 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraveling Waves Integrate Spatial Information Into Spectral Representations
Feb 09, 2025Traveling waves are widely observed in the brain, but their precise computational function remains unclear. One prominent hypothesis is that they enable the transfer and integration of spatial information across neural populations. However, few computational models have explored how traveling waves might be harnessed to perform such integrative processing. Drawing inspiration from the famous ``Can one hear the shape of a drum?'' problem -- which highlights how spectral modes encode geometric information -- we introduce a set of convolutional recurrent neural networks that learn to produce traveling waves in their hidden states in response to visual stimuli. By applying a spectral decomposition to these wave-like activations, we obtain a powerful new representational space that outperforms equivalently local feed-forward networks on tasks requiring global spatial context. In particular, we observe that traveling waves effectively expand the receptive field of locally connected neurons, supporting long-range encoding and communication of information. We demonstrate that models equipped with this mechanism and spectral readouts solve visual semantic segmentation tasks demanding global integration, where local feed-forward models fail. As a first step toward traveling-wave-based representations in artificial networks, our findings suggest potential efficiency benefits and offer a new framework for connecting to biological recordings of neural activity.
Transformers and Cortical Waves: Encoders for Pulling In Context Across Time
Jan 25, 2024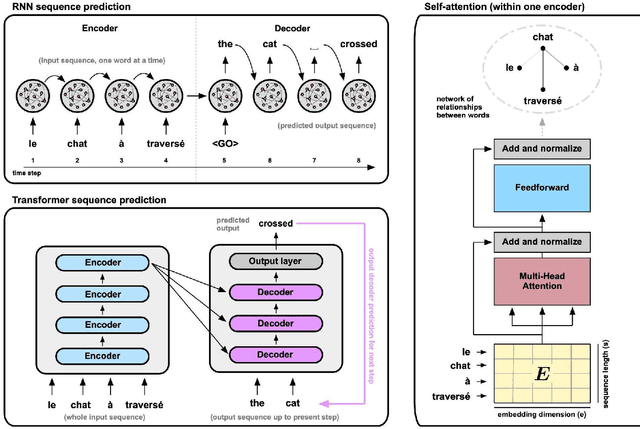
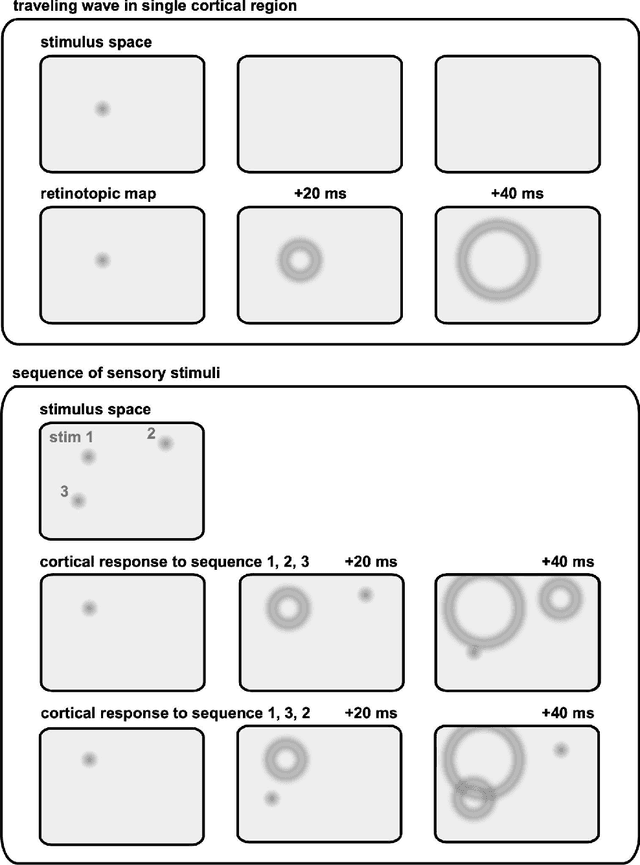
The capabilities of transformer networks such as ChatGPT and other Large Language Models (LLMs) have captured the world's attention. The crucial computational mechanism underlying their performance relies on transforming a complete input sequence - for example, all the words in a sentence into a long "encoding vector" - that allows transformers to learn long-range temporal dependencies in naturalistic sequences. Specifically, "self-attention" applied to this encoding vector enhances temporal context in transformers by computing associations between pairs of words in the input sequence. We suggest that waves of neural activity, traveling across single cortical regions or across multiple regions at the whole-brain scale, could implement a similar encoding principle. By encapsulating recent input history into a single spatial pattern at each moment in time, cortical waves may enable temporal context to be extracted from sequences of sensory inputs, the same computational principle used in transformers.
