 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Heuristic Neuromorphic Solver for the Edge User Allocation Problem with Bayesian Confidence Propagation Neural Network
Feb 01, 2026We propose a neuromorphic solver for the NP-hard Edge User Allocation problem using an attractor network with Winner-Takes-All (WTA) mechanism implemented with the Bayesian Confidence Propagation Neural Network (BCPNN) framework. Unlike previous energy-based attractor networks, our solver uses dynamic heuristic biasing to guide allocations in real time and introduces a "no allocation" state to each WTA motif, achieving near-optimal performance with an empirically upper-bounded number of time steps. The approach is compatible with neuromorphic architectures and may offer improvements in energy efficiency.
A Reconfigurable Stream-Based FPGA Accelerator for Bayesian Confidence Propagation Neural Networks
Mar 03, 2025Brain-inspired algorithms are attractive and emerging alternatives to classical deep learning methods for use in various machine learning applications. Brain-inspired systems can feature local learning rules, both unsupervised/semi-supervised learning and different types of plasticity (structural/synaptic), allowing them to potentially be faster and more energy-efficient than traditional machine learning alternatives. Among the more salient brain-inspired algorithms are Bayesian Confidence Propagation Neural Networks (BCPNNs). BCPNN is an important tool for both machine learning and computational neuroscience research, and recent work shows that BCPNN can reach state-of-the-art performance in tasks such as learning and memory recall compared to other models. Unfortunately, BCPNN is primarily executed on slow general-purpose processors (CPUs) or power-hungry graphics processing units (GPUs), reducing the applicability of using BCPNN in (among others) Edge systems. In this work, we design a custom stream-based accelerator for BCPNN using Field-Programmable Gate Arrays (FPGA) using Xilinx Vitis High-Level Synthesis (HLS) flow. Furthermore, we model our accelerator's performance using first principles, and we empirically show that our proposed accelerator is between 1.3x - 5.3x faster than an Nvidia A100 GPU while at the same time consuming between 2.62x - 3.19x less power and 5.8x - 16.5x less energy without any degradation in performance.
Spiking representation learning for associative memories
Jun 05, 2024



Networks of interconnected neurons communicating through spiking signals offer the bedrock of neural computations. Our brains spiking neural networks have the computational capacity to achieve complex pattern recognition and cognitive functions effortlessly. However, solving real-world problems with artificial spiking neural networks (SNNs) has proved to be difficult for a variety of reasons. Crucially, scaling SNNs to large networks and processing large-scale real-world datasets have been challenging, especially when compared to their non-spiking deep learning counterparts. The critical operation that is needed of SNNs is the ability to learn distributed representations from data and use these representations for perceptual, cognitive and memory operations. In this work, we introduce a novel SNN that performs unsupervised representation learning and associative memory operations leveraging Hebbian synaptic and activity-dependent structural plasticity coupled with neuron-units modelled as Poisson spike generators with sparse firing (~1 Hz mean and ~100 Hz maximum firing rate). Crucially, the architecture of our model derives from the neocortical columnar organization and combines feedforward projections for learning hidden representations and recurrent projections for forming associative memories. We evaluated the model on properties relevant for attractor-based associative memories such as pattern completion, perceptual rivalry, distortion resistance, and prototype extraction.
Self-Supervised Learning of Time Series Representation via Diffusion Process and Imputation-Interpolation-Forecasting Mask
May 09, 2024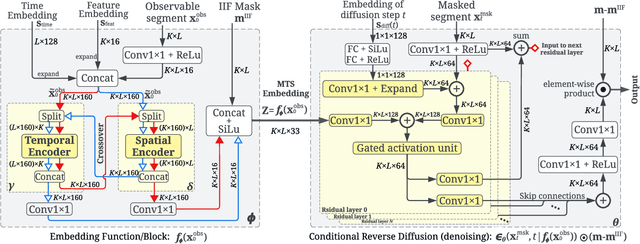
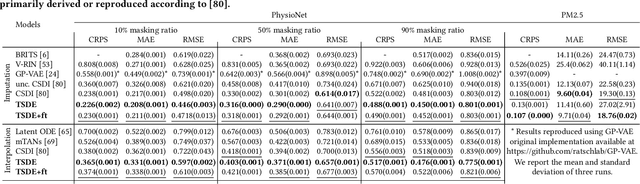

