 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYeLan: Event Camera-Based 3D Human Pose Estimation for Technology-Mediated Dancing in Challenging Environments with Comprehensive Motion-to-Event Simulator
Jan 17, 2023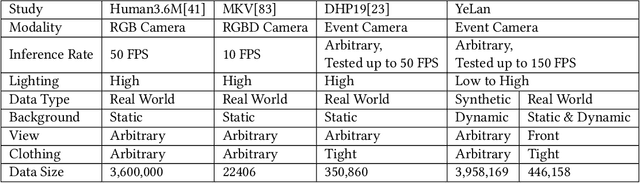



As a beloved sport worldwide, dancing is getting integrated into traditional and virtual reality-based gaming platforms nowadays. It opens up new opportunities in the technology-mediated dancing space. These platforms primarily rely on passive and continuous human pose estimation as an input capture mechanism. Existing solutions are mainly based on RGB or RGB-Depth cameras for dance games. The former suffers in low-lighting conditions due to the motion blur and low sensitivity, while the latter is too power-hungry, has a low frame rate, and has limited working distance. With ultra-low latency, energy efficiency, and wide dynamic range characteristics, the event camera is a promising solution to overcome these shortcomings. We propose YeLan, an event camera-based 3-dimensional human pose estimation(HPE) system that survives low-lighting and dynamic background contents. We collected the world's first event camera dance dataset and developed a fully customizable motion-to-event physics-aware simulator. YeLan outperforms the baseline models in these challenging conditions and demonstrated robustness against different types of clothing, background motion, viewing angle, occlusion, and lighting fluctuations.
Temporally Layered Architecture for Adaptive, Distributed and Continuous Control
Dec 25, 2022We present temporally layered architecture (TLA), a biologically inspired system for temporally adaptive distributed control. TLA layers a fast and a slow controller together to achieve temporal abstraction that allows each layer to focus on a different time-scale. Our design is biologically inspired and draws on the architecture of the human brain which executes actions at different timescales depending on the environment's demands. Such distributed control design is widespread across biological systems because it increases survivability and accuracy in certain and uncertain environments. We demonstrate that TLA can provide many advantages over existing approaches, including persistent exploration, adaptive control, explainable temporal behavior, compute efficiency and distributed control. We present two different algorithms for training TLA: (a) Closed-loop control, where the fast controller is trained over a pre-trained slow controller, allowing better exploration for the fast controller and closed-loop control where the fast controller decides whether to "act-or-not" at each timestep; and (b) Partially open loop control, where the slow controller is trained over a pre-trained fast controller, allowing for open loop-control where the slow controller picks a temporally extended action or defers the next n-actions to the fast controller. We evaluated our method on a suite of continuous control tasks and demonstrate the advantages of TLA over several strong baselines.