 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Spaces Enable Transformer-Based Dose Prediction in Complex Radiotherapy Plans
Jul 11, 2024



Evidence is accumulating in favour of using stereotactic ablative body radiotherapy (SABR) to treat multiple cancer lesions in the lung. Multi-lesion lung SABR plans are complex and require significant resources to create. In this work, we propose a novel two-stage latent transformer framework (LDFormer) for dose prediction of lung SABR plans with varying numbers of lesions. In the first stage, patient anatomical information and the dose distribution are encoded into a latent space. In the second stage, a transformer learns to predict the dose latent from the anatomical latents. Causal attention is modified to adapt to different numbers of lesions. LDFormer outperforms a state-of-the-art generative adversarial network on dose conformality in and around lesions, and the performance gap widens when considering overlapping lesions. LDFormer generates predictions of 3-D dose distributions in under 30s on consumer hardware, and has the potential to assist physicians with clinical decision making, reduce resource costs, and accelerate treatment planning.
SpecTracle: Wearable Facial Motion Tracking from Unobtrusive Peripheral Cameras
Aug 14, 2023

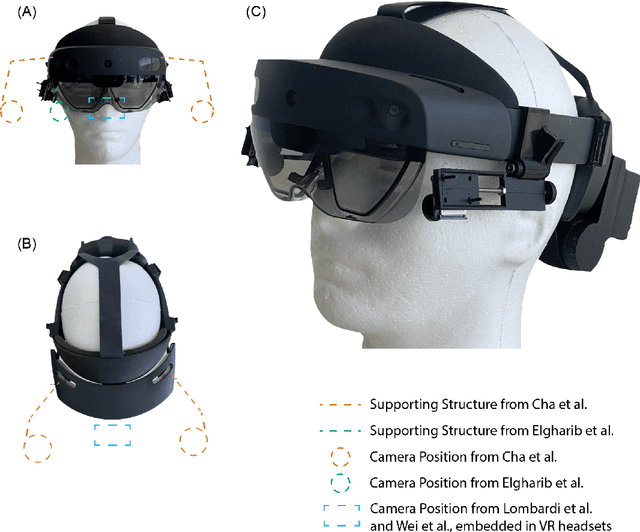
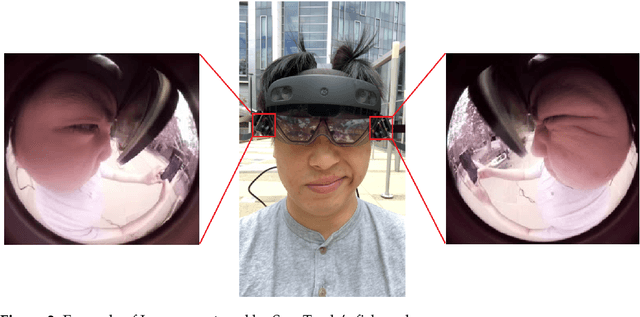
Facial motion tracking in head-mounted displays (HMD) has the potential to enable immersive "face-to-face" interaction in a virtual environment. However, current works on facial tracking are not suitable for unobtrusive augmented reality (AR) glasses or do not have the ability to track arbitrary facial movements. In this work, we demonstrate a novel system called SpecTracle that tracks a user's facial motions using two wide-angle cameras mounted right next to the visor of a Hololens. Avoiding the usage of cameras extended in front of the face, our system greatly improves the feasibility to integrate full-face tracking into a low-profile form factor. We also demonstrate that a neural network-based model processing the wide-angle cameras can run in real-time at 24 frames per second (fps) on a mobile GPU and track independent facial movement for different parts of the face with a user-independent model. Using a short personalized calibration, the system improves its tracking performance by 42.3% compared to the user-independent model.
