 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Heuristic Neuromorphic Solver for the Edge User Allocation Problem with Bayesian Confidence Propagation Neural Network
Feb 01, 2026We propose a neuromorphic solver for the NP-hard Edge User Allocation problem using an attractor network with Winner-Takes-All (WTA) mechanism implemented with the Bayesian Confidence Propagation Neural Network (BCPNN) framework. Unlike previous energy-based attractor networks, our solver uses dynamic heuristic biasing to guide allocations in real time and introduces a "no allocation" state to each WTA motif, achieving near-optimal performance with an empirically upper-bounded number of time steps. The approach is compatible with neuromorphic architectures and may offer improvements in energy efficiency.
A Reconfigurable Stream-Based FPGA Accelerator for Bayesian Confidence Propagation Neural Networks
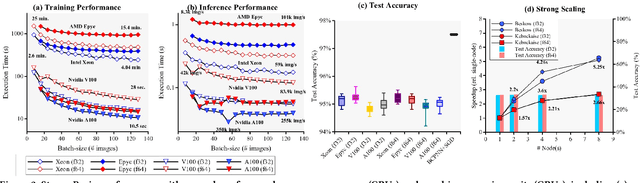
Mar 03, 2025Brain-inspired algorithms are attractive and emerging alternatives to classical deep learning methods for use in various machine learning applications. Brain-inspired systems can feature local learning rules, both unsupervised/semi-supervised learning and different types of plasticity (structural/synaptic), allowing them to potentially be faster and more energy-efficient than traditional machine learning alternatives. Among the more salient brain-inspired algorithms are Bayesian Confidence Propagation Neural Networks (BCPNNs). BCPNN is an important tool for both machine learning and computational neuroscience research, and recent work shows that BCPNN can reach state-of-the-art performance in tasks such as learning and memory recall compared to other models. Unfortunately, BCPNN is primarily executed on slow general-purpose processors (CPUs) or power-hungry graphics processing units (GPUs), reducing the applicability of using BCPNN in (among others) Edge systems. In this work, we design a custom stream-based accelerator for BCPNN using Field-Programmable Gate Arrays (FPGA) using Xilinx Vitis High-Level Synthesis (HLS) flow. Furthermore, we model our accelerator's performance using first principles, and we empirically show that our proposed accelerator is between 1.3x - 5.3x faster than an Nvidia A100 GPU while at the same time consuming between 2.62x - 3.19x less power and 5.8x - 16.5x less energy without any degradation in performance.
Spiking representation learning for associative memories
Jun 05, 2024



Networks of interconnected neurons communicating through spiking signals offer the bedrock of neural computations. Our brains spiking neural networks have the computational capacity to achieve complex pattern recognition and cognitive functions effortlessly. However, solving real-world problems with artificial spiking neural networks (SNNs) has proved to be difficult for a variety of reasons. Crucially, scaling SNNs to large networks and processing large-scale real-world datasets have been challenging, especially when compared to their non-spiking deep learning counterparts. The critical operation that is needed of SNNs is the ability to learn distributed representations from data and use these representations for perceptual, cognitive and memory operations. In this work, we introduce a novel SNN that performs unsupervised representation learning and associative memory operations leveraging Hebbian synaptic and activity-dependent structural plasticity coupled with neuron-units modelled as Poisson spike generators with sparse firing (~1 Hz mean and ~100 Hz maximum firing rate). Crucially, the architecture of our model derives from the neocortical columnar organization and combines feedforward projections for learning hidden representations and recurrent projections for forming associative memories. We evaluated the model on properties relevant for attractor-based associative memories such as pattern completion, perceptual rivalry, distortion resistance, and prototype extraction.
