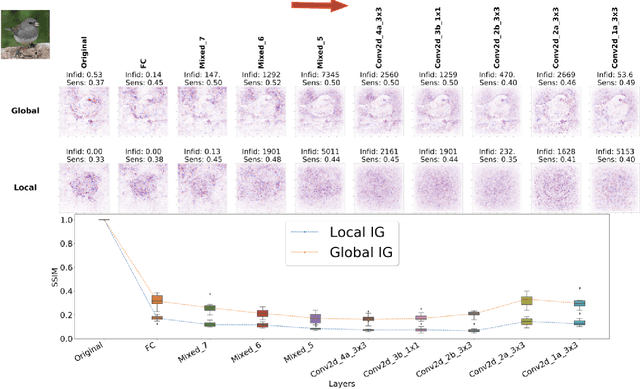
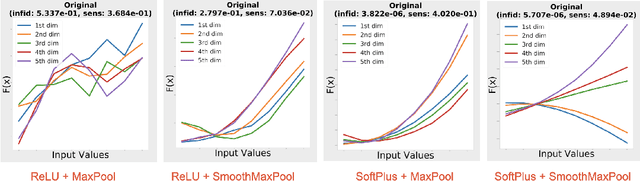
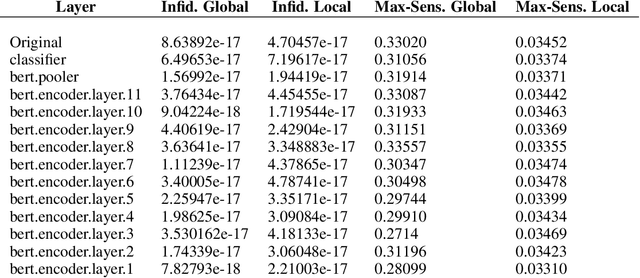
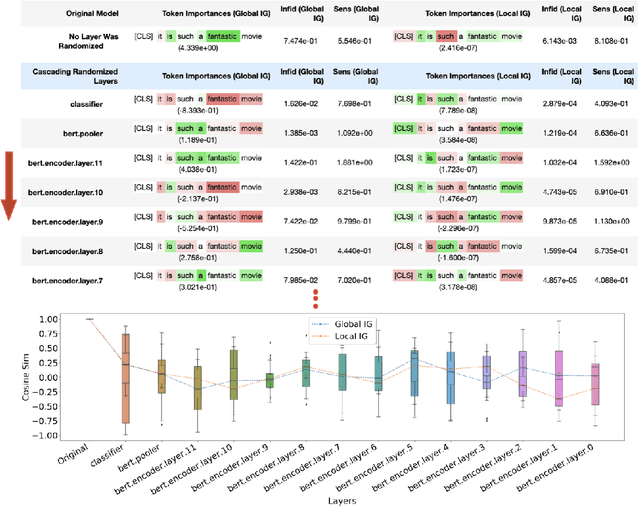
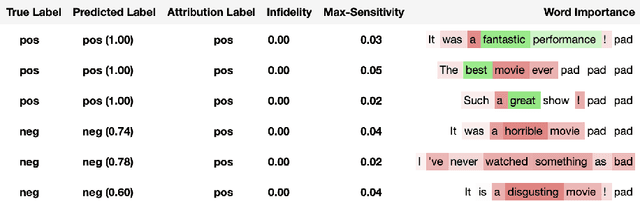
Saliency maps have shown to be both useful and misleading for explaining model predictions especially in the context of images. In this paper, we perform sanity checks for text modality and show that the conclusions made for image do not directly transfer to text. We also analyze the effects of the input multiplier in certain saliency maps using similarity scores, max-sensitivity and infidelity evaluation metrics. Our observations reveal that the input multiplier carries input's structural patterns in explanation maps, thus leading to similar results regardless of the choice of model parameters. We also show that the smoothness of a Neural Network (NN) function can affect the quality of saliency-based explanations. Our investigations reveal that replacing ReLUs with Softplus and MaxPool with smoother variants such as LogSumExp (LSE) can lead to explanations that are more reliable based on the infidelity evaluation metric.