AIROGS: Artificial Intelligence for RObust Glaucoma Screening Challenge
Feb 10, 2023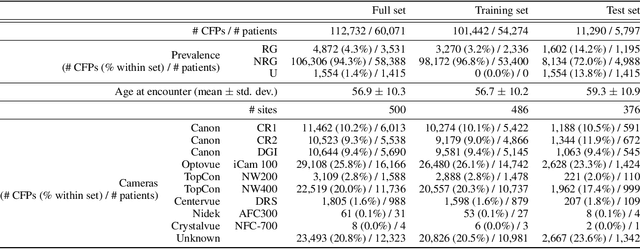
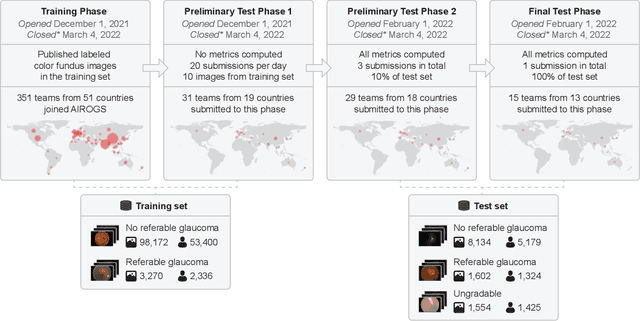
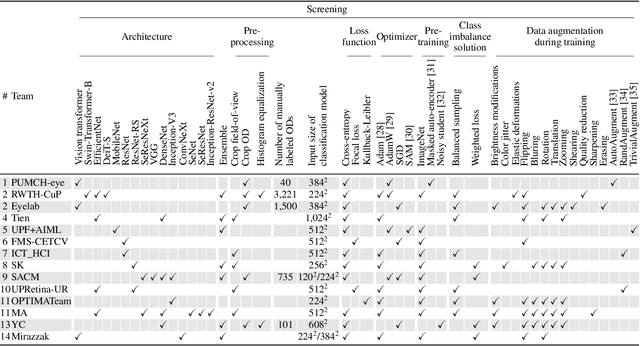
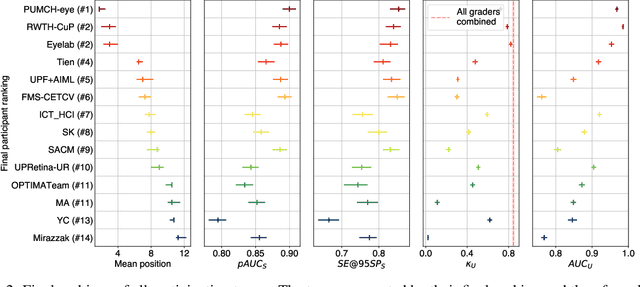
The early detection of glaucoma is essential in preventing visual impairment. Artificial intelligence (AI) can be used to analyze color fundus photographs (CFPs) in a cost-effective manner, making glaucoma screening more accessible. While AI models for glaucoma screening from CFPs have shown promising results in laboratory settings, their performance decreases significantly in real-world scenarios due to the presence of out-of-distribution and low-quality images. To address this issue, we propose the Artificial Intelligence for Robust Glaucoma Screening (AIROGS) challenge. This challenge includes a large dataset of around 113,000 images from about 60,000 patients and 500 different screening centers, and encourages the development of algorithms that are robust to ungradable and unexpected input data. We evaluated solutions from 14 teams in this paper, and found that the best teams performed similarly to a set of 20 expert ophthalmologists and optometrists. The highest-scoring team achieved an area under the receiver operating characteristic curve of 0.99 (95% CI: 0.98-0.99) for detecting ungradable images on-the-fly. Additionally, many of the algorithms showed robust performance when tested on three other publicly available datasets. These results demonstrate the feasibility of robust AI-enabled glaucoma screening.
