 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOvercoming Slow Decision Frequencies in Continuous Control: Model-Based Sequence Reinforcement Learning for Model-Free Control
Oct 11, 2024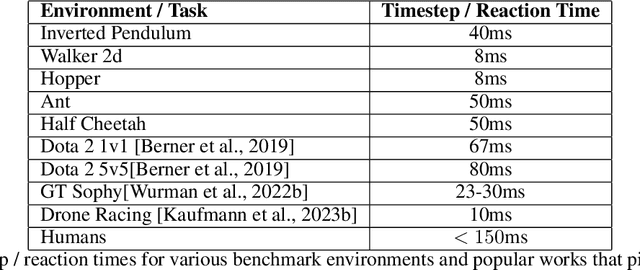
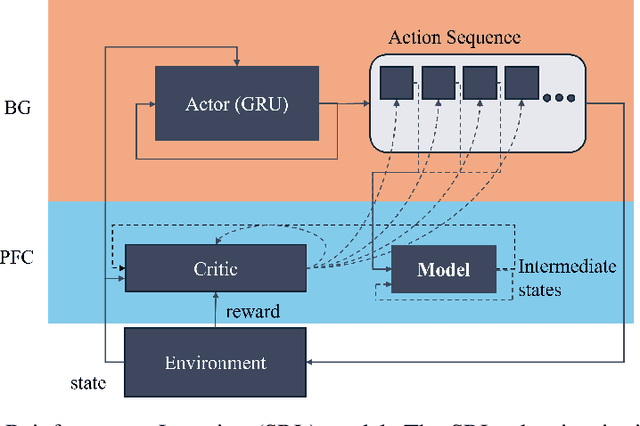
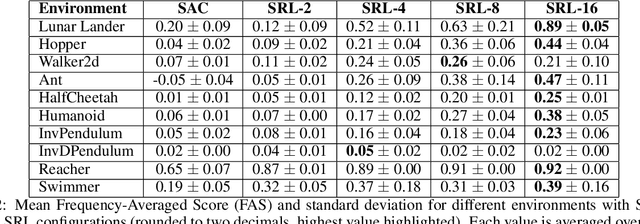
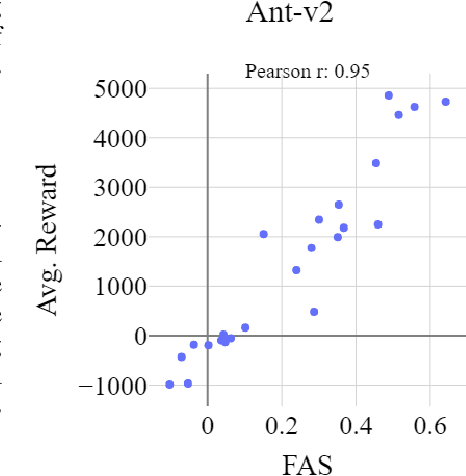
Reinforcement learning (RL) is rapidly reaching and surpassing human-level control capabilities. However, state-of-the-art RL algorithms often require timesteps and reaction times significantly faster than human capabilities, which is impractical in real-world settings and typically necessitates specialized hardware. Such speeds are difficult to achieve in the real world and often requires specialized hardware. We introduce Sequence Reinforcement Learning (SRL), an RL algorithm designed to produce a sequence of actions for a given input state, enabling effective control at lower decision frequencies. SRL addresses the challenges of learning action sequences by employing both a model and an actor-critic architecture operating at different temporal scales. We propose a "temporal recall" mechanism, where the critic uses the model to estimate intermediate states between primitive actions, providing a learning signal for each individual action within the sequence. Once training is complete, the actor can generate action sequences independently of the model, achieving model-free control at a slower frequency. We evaluate SRL on a suite of continuous control tasks, demonstrating that it achieves performance comparable to state-of-the-art algorithms while significantly reducing actor sample complexity. To better assess performance across varying decision frequencies, we introduce the Frequency-Averaged Score (FAS) metric. Our results show that SRL significantly outperforms traditional RL algorithms in terms of FAS, making it particularly suitable for applications requiring variable decision frequencies. Additionally, we compare SRL with model-based online planning, showing that SRL achieves superior FAS while leveraging the same model during training that online planners use for planning.
