 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransient Dynamics in Lattices of Differentiating Ring Oscillators
Jun 08, 2025Recurrent neural networks (RNNs) are machine learning models widely used for learning temporal relationships. Current state-of-the-art RNNs use integrating or spiking neurons -- two classes of computing units whose outputs depend directly on their internal states -- and accordingly there is a wealth of literature characterizing the behavior of large networks built from these neurons. On the other hand, past research on differentiating neurons, whose outputs are computed from the derivatives of their internal states, remains limited to small hand-designed networks with fewer than one-hundred neurons. Here we show via numerical simulation that large lattices of differentiating neuron rings exhibit local neural synchronization behavior found in the Kuramoto model of interacting oscillators. We begin by characterizing the periodic orbits of uncoupled rings, herein called ring oscillators. We then show the emergence of local correlations between oscillators that grow over time when these rings are coupled together into lattices. As the correlation length grows, transient dynamics arise in which large regions of the lattice settle to the same periodic orbit, and thin domain boundaries separate adjacent, out-of-phase regions. The steady-state scale of these correlated regions depends on how the neurons are shared between adjacent rings, which suggests that lattices of differentiating ring oscillator might be tuned to be used as reservoir computers. Coupled with their simple circuit design and potential for low-power consumption, differentiating neural nets therefore represent a promising substrate for neuromorphic computing that will enable low-power AI applications.
Overcoming Slow Decision Frequencies in Continuous Control: Model-Based Sequence Reinforcement Learning for Model-Free Control
Oct 11, 2024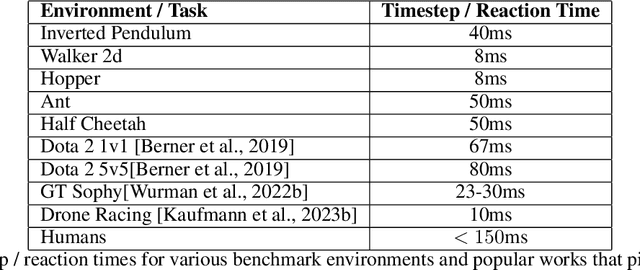
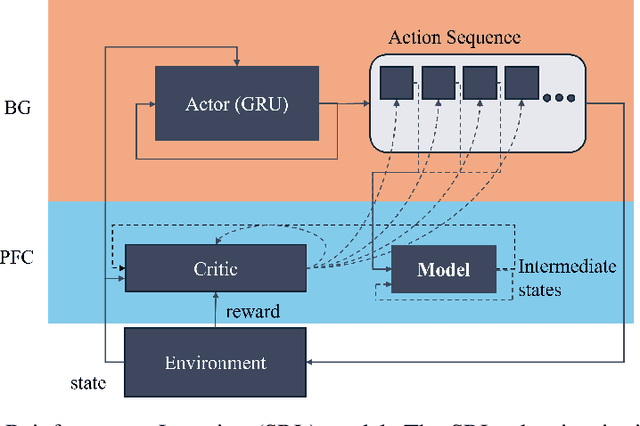
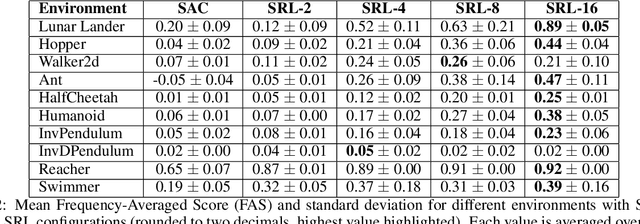
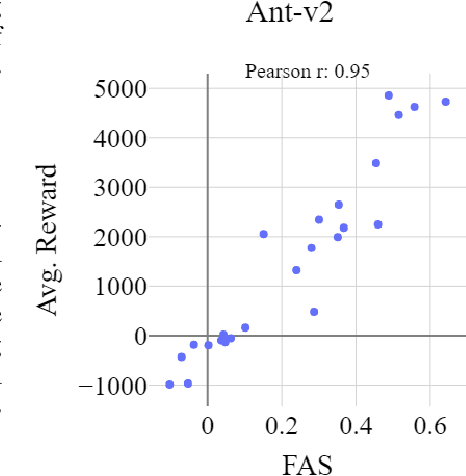
Reinforcement learning (RL) is rapidly reaching and surpassing human-level control capabilities. However, state-of-the-art RL algorithms often require timesteps and reaction times significantly faster than human capabilities, which is impractical in real-world settings and typically necessitates specialized hardware. Such speeds are difficult to achieve in the real world and often requires specialized hardware. We introduce Sequence Reinforcement Learning (SRL), an RL algorithm designed to produce a sequence of actions for a given input state, enabling effective control at lower decision frequencies. SRL addresses the challenges of learning action sequences by employing both a model and an actor-critic architecture operating at different temporal scales. We propose a "temporal recall" mechanism, where the critic uses the model to estimate intermediate states between primitive actions, providing a learning signal for each individual action within the sequence. Once training is complete, the actor can generate action sequences independently of the model, achieving model-free control at a slower frequency. We evaluate SRL on a suite of continuous