YeLan: Event Camera-Based 3D Human Pose Estimation for Technology-Mediated Dancing in Challenging Environments with Comprehensive Motion-to-Event Simulator
Jan 17, 2023As a beloved sport worldwide, dancing is getting integrated into traditional and virtual reality-based gaming platforms nowadays. It opens up new opportunities in the technology-mediated dancing space. These platforms primarily rely on passive and continuous human pose estimation as an input capture mechanism. Existing solutions are mainly based on RGB or RGB-Depth cameras for dance games. The former suffers in low-lighting conditions due to the motion blur and low sensitivity, while the latter is too power-hungry, has a low frame rate, and has limited working distance. With ultra-low latency, energy efficiency, and wide dynamic range characteristics, the event camera is a promising solution to overcome these shortcomings. We propose YeLan, an event camera-based 3-dimensional human pose estimation(HPE) system that survives low-lighting and dynamic background contents. We collected the world's first event camera dance dataset and developed a fully customizable motion-to-event physics-aware simulator. YeLan outperforms the baseline models in these challenging conditions and demonstrated robustness against different types of clothing, background motion, viewing angle, occlusion, and lighting fluctuations.
Smartphone Camera Oximetry in an Induced Hypoxemia Study
Mar 31, 2021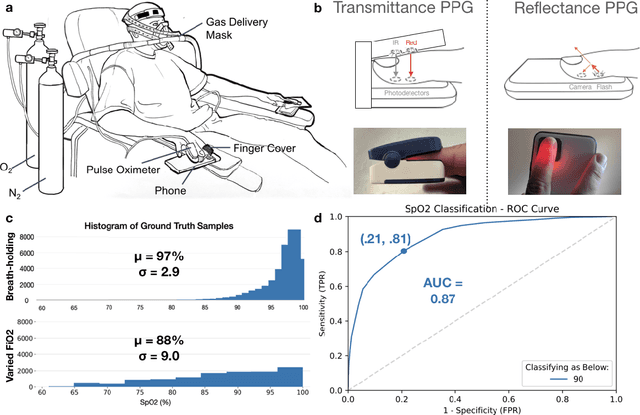
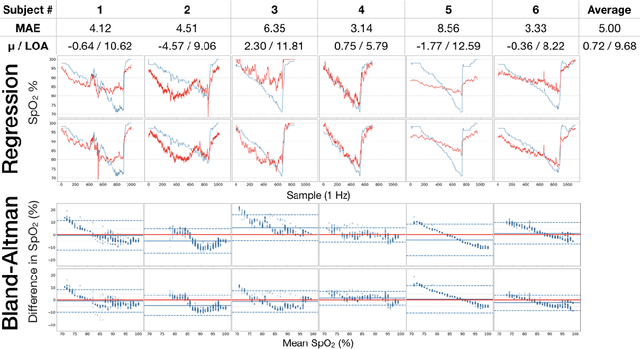
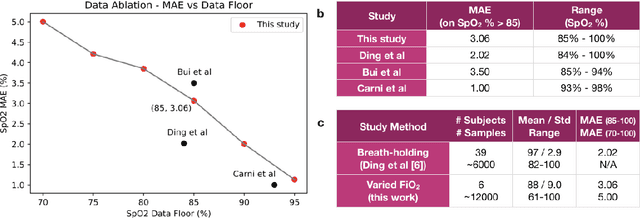
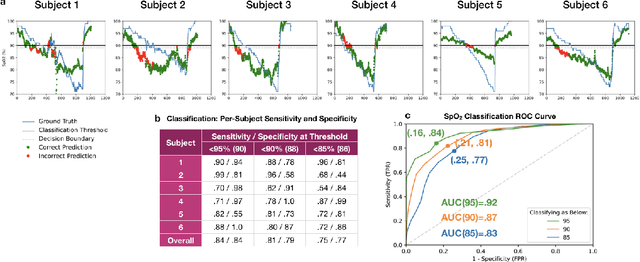
Hypoxemia, a medical condition that occurs when the blood is not carrying enough oxygen to adequately supply the tissues, is a leading indicator for dangerous complications of respiratory diseases like asthma, COPD, and COVID-19. While purpose-built pulse oximeters can provide accurate blood-oxygen saturation (SpO$_2$) readings that allow for diagnosis of hypoxemia, enabling this capability in unmodified smartphone cameras via a software update could give more people access to important information about their health, as well as improve physicians' ability to remotely diagnose and treat respiratory conditions. In this