Traveling Waves Encode the Recent Past and Enhance Sequence Learning
Sep 03, 2023



Traveling waves of neural activity have been observed throughout the brain at a diversity of regions and scales; however, their precise computational role is still debated. One physically grounded hypothesis suggests that the cortical sheet may act like a wave-field capable of storing a short-term memory of sequential stimuli through induced waves traveling across the cortical surface. To date, however, the computational implications of this idea have remained hypothetical due to the lack of a simple recurrent neural network architecture capable of exhibiting such waves. In this work, we introduce a model to fill this gap, which we denote the Wave-RNN (wRNN), and demonstrate how both connectivity constraints and initialization play a crucial role in the emergence of wave-like dynamics. We then empirically show how such an architecture indeed efficiently encodes the recent past through a suite of synthetic memory tasks where wRNNs learn faster and perform significantly better than wave-free counterparts. Finally, we explore the implications of this memory storage system on more complex sequence modeling tasks such as sequential image classification and find that wave-based models not only again outperform comparable wave-free RNNs while using significantly fewer parameters, but additionally perform comparably to more complex gated architectures such as LSTMs and GRUs. We conclude with a discussion of the implications of these results for both neuroscience and machine learning.
Characterization and Compensation of Network-Level Anomalies in Mixed-Signal Neuromorphic Modeling Platforms
Feb 10, 2015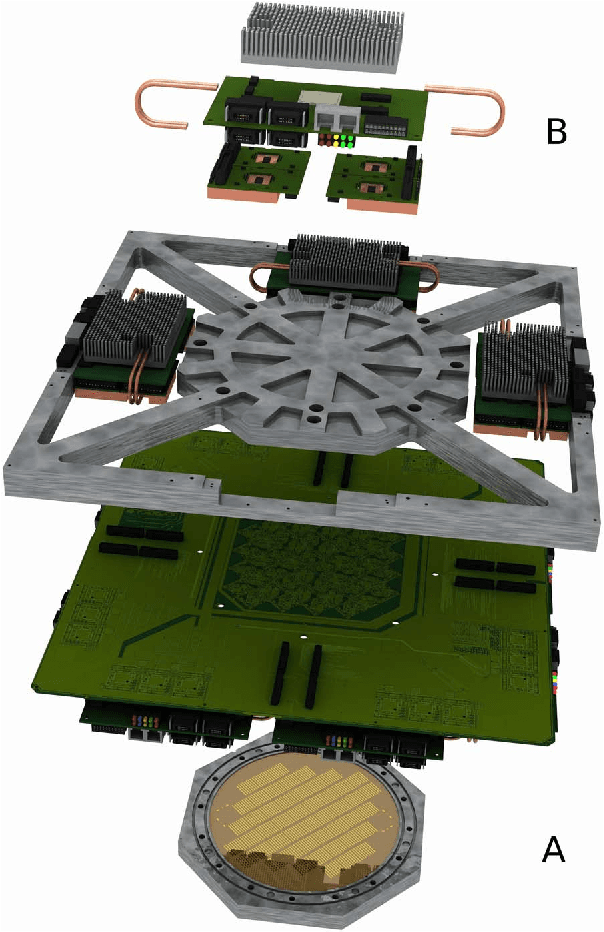

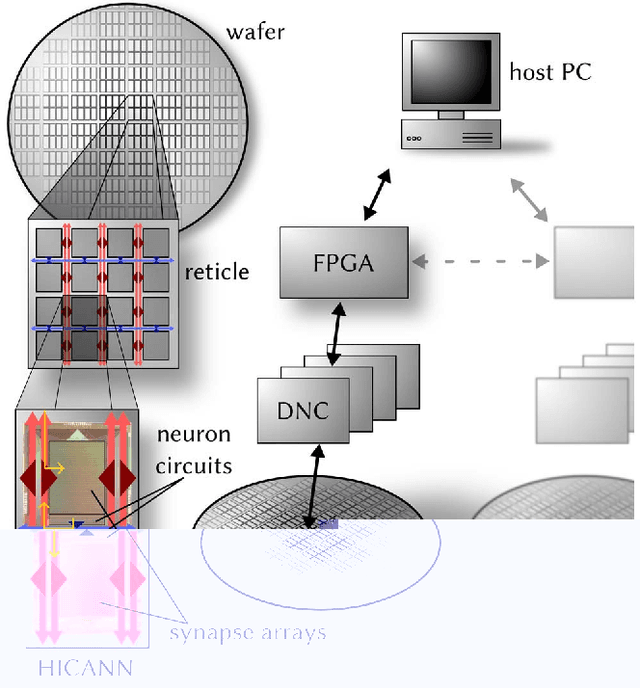
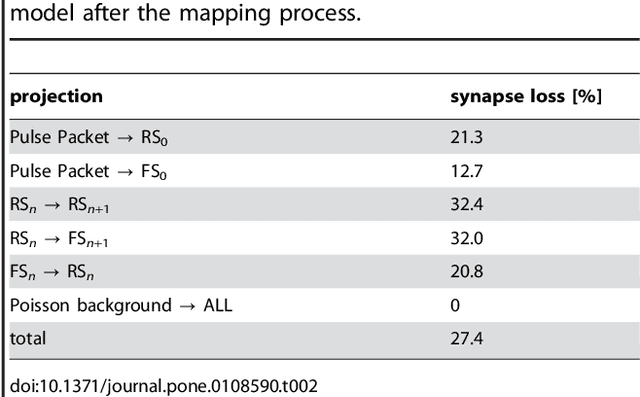