control tasks, demonstrating that it achieves performance comparable to state-of-the-art algorithms while significantly reducing actor sample complexity. To better assess performance across varying decision frequencies, we introduce the Frequency-Averaged Score (FAS) metric. Our results show that SRL significantly outperforms traditional RL algorithms in terms of FAS, making it particularly suitable for applications requiring variable decision frequencies. Additionally, we compare SRL with model-based online planning, showing that SRL achieves superior FAS while leveraging the same model during training that online planners use for planning.
Temporally Layered Architecture for Efficient Continuous Control
May 30, 2023We present a temporally layered architecture (TLA) for temporally adaptive control with minimal energy expenditure. The TLA layers a fast and a slow policy together to achieve temporal abstraction that allows each layer to focus on a different time scale. Our design draws on the energy-saving mechanism of the human brain, which executes actions at different timescales depending on the environment's demands. We demonstrate that beyond energy saving, TLA provides many additional advantages, including persistent exploration, fewer required decisions, reduced jerk, and increased action repetition. We evaluate our method on a suite of continuous control tasks and demonstrate the significant advantages of TLA over existing methods when measured over multiple important metrics. We also introduce a multi-objective score to qualitatively assess continuous control policies and demonstrate a significantly better score for TLA. Our training algorithm uses minimal communication between the slow and fast layers to train both policies simultaneously, making it viable for future applications in distributed control.
YeLan: Event Camera-Based 3D Human Pose Estimation for Technology-Mediated Dancing in Challenging Environments with Comprehensive Motion-to-Event Simulator
Jan 17, 2023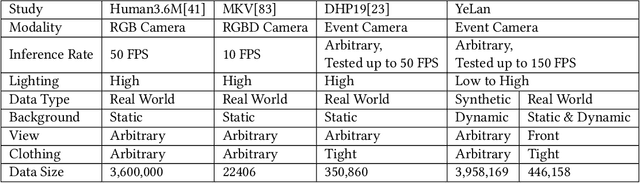



As a beloved sport worldwide, dancing is getting integrated into traditional and virtual reality-based gaming platforms nowadays. It opens up new opportunities in the technology-mediated dancing space. These platforms primarily rely on passive and continuous human pose estimation as an input capture mechanism. Existing solutions are mainly based on RGB or RGB-Depth cameras for dance games. The former suffers in low-lighting conditions due to the motion blur and low sensitivity, while the latter is too power-hungry, has a low frame rate, and has limited working distance. With ultra-low latency, energy efficiency, and wide dynamic range characteristics, the event camera is a promising solution to overcome these shortcomings. We propose YeLan, an event camera-based 3-dimensional human pose estimation(HPE) system that survives low-lighting and dynamic background contents. We collected the world's first event camera dance dataset and developed a fully customizable motion-to-event physics-aware simulator. YeLan outperforms the baseline models in these challenging conditions and demonstrated robustness against different types of clothing, background motion, viewing angle, occlusion, and lighting fluctuations.
