 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen RL Suppresses Its Own Vocabulary: Recovering Reasoning Diversity in Puzzle-to-Math Transfer
May 28, 2026Reinforcement learning using verifiable rewards (RLVR) improves LLM reasoning, but the conditions under which it transfers across domains -- and why it does so -- remain under-explored. We study cross-domain transfer in a 7B model whose SFT and RL post-training stages use only constraint-satisfaction puzzles, with no mathematics problems in the post-training data. To analyze how transfer emerges, we introduce a reasoning primitive-level framework that combines a 9-class span classifier with motif extraction, allowing us to segment chain-of-thought traces into primitive motifs and track their evolution across training stages and domains. We find that puzzle SFT induces a reasoning-primitive vocabulary, yielding a $+7$pp \texttt{pass@32} gain on OlymMATH-Hard. Vanilla GSPO then composes these primitives into longer compute-verify chains, adding a further $+6$pp. However, this RL stage also suppresses exploratory primitives such as \textit{hypothesize} and \textit{backtrack}. To address this, we introduce a novelty bonus that rewards diverse correct rollouts, using perplexity under the reference model as a signal. This restores recovery primitives during RL and adds a further $+7$pp \texttt{pass@32} relative to vanilla GSPO. Finally, the end-to-end recipe raises the hard-math capability ceiling from $16.0\%$ at the OLMo3-7B-Instruct-SFT base to $36.0\%$, without adding any mathematics problems during the SFT or RL stages.
NeuroAI and Beyond
Jan 27, 2026Neuroscience and Artificial Intelligence (AI) have made significant progress in the past few years but have only been loosely inter-connected. Based on a workshop held in August 2025, we identify current and future areas of synergism between these two fields. We focus on the subareas of embodiment, language and communication, robotics, learning in humans and machines and Neuromorphic engineering to take stock of the progress made so far, and possible promising new future avenues. Overall, we advocate for the development of NeuroAI, a type of Neuroscience-informed Artificial Intelligence that, we argue, has the potential for significantly improving the scope and efficiency of AI algorithms while simultaneously changing the way we understand biological neural computations. We include personal statements from several leading researchers on their diverse views of NeuroAI. Two Strength-Weakness-Opportunities-Threat (SWOT) analyses by researchers and trainees are appended that describe the benefits and risks offered by NeuroAI.
Traveling Waves Encode the Recent Past and Enhance Sequence Learning
Sep 03, 2023



Traveling waves of neural activity have been observed throughout the brain at a diversity of regions and scales; however, their precise computational role is still debated. One physically grounded hypothesis suggests that the cortical sheet may act like a wave-field capable of storing a short-term memory of sequential stimuli through induced waves traveling across the cortical surface. To date, however, the computational implications of this idea have remained hypothetical due to the lack of a simple recurrent neural network architecture capable of exhibiting such waves. In this work, we introduce a model to fill this gap, which we denote the Wave-RNN (wRNN), and demonstrate how both connectivity constraints and initialization play a crucial role in the emergence of wave-like dynamics. We then empirically show how such an architecture indeed efficiently encodes the recent past through a suite of synthetic memory tasks where wRNNs learn faster and perform significantly better than wave-free counterparts. Finally, we explore the implications of this memory storage system on more complex sequence modeling tasks such as sequential image classification and find that wave-based models not only again outperform comparable wave-free RNNs while using significantly fewer parameters, but additionally perform comparably to more complex gated architectures such as LSTMs and GRUs. We conclude with a discussion of the implications of these results for both neuroscience and machine learning.