Temporally Layered Architecture for Efficient Continuous Control
May 30, 2023We present a temporally layered architecture (TLA) for temporally adaptive control with minimal energy expenditure. The TLA layers a fast and a slow policy together to achieve temporal abstraction that allows each layer to focus on a different time scale. Our design draws on the energy-saving mechanism of the human brain, which executes actions at different timescales depending on the environment's demands. We demonstrate that beyond energy saving, TLA provides many additional advantages, including persistent exploration, fewer required decisions, reduced jerk, and increased action repetition. We evaluate our method on a suite of continuous control tasks and demonstrate the significant advantages of TLA over existing methods when measured over multiple important metrics. We also introduce a multi-objective score to qualitatively assess continuous control policies and demonstrate a significantly better score for TLA. Our training algorithm uses minimal communication between the slow and fast layers to train both policies simultaneously, making it viable for future applications in distributed control.
Temporally Layered Architecture for Adaptive, Distributed and Continuous Control
Dec 25, 2022We present temporally layered architecture (TLA), a biologically inspired system for temporally adaptive distributed control. TLA layers a fast and a slow controller together to achieve temporal abstraction that allows each layer to focus on a different time-scale. Our design is biologically inspired and draws on the architecture of the human brain which executes actions at different timescales depending on the environment's demands. Such distributed control design is widespread across biological systems because it increases survivability and accuracy in certain and uncertain environments. We demonstrate that TLA can provide many advantages over existing approaches, including persistent exploration, adaptive control, explainable temporal behavior, compute efficiency and distributed control. We present two different algorithms for training TLA: (a) Closed-loop control, where the fast controller is trained over a pre-trained slow controller, allowing better exploration for the fast controller and closed-loop control where the fast controller decides whether to "act-or-not" at each timestep; and (b) Partially open loop control, where the slow controller is trained over a pre-trained fast controller, allowing for open loop-control where the slow controller picks a temporally extended action or defers the next n-actions to the fast controller. We evaluated our method on a suite of continuous control tasks and demonstrate the advantages of TLA over several strong baselines.