Investigating Saturation Effects in Integrated Gradients
Oct 23, 2020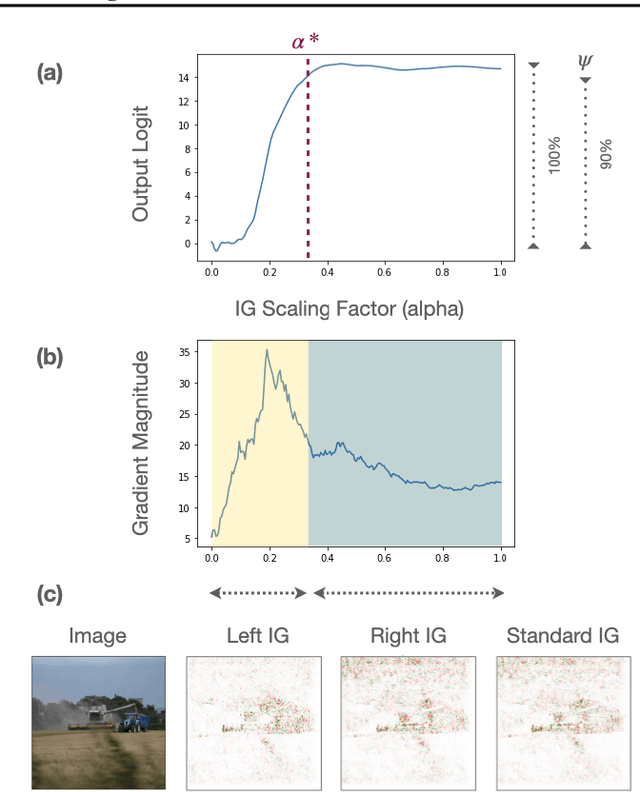
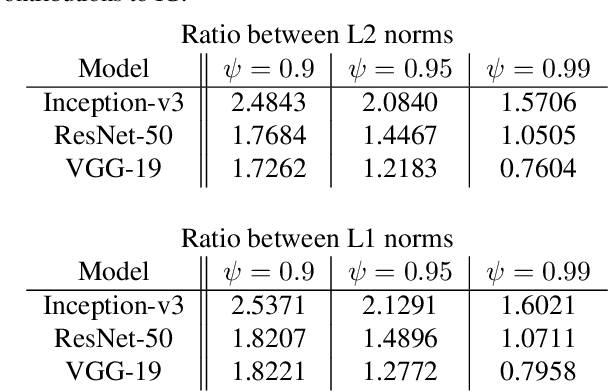

Integrated Gradients has become a popular method for post-hoc model interpretability. De-spite its popularity, the composition and relative impact of different regions of the integral path are not well understood. We explore these effects and find that gradients in saturated regions of this path, where model output changes minimally, contribute disproportionately to the computed attribution. We propose a variant of IntegratedGradients which primarily captures gradients in unsaturated regions and evaluate this method on ImageNet classification networks. We find that this attribution technique shows higher model faithfulness and lower sensitivity to noise com-pared with standard Integrated Gradients. A note-book illustrating our computations and results is available at https://github.com/vivekmig/captum-1/tree/ExpandedIG.