Temporally Layered Architecture for Adaptive, Distributed and Continuous Control
Dec 25, 2022We present temporally layered architecture (TLA), a biologically inspired system for temporally adaptive distributed control. TLA layers a fast and a slow controller together to achieve temporal abstraction that allows each layer to focus on a different time-scale. Our design is biologically inspired and draws on the architecture of the human brain which executes actions at different timescales depending on the environment's demands. Such distributed control design is widespread across biological systems because it increases survivability and accuracy in certain and uncertain environments. We demonstrate that TLA can provide many advantages over existing approaches, including persistent exploration, adaptive control, explainable temporal behavior, compute efficiency and distributed control. We present two different algorithms for training TLA: (a) Closed-loop control, where the fast controller is trained over a pre-trained slow controller, allowing better exploration for the fast controller and closed-loop control where the fast controller decides whether to "act-or-not" at each timestep; and (b) Partially open loop control, where the slow controller is trained over a pre-trained fast controller, allowing for open loop-control where the slow controller picks a temporally extended action or defers the next n-actions to the fast controller. We evaluated our method on a suite of continuous control tasks and demonstrate the advantages of TLA over several strong baselines.
QuickNets: Saving Training and Preventing Overconfidence in Early-Exit Neural Architectures
Dec 25, 2022Deep neural networks have long training and processing times. Early exits added to neural networks allow the network to make early predictions using intermediate activations in the network in time-sensitive applications. However, early exits increase the training time of the neural networks. We introduce QuickNets: a novel cascaded training algorithm for faster training of neural networks. QuickNets are trained in a layer-wise manner such that each successive layer is only trained on samples that could not be correctly classified by the previous layers. We demonstrate that QuickNets can dynamically distribute learning and have a reduced training cost and inference cost compared to standard Backpropagation. Additionally, we introduce commitment layers that significantly improve the early exits by identifying for over-confident predictions and demonstrate its success.
Memory via Temporal Delays in weightless Spiking Neural Network
Feb 15, 2022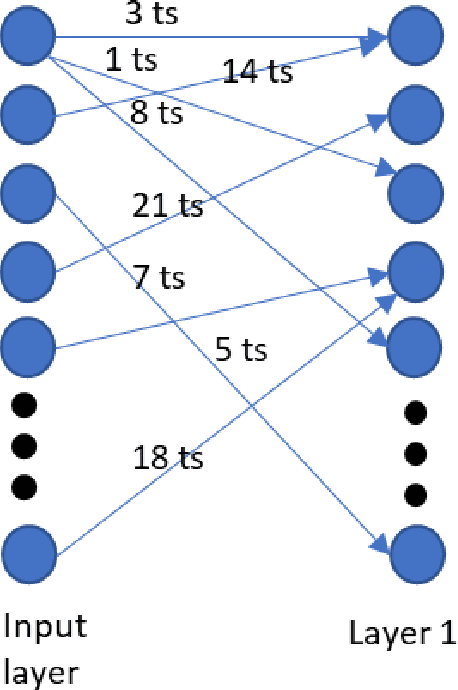
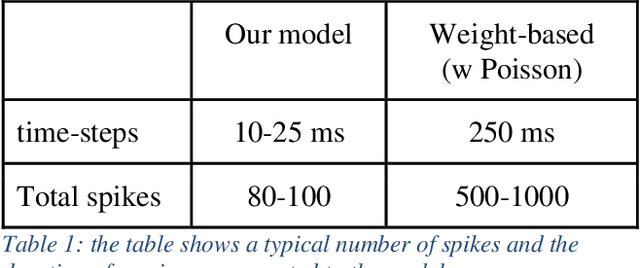

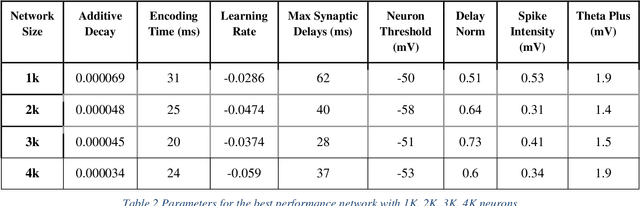
A common view in the neuroscience community is that memory is encoded in the connection strength between neurons. This perception led artificial neural network models to focus on connection weights as the key variables to modulate learning. In this paper, we present a prototype for weightless spiking neural networks that can perform a simple classification task. The memory in this network is stored in the timing between neurons, rather than the strength of the connection, and is trained using a Hebbian Spike Timing Dependent Plasticity (STDP), which modulates the delays of the connection.