work, we take a step towards this goal by performing the first clinical development validation on a smartphone-based SpO$_2$ sensing system using a varied fraction of inspired oxygen (FiO$_2$) protocol, creating a clinically relevant validation dataset for solely smartphone-based methods on a wide range of SpO$_2$ values (70%-100%) for the first time. This contrasts with previous studies, which evaluated performance on a far smaller range (85%-100%). We build a deep learning model using this data to demonstrate accurate reporting of SpO$_2$ level with an overall MAE=5.00% SpO$_2$ and identifying positive cases of low SpO$_2$<90% with 81% sensitivity and 79% specificity. We ground our analysis with a summary of recent literature in smartphone-based SpO2 monitoring, and we provide the data from the FiO$_2$ study in open-source format, so that others may build on this work.
Captum: A unified and generic model interpretability library for PyTorch
Sep 16, 2020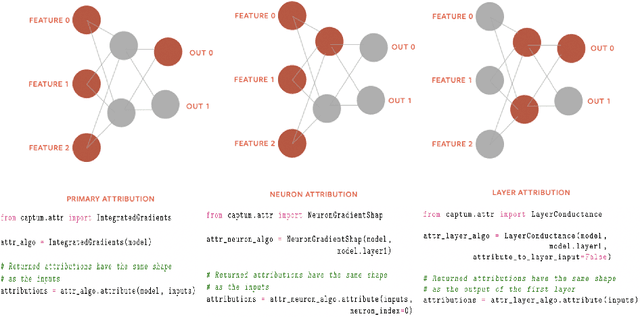

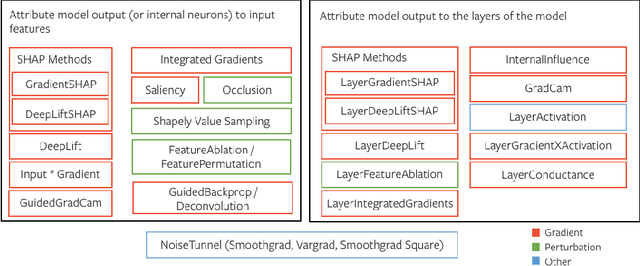
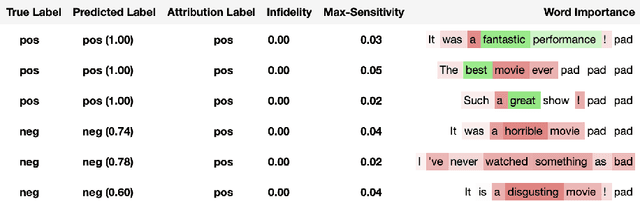
In this paper we introduce a novel, unified, open-source model interpretability library for PyTorch [12]. The library contains generic implementations of a number of gradient and perturbation-based attribution algorithms, also known as feature, neuron and layer importance algorithms, as well as a set of evaluation metrics for these algorithms. It can be used for both classification and non-classification models including graph-structured models built on Neural Networks (NN). In this paper we give a high-level overview of supported attribution algorithms and show how to perform memory-efficient and scalable computations. We emphasize that the three main characteristics of the library are multimodality, extensibility and ease of use. Multimodality supports different modality of inputs such as image, text, audio or video. Extensibility allows adding new algorithms and features. The library is also designed for easy understanding and use. Besides, we also introduce an interactive visualization tool called Captum Insights that is built on top of Captum library and allows sample-based model debugging and visualization using feature importance metrics.