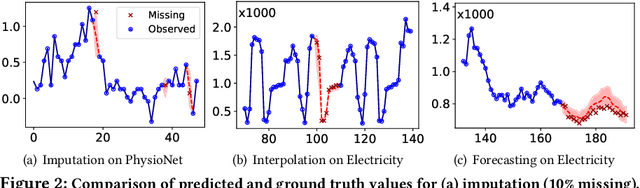
Time Series Representation Learning (TSRL) focuses on generating informative representations for various Time Series (TS) modeling tasks. Traditional Self-Supervised Learning (SSL) methods in TSRL fall into four main categories: reconstructive, adversarial, contrastive, and predictive, each with a common challenge of sensitivity to noise and intricate data nuances. Recently, diffusion-based methods have shown advanced generative capabilities. However, they primarily target specific application scenarios like imputation and forecasting, leaving a gap in leveraging diffusion models for generic TSRL. Our work, Time Series Diffusion Embedding (TSDE), bridges this gap as the first diffusion-based SSL TSRL approach. TSDE segments TS data into observed and masked parts using an Imputation-Interpolation-Forecasting (IIF) mask. It applies a trainable embedding function, featuring dual-orthogonal Transformer encoders with a crossover mechanism, to the observed part. We train a reverse diffusion process conditioned on the embeddings, designed to predict noise added to the masked part. Extensive experiments demonstrate TSDE's superiority in imputation, interpolation, forecasting, anomaly detection, classification, and clustering. We also conduct an ablation study, present embedding visualizations, and compare inference speed, further substantiating TSDE's efficiency and validity in learning representations of TS data.
Benchmarking Hebbian learning rules for associative memory
Dec 30, 2023


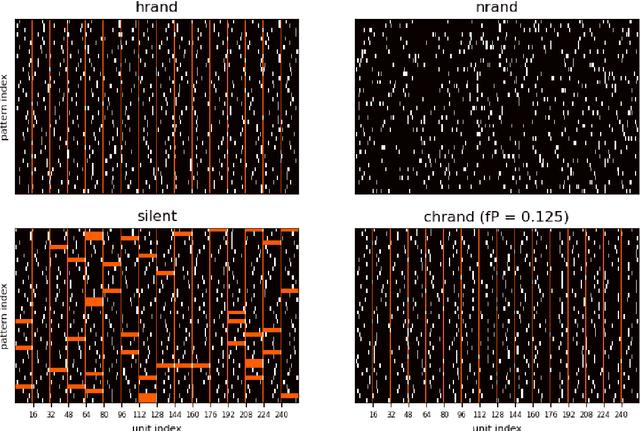
Associative memory or content addressable memory is an important component function in computer science and information processing and is a key concept in cognitive and computational brain science. Many different neural network architectures and learning rules have been proposed to model associative memory of the brain while investigating key functions like pattern completion and rivalry, noise reduction, and storage capacity. A less investigated but important function is prototype extraction where the training set comprises pattern instances generated by distorting prototype patterns and the task of the trained network is to recall the correct prototype pattern given a new instance. In this paper we characterize these different aspects of associative memory performance and benchmark six different learning rules on storage capacity and prototype extraction. We consider only models with Hebbian plasticity that operate on sparse distributed representations with unit activities in the interval [0,1]. We evaluate both non-modular and modular network architectures and compare performance when trained and tested on different kinds of sparse random binary pattern sets, including correlated ones. We show that covariance learning has a robust but low storage capacity under these conditions and that the Bayesian Confidence Propagation learning rule (BCPNN) is superior with a good margin in all cases except one, reaching a three times higher composite score than the second best learning rule tested.
Sourcing Investment Targets for Venture and Growth Capital Using Multivariate Time Series Transformer
Sep 28, 2023This paper addresses the growing application of data-driven approaches within the Private Equity (PE) industry, particularly in sourcing investment targets (i.e., companies) for Venture Capital (VC) and Growth Capital (GC). We present a comprehensive review of the relevant approaches and propose a novel approach leveraging a Transformer-based Multivariate Time Series Classifier (TMTSC) for predicting the success likelihood of any candidate company. The objective of our research is to optimize sourcing performance for VC and GC investments by formally defining the sourcing problem as a multivariate time series classification task. We consecutively introduce the key components of our implementation which collectively contribute to the successful application of TMTSC in VC/GC sourcing: input features, model architecture, optimization target, and investor-centric data augmentation and split. Our extensive experiments on four datasets, benchmarked towards three popular baselines, demonstrate the effectiveness of our approach in improving decision making within the VC and GC industry.
Spiking neural networks with Hebbian plasticity for unsupervised representation learning
May 10, 2023