Lattice Map Spiking Neural Networks (LM-SNNs) for Clustering and Classifying Image Data
Jun 04, 2019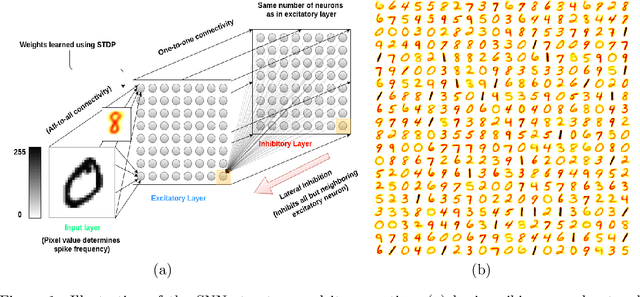

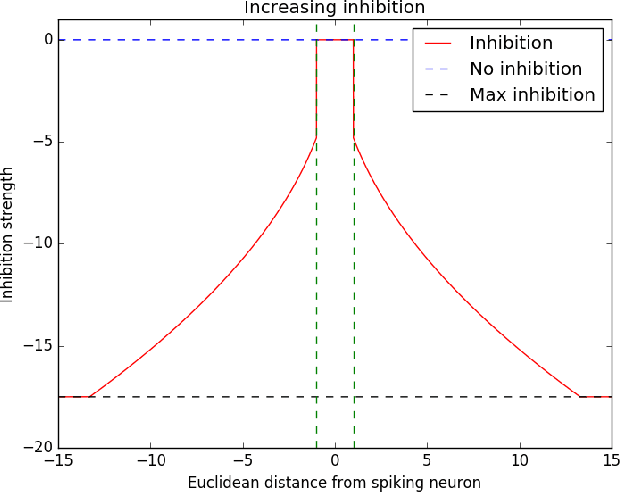
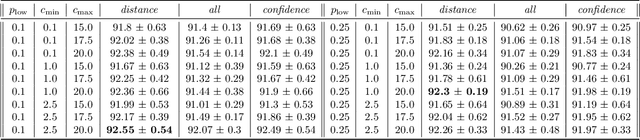
Spiking neural networks (SNNs) with a lattice architecture are introduced in this work, combining several desirable properties of SNNs and self-organized maps (SOMs). Networks are trained with biologically motivated, unsupervised learning rules to obtain a self-organized grid of filters via cooperative and competitive excitatory-inhibitory interactions. Several inhibition strategies are developed and tested, such as (i) incrementally increasing inhibition level over the course of network training, and (ii) switching the inhibition level from low to high (two-level) after an initial training segment. During the labeling phase, the spiking activity generated by data with known labels is used to assign neurons to categories of data, which are then used to evaluate the network's classification ability on a held-out set of test data. Several biologically plausible evaluation rules are proposed and compared, including a population-level confidence rating, and an $n$-gram inspired method. The effectiveness of the proposed self-organized learning mechanism is tested using the MNIST benchmark dataset, as well as using images produced by playing the Atari Breakout game.