Benchmarking Hebbian learning rules for associative memory
Dec 30, 2023


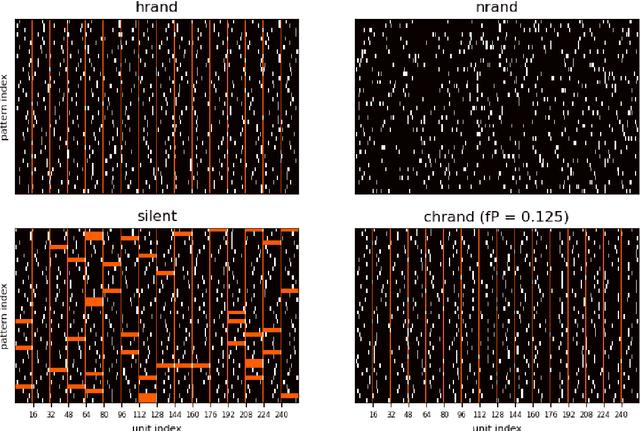
Associative memory or content addressable memory is an important component function in computer science and information processing and is a key concept in cognitive and computational brain science. Many different neural network architectures and learning rules have been proposed to model associative memory of the brain while investigating key functions like pattern completion and rivalry, noise reduction, and storage capacity. A less investigated but important function is prototype extraction where the training set comprises pattern instances generated by distorting prototype patterns and the task of the trained network is to recall the correct prototype pattern given a new instance. In this paper we characterize these different aspects of associative memory performance and benchmark six different learning rules on storage capacity and prototype extraction. We consider only models with Hebbian plasticity that operate on sparse distributed representations with unit activities in the interval [0,1]. We evaluate both non-modular and modular network architectures and compare performance when trained and tested on different kinds of sparse random binary pattern sets, including correlated ones. We show that covariance learning has a robust but low storage capacity under these conditions and that the Bayesian Confidence Propagation learning rule (BCPNN) is superior with a good margin in all cases except one, reaching a three times higher composite score than the second best learning rule tested.
Spiking neural networks with Hebbian plasticity for unsupervised representation learning
May 10, 2023


We introduce a novel spiking neural network model for learning distributed internal representations from data in an unsupervised procedure. We achieved this by transforming the non-spiking feedforward Bayesian Confidence Propagation Neural Network (BCPNN) model, employing an online correlation-based Hebbian-Bayesian learning and rewiring mechanism, shown previously to perform representation learning, into a spiking neural network with Poisson statistics and low firing rate comparable to in vivo cortical pyramidal neurons. We evaluated the representations learned by our spiking model using a linear classifier and show performance close to the non-spiking BCPNN, and competitive with other Hebbian-based spiking networks when trained on MNIST and F-MNIST machine learning benchmarks.
Hebbian fast plasticity and working memory
Apr 13, 2023

Theories and models of working memory (WM) were at least since the mid-1990s dominated by the persistent activity hypothesis. The past decade has seen rising concerns about the shortcomings of sustained activity as the mechanism for short-term maintenance of WM information in the light of accumulating experimental evidence for so-called activity-silent WM and the fundamental difficulty in explaining robust multi-item WM. In consequence, alternative theories are now explored mostly in the direction of fast synaptic plasticity as the underlying mechanism.The question of non-Hebbian vs Hebbian synaptic plasticity emerges naturally in this context. In this review we focus on fast Hebbian plasticity and trace the origins of WM theories and models building on this form of associative learning.