Temporally Layered Architecture for Efficient Continuous Control
May 30, 2023We present a temporally layered architecture (TLA) for temporally adaptive control with minimal energy expenditure. The TLA layers a fast and a slow policy together to achieve temporal abstraction that allows each layer to focus on a different time scale. Our design draws on the energy-saving mechanism of the human brain, which executes actions at different timescales depending on the environment's demands. We demonstrate that beyond energy saving, TLA provides many additional advantages, including persistent exploration, fewer required decisions, reduced jerk, and increased action repetition. We evaluate our method on a suite of continuous control tasks and demonstrate the significant advantages of TLA over existing methods when measured over multiple important metrics. We also introduce a multi-objective score to qualitatively assess continuous control policies and demonstrate a significantly better score for TLA. Our training algorithm uses minimal communication between the slow and fast layers to train both policies simultaneously, making it viable for future applications in distributed control.
Toward Next-Generation Artificial Intelligence: Catalyzing the NeuroAI Revolution
Oct 15, 2022Neuroscience has long been an important driver of progress in artificial intelligence (AI). We propose that to accelerate progress in AI, we must invest in fundamental research in NeuroAI.
Large Language Models and the Reverse Turing Test
Aug 10, 2022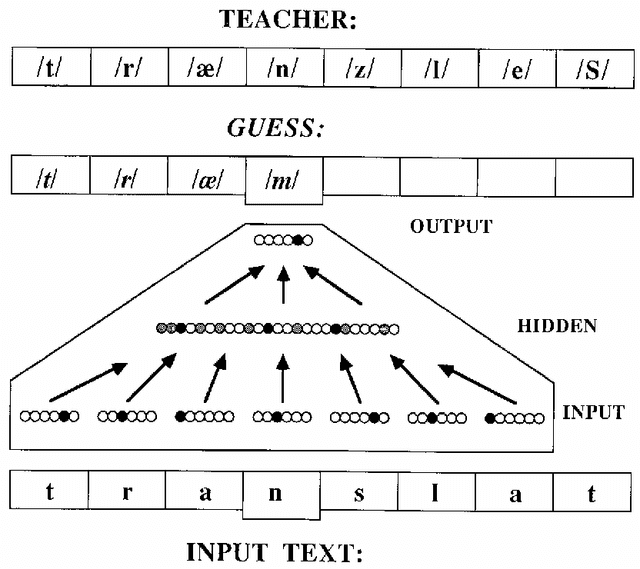
Large Language Models (LLMs) have been transformative. They are pre-trained foundational models that can be adapted with fine tuning to many different natural language tasks, each of which previously would have required a separate network model. This is one step closer to the extraordinary versatility of human language. GPT-3 and more recently LaMDA can carry on dialogs with humans on many topics after minimal priming with a few examples. However, there has been a wide range of reactions on whether these LLMs understand what they are saying or exhibit signs of intelligence. This high variance is exhibited in three interviews with LLMs reaching wildly different conclusions. A new possibility was uncovered that could explain this divergence. What appears to be intelligence in LLMs may in fact be a mirror that reflects the intelligence of the interviewer, a remarkable twist that could be considered a Reverse Turing Test. If so, then by studying interviews we may be learning more about the intelligence and beliefs of the interviewer than the intelligence of the LLMs. As LLMs become more capable they may transform the way we access and use information.
Physics-based machine learning for modeling stochastic IP3-dependent calcium dynamics
Sep 10, 2021

We present a machine learning method for model reduction which incorporates domain-specific physics through candidate functions. Our method estimates an effective probability distribution and differential equation model from stochastic simulations of a reaction network. The close connection between reduced and fine scale descriptions allows approximations derived from the master equation to be introduced into the learning problem. This representation is shown to improve generalization and allows a large reduction in network size for a classic model of inositol trisphosphate (IP3) dependent calcium oscillations in non-excitable cells.