Advancing the size and complexity of neural network models leads to an ever increasing demand for computational resources for their simulation. Neuromorphic devices offer a number of advantages over conventional computing architectures, such as high emulation speed or low power consumption, but this usually comes at the price of reduced configurability and precision. In this article, we investigate the consequences of several such factors that are common to neuromorphic devices, more specifically limited hardware resources, limited parameter configurability and parameter variations. Our final aim is to provide an array of methods for coping with such inevitable distortion mechanisms. As a platform for testing our proposed strategies, we use an executable system specification (ESS) of the BrainScaleS neuromorphic system, which has been designed as a universal emulation back-end for neuroscientific modeling. We address the most essential limitations of this device in detail and study their effects on three prototypical benchmark network models within a well-defined, systematic workflow. For each network model, we start by defining quantifiable functionality measures by which we then assess the effects of typical hardware-specific distortion mechanisms, both in idealized software simulations and on the ESS. For those effects that cause unacceptable deviations from the original network dynamics, we suggest generic compensation mechanisms and demonstrate their effectiveness. Both the suggested workflow and the investigated compensation mechanisms are largely back-end independent and do not require additional hardware configurability beyond the one required to emulate the benchmark networks in the first place. We hereby provide a generic methodological environment for configurable neuromorphic devices that are targeted at emulating large-scale, functional neural networks.