Deep Neural Networks Abstract Like Humans
May 27, 2019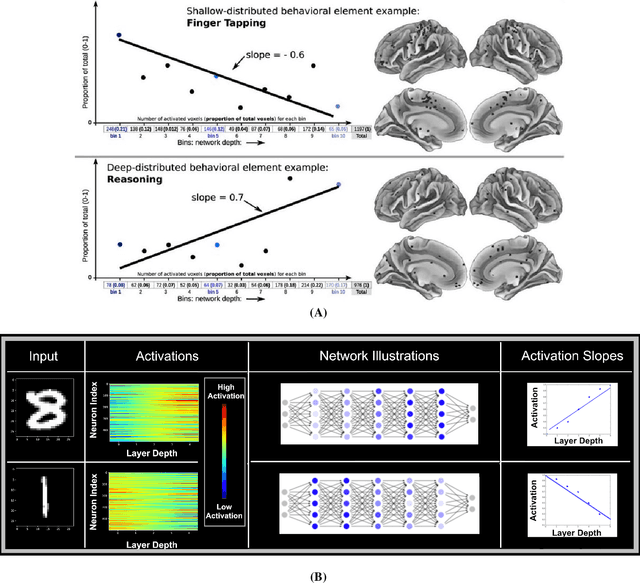
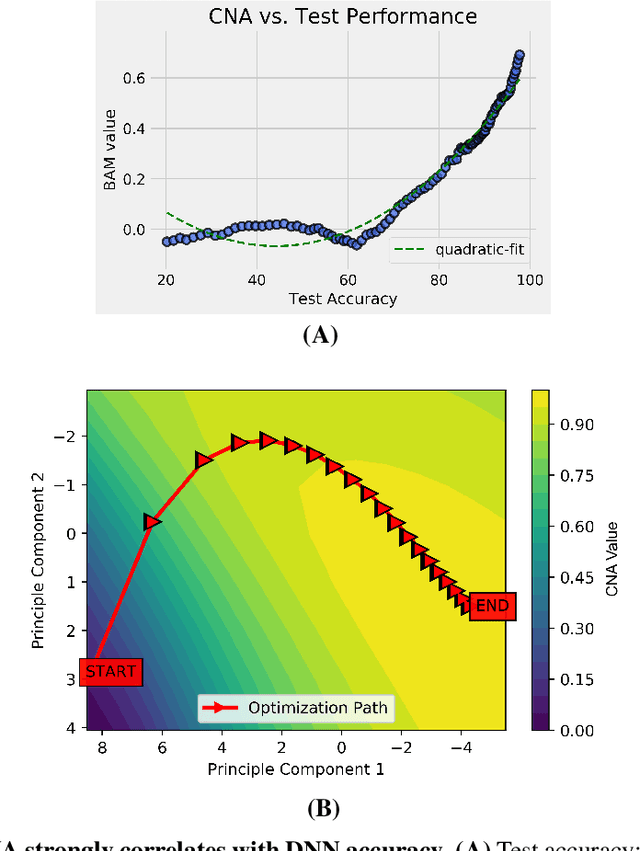
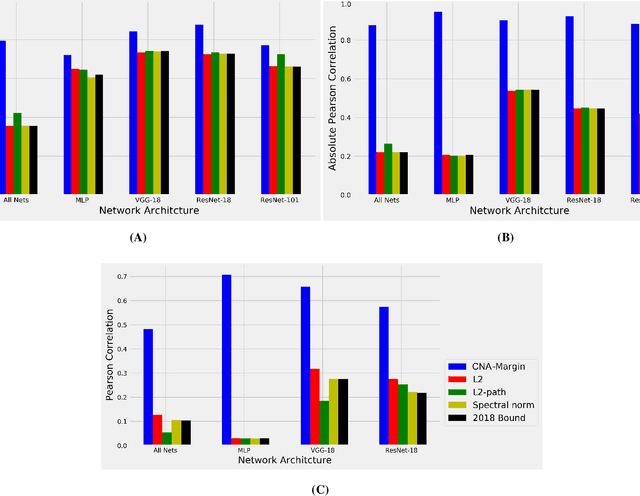
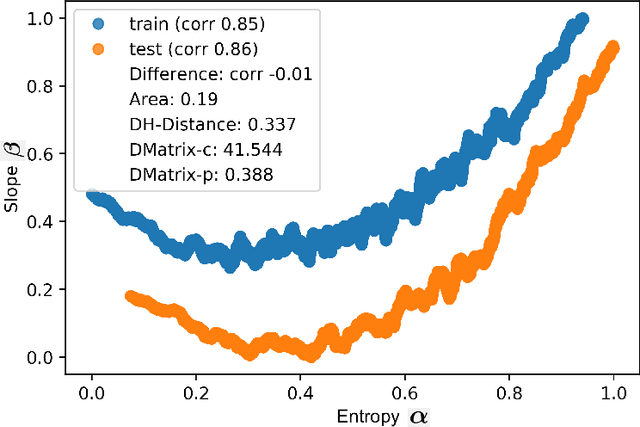
Deep neural networks (DNNs) have revolutionized AI due to their remarkable performance in pattern recognition, comprising of both memorizing complex training sets and demonstrating intelligence by generalizing to previously unseen data (test sets). The high generalization performance in DNNs has been explained by several mathematical tools, including optimization, information theory, and resilience analysis. In humans, it is the ability to abstract concepts from examples that facilitates generalization; this paper thus researches DNN generalization from that perspective. A recent computational neuroscience study revealed a correlation between abstraction and particular neural firing patterns. We express these brain patterns in a closed-form mathematical expression, termed the `Cognitive Neural Activation metric' (CNA) and apply it to DNNs. Our findings reveal parallels in the mechanism underlying abstraction in DNNs and those in the human brain. Beyond simply measuring similarity to human abstraction, the CNA is able to predict and rate how well a DNN will perform on test sets, and determines the best network architectures for a given task in a manner not possible with extant tools. These results were validated on a broad range of datasets (including ImageNet and random labeled datasets) and neural architectures.