QuickNets: Saving Training and Preventing Overconfidence in Early-Exit Neural Architectures
Dec 25, 2022Deep neural networks have long training and processing times. Early exits added to neural networks allow the network to make early predictions using intermediate activations in the network in time-sensitive applications. However, early exits increase the training time of the neural networks. We introduce QuickNets: a novel cascaded training algorithm for faster training of neural networks. QuickNets are trained in a layer-wise manner such that each successive layer is only trained on samples that could not be correctly classified by the previous layers. We demonstrate that QuickNets can dynamically distribute learning and have a reduced training cost and inference cost compared to standard Backpropagation. Additionally, we introduce commitment layers that significantly improve the early exits by identifying for over-confident predictions and demonstrate its success.
Strategy and Benchmark for Converting Deep Q-Networks to Event-Driven Spiking Neural Networks
Sep 30, 2020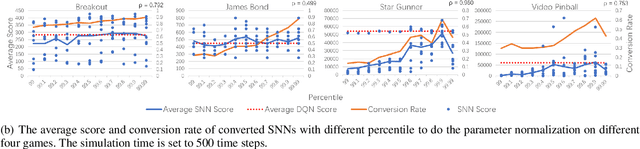
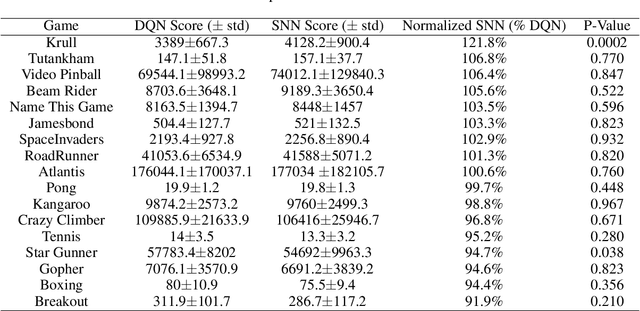
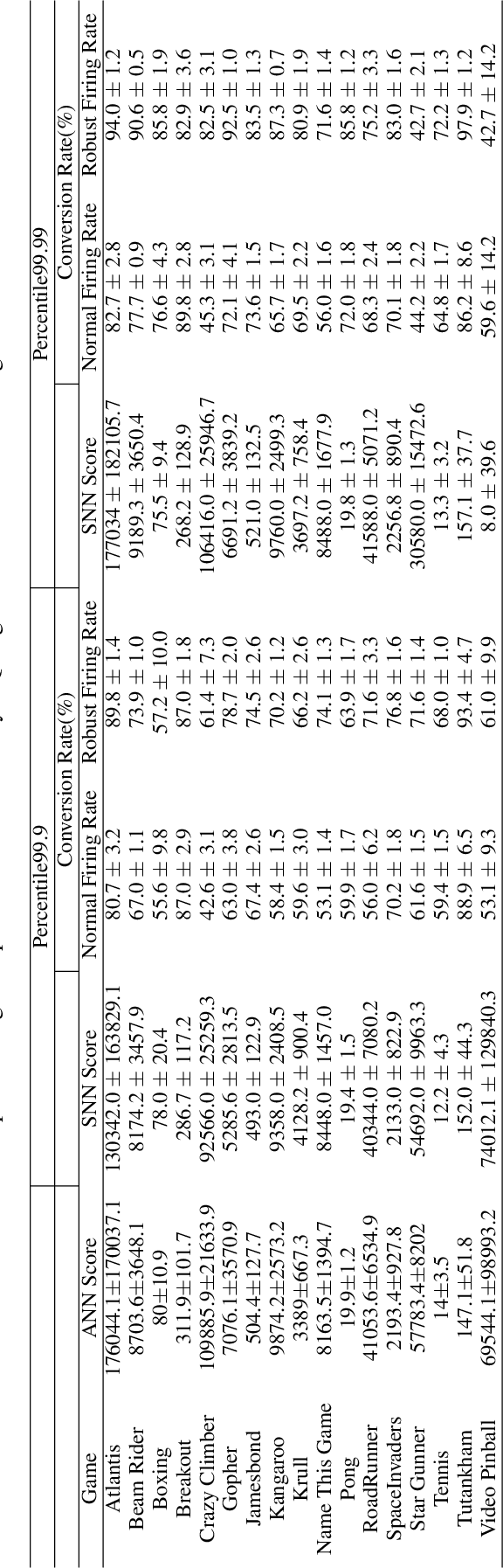
Spiking neural networks (SNNs) have great potential for energy-efficient implementation of Deep Neural Networks (DNNs) on dedicated neuromorphic hardware. Recent studies demonstrated competitive performance of SNNs compared with DNNs on image classification tasks, including CIFAR-10 and ImageNet data. The present work focuses on using SNNs in combination with deep reinforcement learning in ATARI games, which involves additional complexity as compared to image classification. We review the theory of converting DNNs to SNNs and extending the conversion to Deep Q-Networks (DQNs). We propose a robust representation of the firing rate to reduce the error during the conversion process. In addition, we introduce a new metric to evaluate the conversion process by comparing the decisions made by the DQN and SNN, respectively. We also analyze how the simulation time and parameter normalization influence the performance of converted SNNs. We achieve competitive scores on 17 top-performing Atari games. To the best of our knowledge, our work is the first to achieve state-of-the-art performance on multiple Atari games with SNNs. Our work serves as a benchmark for the conversion of DQNs to SNNs and paves the way for further research on solving reinforcement learning tasks with SNNs.