Mind the Pad -- CNNs can Develop Blind Spots
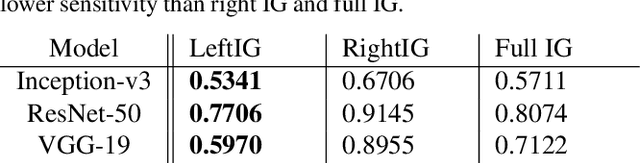
Oct 05, 2020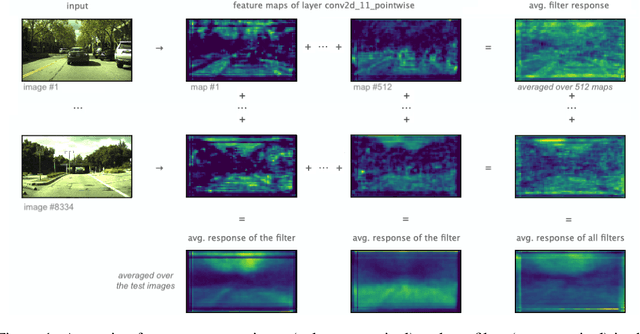

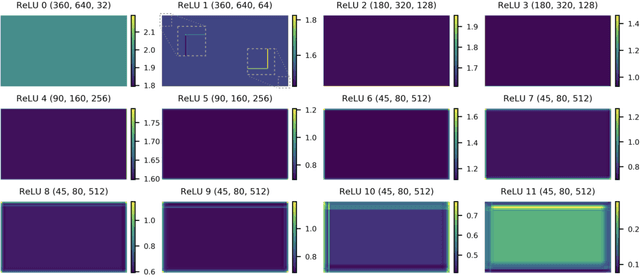

We show how feature maps in convolutional networks are susceptible to spatial bias. Due to a combination of architectural choices, the activation at certain locations is systematically elevated or weakened. The major source of this bias is the padding mechanism. Depending on several aspects of convolution arithmetic, this mechanism can apply the padding unevenly, leading to asymmetries in the learned weights. We demonstrate how such bias can be detrimental to certain tasks such as small object detection: the activation is suppressed if the stimulus lies in the impacted area, leading to blind spots and misdetection. We propose solutions to mitigate spatial bias and demonstrate how they can improve model accuracy.
Captum: A unified and generic model interpretability library for PyTorch
Sep 16, 2020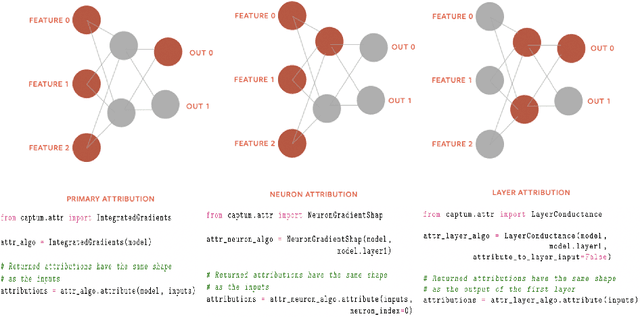

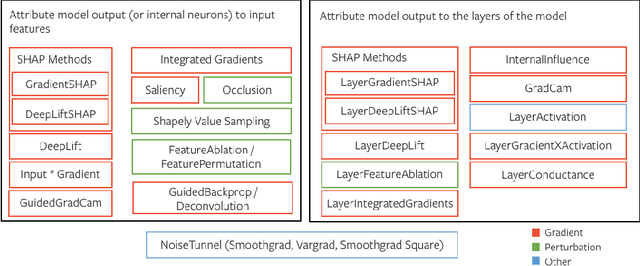
In this paper we introduce a novel, unified, open-source model interpretability library for PyTorch [12]. The library contains generic implementations of a number of gradient and perturbation-based attribution algorithms, also known as feature, neuron and layer importance algorithms, as well as a set of evaluation metrics for these algorithms. It can be used for both classification and non-classification models including graph-structured models built on Neural Networks (NN). In this paper we give a high-level overview of supported attribution algorithms and show how to perform memory-efficient and scalable computations. We emphasize that the three main characteristics of the library are multimodality, extensibility and ease of use. Multimodality supports different modality of inputs such as image, text, audio or video. Extensibility allows adding new algorithms and features. The library is also designed for easy understanding and use. Besides, we also introduce an interactive visualization tool called Captum Insights that is built on top of Captum library and allows sample-based model debugging and visualization using feature importance metrics.