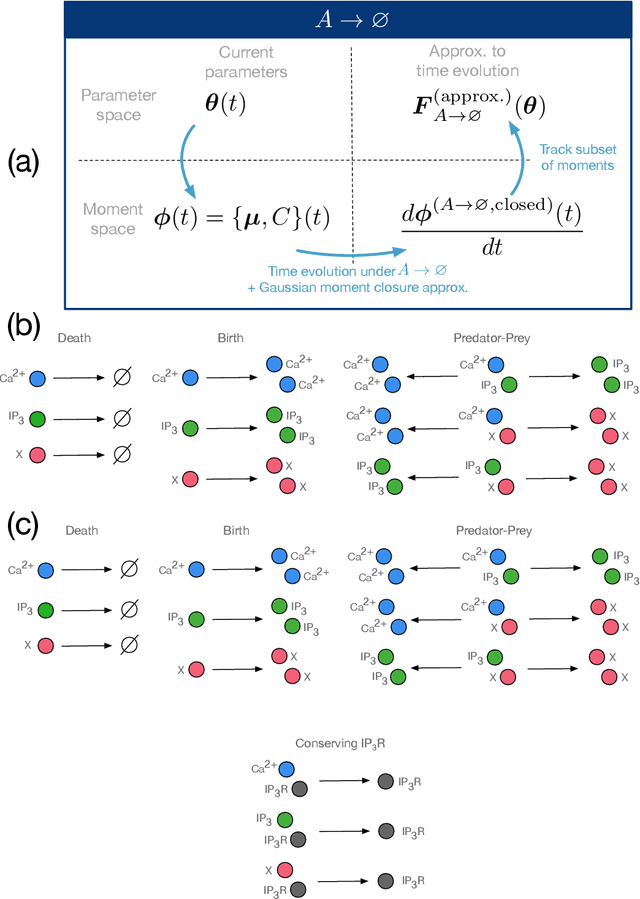
Deep Learning Moment Closure Approximations using Dynamic Boltzmann Distributions
May 28, 2019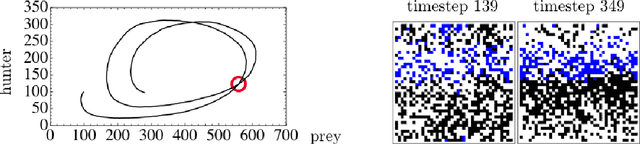
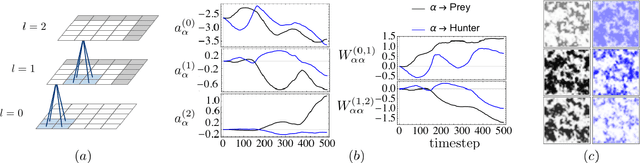
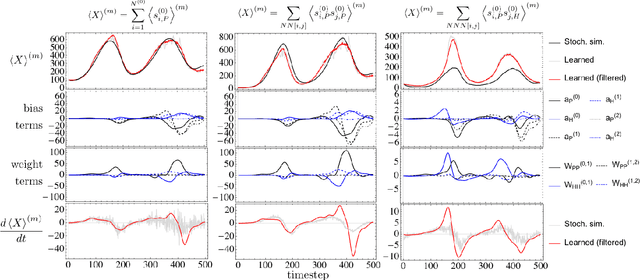
The moments of spatial probabilistic systems are often given by an infinite hierarchy of coupled differential equations. Moment closure methods are used to approximate a subset of low order moments by terminating the hierarchy at some order and replacing higher order terms with functions of lower order ones. For a given system, it is not known beforehand which closure approximation is optimal, i.e. which higher order terms are relevant in the current regime. Further, the generalization of such approximations is typically poor, as higher order corrections may become relevant over long timescales. We have developed a method to learn moment closure approximations directly from data using dynamic Boltzmann distributions (DBDs). The dynamics of the distribution are parameterized using basis functions from finite element methods, such that the approach can be applied without knowing the true dynamics of the system under consideration. We use the hierarchical architecture of deep Boltzmann machines (DBMs) with multinomial latent variables to learn closure approximations for progressively higher order spatial correlations. The learning algorithm uses a centering transformation, allowing the dynamic DBM to be trained without the need for pre-training. We demonstrate the method for a Lotka-Volterra system on a lattice, a typical example in spatial chemical reaction networks. The approach can be applied broadly to learn deep generative models in applications where infinite systems of differential equations arise.