Locally Connected Spiking Neural Networks for Unsupervised Feature Learning
Apr 12, 2019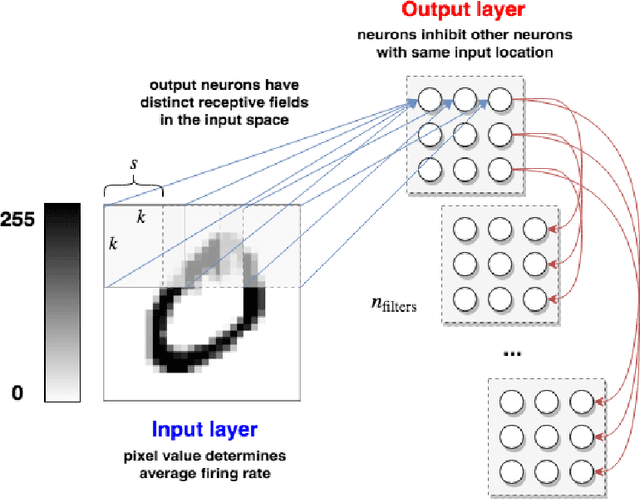
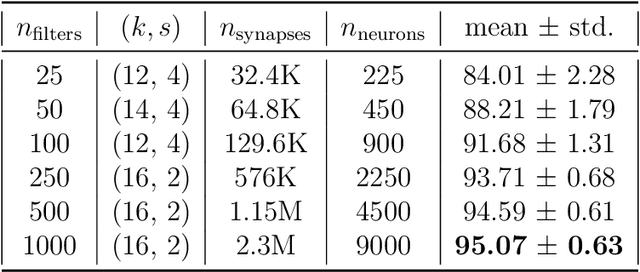
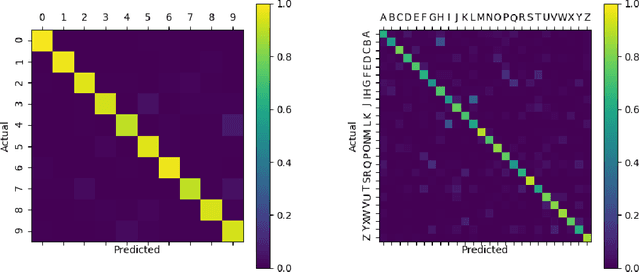
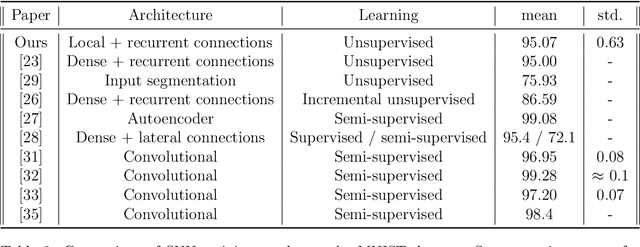
In recent years, Spiking Neural Networks (SNNs) have demonstrated great successes in completing various Machine Learning tasks. We introduce a method for learning image features by \textit{locally connected layers} in SNNs using spike-timing-dependent plasticity (STDP) rule. In our approach, sub-networks compete via competitive inhibitory interactions to learn features from different locations of the input space. These \textit{Locally-Connected SNNs} (LC-SNNs) manifest key topological features of the spatial interaction of biological neurons. We explore biologically inspired n-gram classification approach allowing parallel processing over various patches of the the image space. We report the classification accuracy of simple two-layer LC-SNNs on two image datasets, which match the state-of-art performance and are the first results to date. LC-SNNs have the advantage of fast convergence to a dataset representation, and they require fewer learnable parameters than other SNN approaches with unsupervised learning. Robustness tests demonstrate that LC-SNNs exhibit graceful degradation of performance despite the random deletion of large amounts of synapses and neurons.
Improved robustness of reinforcement learning policies upon conversion to spiking neuronal network platforms applied to ATARI games
Mar 26, 2019
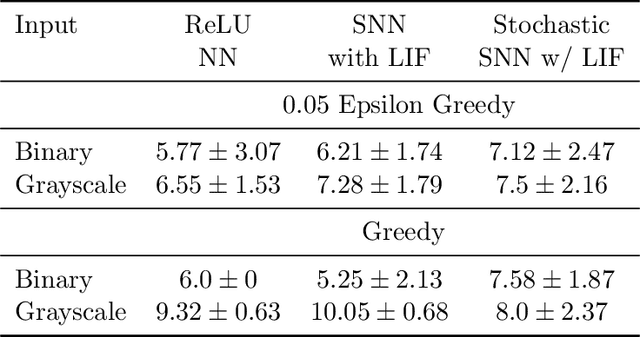
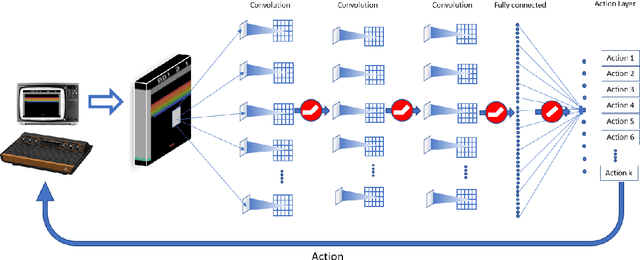
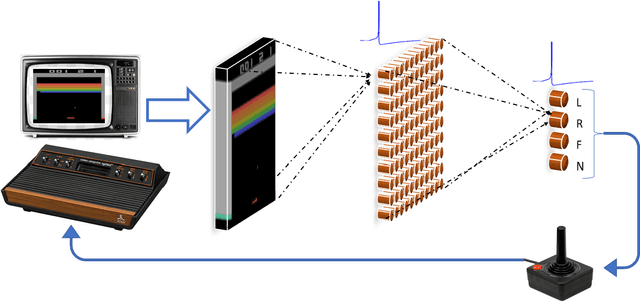
Various implementations of Deep Reinforcement Learning (RL) demonstrated excellent performance on tasks that can be solved by trained policy, but they are not without drawbacks. Deep RL suffers from high sensitivity to noisy and missing input and adversarial attacks. To mitigate these deficiencies of deep RL solutions, we suggest involving spiking neural networks (SNNs). Previous work has shown that standard Neural Networks trained using supervised learning for image classification can be converted to SNNs with negligible deterioration in performance. In this paper, we convert Q-Learning ReLU-Networks (ReLU-N) trained using reinforcement learning into SNN. We provide a proof of concept for the conversion of ReLU-N to SNN demonstrating improved robustness to occlusion and better generalization than the original ReLU-N. Moreover, we show promising initial results with converting full-scale Deep Q-networks to SNNs, paving the way for future research.