Improved robustness of reinforcement learning policies upon conversion to spiking neuronal network platforms applied to ATARI games
Mar 26, 2019
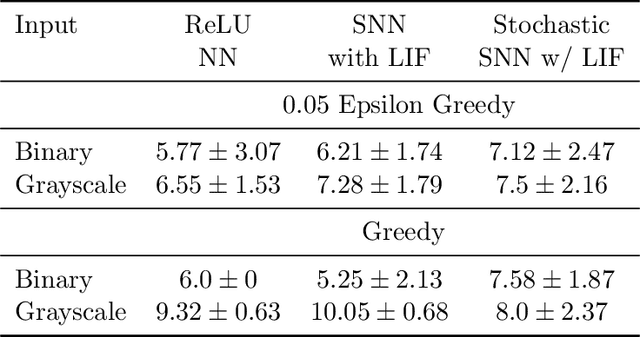
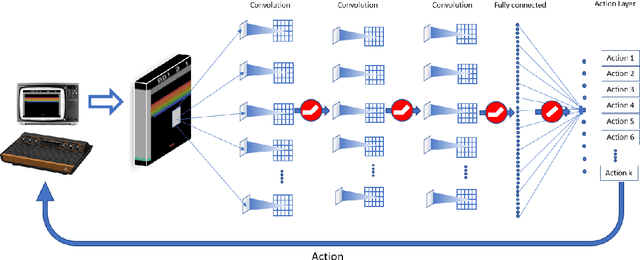
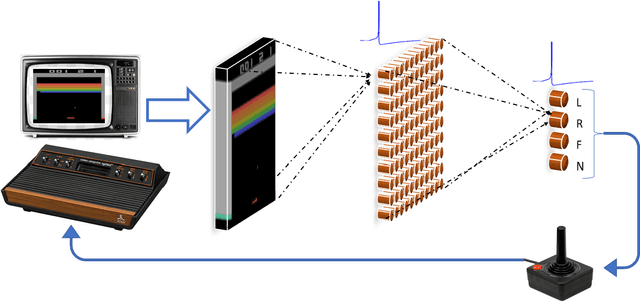
Various implementations of Deep Reinforcement Learning (RL) demonstrated excellent performance on tasks that can be solved by trained policy, but they are not without drawbacks. Deep RL suffers from high sensitivity to noisy and missing input and adversarial attacks. To mitigate these deficiencies of deep RL solutions, we suggest involving spiking neural networks (SNNs). Previous work has shown that standard Neural Networks trained using supervised learning for image classification can be converted to SNNs with negligible deterioration in performance. In this paper, we convert Q-Learning ReLU-Networks (ReLU-N) trained using reinforcement learning into SNN. We provide a proof of concept for the conversion of ReLU-N to SNN demonstrating improved robustness to occlusion and better generalization than the original ReLU-N. Moreover, we show promising initial results with converting full-scale Deep Q-networks to SNNs, paving the way for future research.