We introduce a novel spiking neural network model for learning distributed internal representations from data in an unsupervised procedure. We achieved this by transforming the non-spiking feedforward Bayesian Confidence Propagation Neural Network (BCPNN) model, employing an online correlation-based Hebbian-Bayesian learning and rewiring mechanism, shown previously to perform representation learning, into a spiking neural network with Poisson statistics and low firing rate comparable to in vivo cortical pyramidal neurons. We evaluated the representations learned by our spiking model using a linear classifier and show performance close to the non-spiking BCPNN, and competitive with other Hebbian-based spiking networks when trained on MNIST and F-MNIST machine learning benchmarks.
Hebbian fast plasticity and working memory
Apr 13, 2023

Theories and models of working memory (WM) were at least since the mid-1990s dominated by the persistent activity hypothesis. The past decade has seen rising concerns about the shortcomings of sustained activity as the mechanism for short-term maintenance of WM information in the light of accumulating experimental evidence for so-called activity-silent WM and the fundamental difficulty in explaining robust multi-item WM. In consequence, alternative theories are now explored mostly in the direction of fast synaptic plasticity as the underlying mechanism.The question of non-Hebbian vs Hebbian synaptic plasticity emerges naturally in this context. In this review we focus on fast Hebbian plasticity and trace the origins of WM theories and models building on this form of associative learning.
Finding metastable skyrmionic structures via a metaheuristic perturbation-driven neural network
Mar 06, 2023



Topological magnetic textures observed in experiments can, in principle, be predicted by theoretical calculations and numerical simulations. However, such calculations are, in general, hampered by difficulties in distinguishing between local and global energy minima. This becomes particularly problematic for magnetic materials that allow for a multitude of topological charges. Finding solutions to such problems by means of classical numerical methods can be challenging because either a good initial guess or a gigantic amount of random sampling is required. In this study, we demonstrate an efficient way to identify those metastable configurations by leveraging the power of gradient descent-based optimization within the framework of a feedforward neural network combined with a heuristic meta-search, which is driven by a random perturbation of the neural network's input. We exemplify the power of the method by an analysis of the Pd/Fe/Ir(111) system, an experimentally well characterized system.
Genetic-tunneling driven energy optimizer for magnetic system
Dec 31, 2022Novel topological spin textures, such as magnetic skyrmions, benefit from their inherent stability, acting as the ground state in several magnetic systems. In the current study of atomic monolayer magnetic materials, reasonable initial guesses are still needed to search for those magnetic patterns. This situation underlines the need to develop a more effective way to identify the ground states. To solve this problem, in this work, we propose a genetic-tunneling-driven variance-controlled optimization approach, which combines a local energy minimizer back-end and a metaheuristic global searching front-end. This algorithm is an effective optimization solution for searching for magnetic ground states at extremely low temperatures and is also robust for finding low-energy degenerated states at finite temperatures. We demonstrate here the success of this method in searching for magnetic ground states of 2D monolayer systems with both artificial and calculated interactions from density functional theory. It is also worth noting that the inherent concurrent property of this algorithm can significantly decrease the execution time. In conclusion, our proposed method builds a useful tool for low-dimensional magnetic system energy optimization.