Brain-like combination of feedforward and recurrent network components achieves prototype extraction and robust pattern recognition
Jun 30, 2022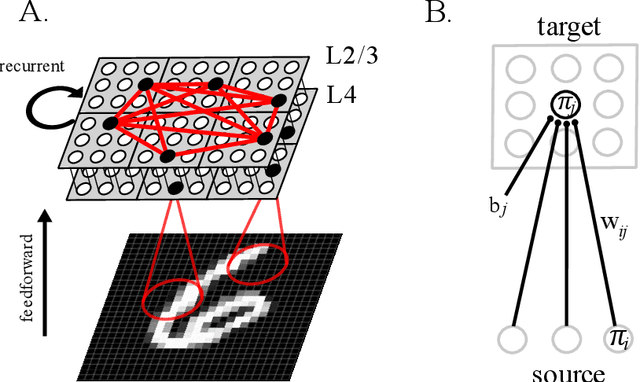
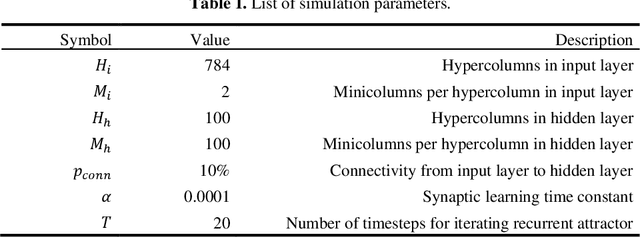
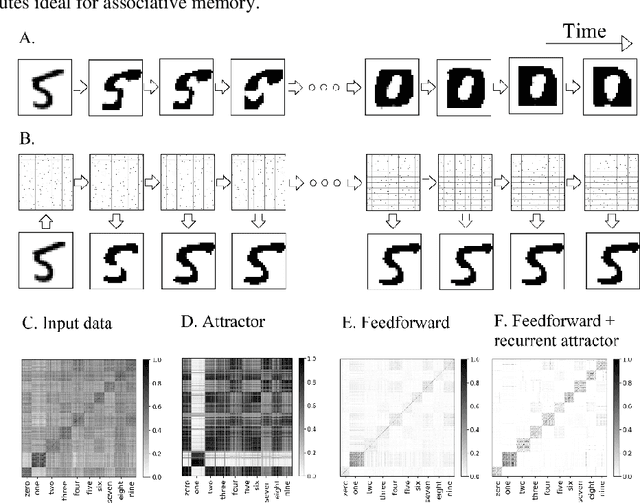

Associative memory has been a prominent candidate for the computation performed by the massively recurrent neocortical networks. Attractor networks implementing associative memory have offered mechanistic explanation for many cognitive phenomena. However, attractor memory models are typically trained using orthogonal or random patterns to avoid interference between memories, which makes them unfeasible for naturally occurring complex correlated stimuli like images. We approach this problem by combining a recurrent attractor network with a feedforward network that learns distributed representations using an unsupervised Hebbian-Bayesian learning rule. The resulting network model incorporates many known biological properties: unsupervised learning, Hebbian plasticity, sparse distributed activations, sparse connectivity, columnar and laminar cortical architecture, etc. We evaluate the synergistic effects of the feedforward and recurrent network components in complex pattern recognition tasks on the MNIST handwritten digits dataset. We demonstrate that the recurrent attractor component implements associative memory when trained on the feedforward-driven internal (hidden) representations. The associative memory is also shown to perform prototype extraction from the training data and make the representations robust to severely distorted input. We argue that several aspects of the proposed integration of feedforward and recurrent computations are particularly attractive from a machine learning perspective.
Semi-supervised learning with Bayesian Confidence Propagation Neural Network
Jun 29, 2021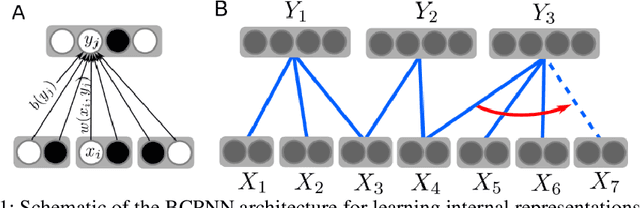

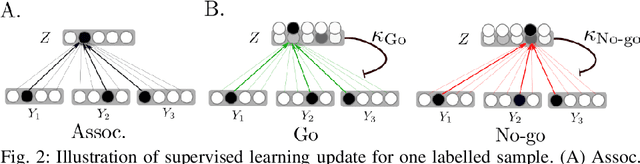
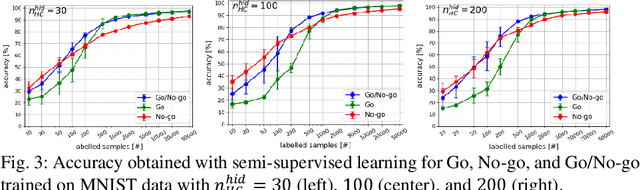
Learning internal representations from data using no or few labels is useful for machine learning research, as it allows using massive amounts of unlabeled data. In this work, we use the Bayesian Confidence Propagation Neural Network (BCPNN) model developed as a biologically plausible model of the cortex. Recent work has demonstrated that these networks can learn useful internal representations from data using local Bayesian-Hebbian learning rules. In this work, we show how such representations can be leveraged in a semi-supervised setting by introducing and comparing different classifiers. We also evaluate and compare such networks with other popular semi-supervised classifiers.
StreamBrain: An HPC Framework for Brain-like Neural Networks on CPUs, GPUs and FPGAs
Jun 09, 2021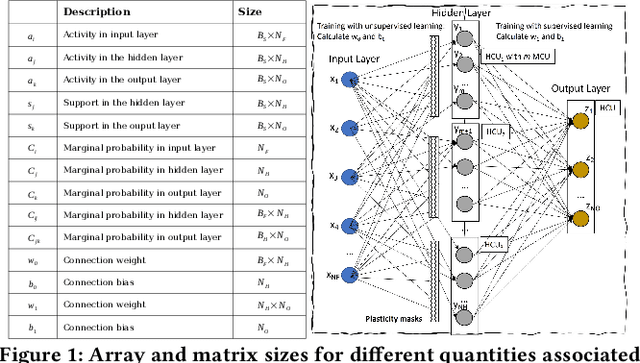
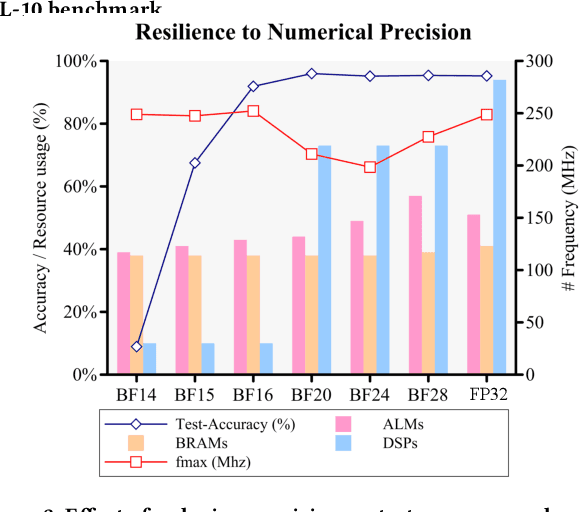
The modern deep learning method based on backpropagation has surged in popularity and has been used in multiple domains and application areas. At the same time, there are other -- less-known -- machine learning algorithms with a mature and solid theoretical foundation whose performance remains unexplored. One such example is the brain-like Bayesian Confidence Propagation Neural Network (BCPNN). In this paper, we introduce StreamBrain -- a framework that allows neural networks based on BCPNN to be practically deployed in High-Performance Computing systems. StreamBrain is a domain-specific language (DSL), similar in concept to existing machine learning (ML) frameworks, and supports backends for CPUs, GPUs, and even FPGAs. We empirically demonstrate that StreamBrain can train the well-known ML benchmark dataset MNIST within seconds, and we are the first to demonstrate BCPNN on STL-10 size networks. We also show how StreamBrain can be used to train with custom floating-point formats and illustrate the impact of using different bfloat variations on BCPNN using FPGAs.
Brain-like approaches to unsupervised learning of hidden representations -- a comparative study
May 06, 2020
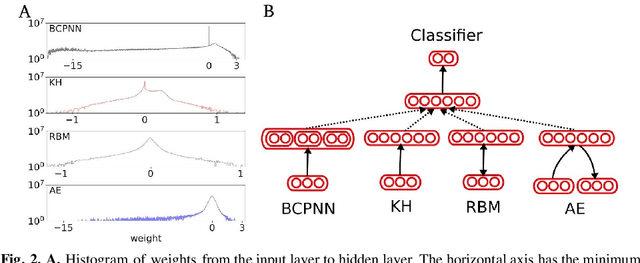
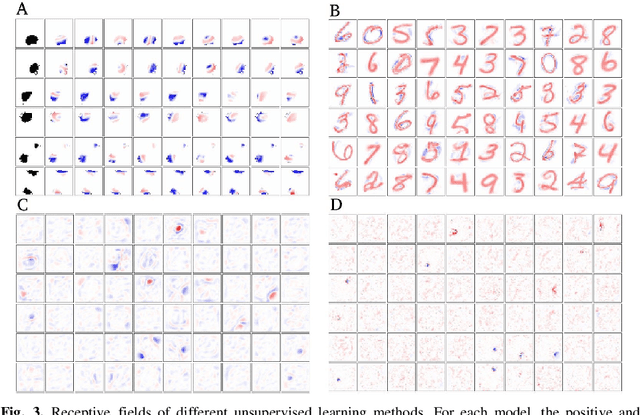
Unsupervised learning of hidden representations has been one of the most vibrant research directions in machine learning in recent years. In this work we study the brain-like Bayesian Confidence Propagating Neural Network (BCPNN) model, recently extended to extract sparse distributed high-dimensional representations. The saliency and separability of the hidden representations when trained on MNIST dataset is studied using an external classifier, and compared with other unsupervised learning methods that include restricted Boltzmann machines and autoencoders.