 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrequency Matters: When Time Series Foundation Models Fail Under Spectral Shift
Nov 06, 2025Time series foundation models (TSFMs) have shown strong results on public benchmarks, prompting comparisons to a "BERT moment" for time series. Their effectiveness in industrial settings, however, remains uncertain. We examine why TSFMs often struggle to generalize and highlight spectral shift (a mismatch between the dominant frequency components in downstream tasks and those represented during pretraining) as a key factor. We present evidence from an industrial-scale player engagement prediction task in mobile gaming, where TSFMs underperform domain-adapted baselines. To isolate the mechanism, we design controlled synthetic experiments contrasting signals with seen versus unseen frequency bands, observing systematic degradation under spectral mismatch. These findings position frequency awareness as critical for robust TSFM deployment and motivate new pretraining and evaluation protocols that explicitly account for spectral diversity.
Causality for Tabular Data Synthesis: A High-Order Structure Causal Benchmark Framework
Jun 12, 2024Tabular synthesis models remain ineffective at capturing complex dependencies, and the quality of synthetic data is still insufficient for comprehensive downstream tasks, such as prediction under distribution shifts, automated decision-making, and cross-table understanding. A major challenge is the lack of prior knowledge about underlying structures and high-order relationships in tabular data. We argue that a systematic evaluation on high-order structural information for tabular data synthesis is the first step towards solving the problem. In this paper, we introduce high-order structural causal information as natural prior knowledge and provide a benchmark framework for the evaluation of tabular synthesis models. The framework allows us to generate benchmark datasets with a flexible range of data generation processes and to train tabular synthesis models using these datasets for further evaluation. We propose multiple benchmark tasks, high-order metrics, and causal inference tasks as downstream tasks for evaluating the quality of synthetic data generated by the trained models. Our experiments demonstrate to leverage the benchmark framework for evaluating the model capability of capturing high-order structural causal information. Furthermore, our benchmarking results provide an initial assessment of state-of-the-art tabular synthesis models. They have clearly revealed significant gaps between ideal and actual performance and how baseline methods differ. Our benchmark framework is available at URL https://github.com/TURuibo/CauTabBench.
Self-Supervised Learning of Time Series Representation via Diffusion Process and Imputation-Interpolation-Forecasting Mask
May 09, 2024
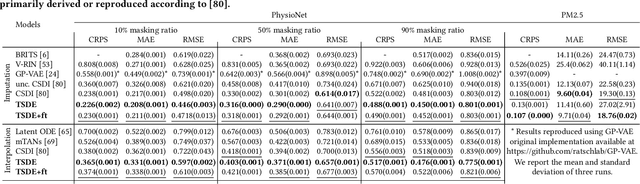

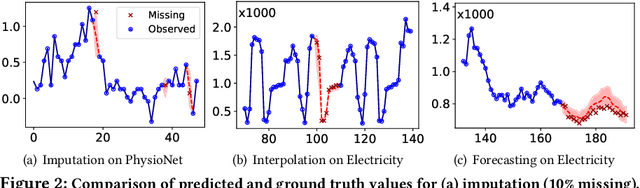
Time Series Representation Learning (TSRL) focuses on generating informative representations for various Time Series (TS) modeling tasks. Traditional Self-Supervised Learning (SSL) methods in TSRL fall into four main categories: reconstructive, adversarial, contrastive, and predictive, each with a common challenge of sensitivity to noise and intricate data nuances. Recently, diffusion-based methods have shown advanced generative capabilities. However, they primarily target specific application scenarios like imputation and forecasting, leaving a gap in leveraging diffusion models for generic TSRL. Our work, Time Series Diffusion Embedding (TSDE), bridges this gap as the first diffusion-based SSL TSRL approach. TSDE segments TS data into observed and masked parts using an Imputation-Interpolation-Forecasting (IIF) mask. It applies a trainable embedding function, featuring dual-orthogonal Transformer encoders with a crossover mechanism, to the observed part. We train a reverse diffusion process conditioned on the embeddings, designed to predict noise added to the masked part. Extensive experiments demonstrate TSDE's superiority in imputation, interpolation, forecasting, anomaly detection, classification, and clustering. We also conduct an ablation study, present embedding visualizations, and compare inference speed, further substantiating TSDE's efficiency and validity in learning representations of TS data.
GenCeption: Evaluate Multimodal LLMs with Unlabeled Unimodal Data
Feb 22, 2024Multimodal Large Language Models (MLLMs) are commonly evaluated using costly annotated multimodal benchmarks. However, these benchmarks often struggle to keep pace with the rapidly advancing requirements of MLLM evaluation. We propose GenCeption, a novel and annotation-free MLLM evaluation framework that merely requires unimodal data to assess inter-modality semantic coherence and inversely reflects the models' inclination to hallucinate. Analogous to the popular DrawCeption game, GenCeption initiates with a non-textual sample and undergoes a series of iterative description and generation steps. Semantic drift across iterations is quantified using the GC@T metric. Our empirical findings validate GenCeption's efficacy, showing strong correlations with popular MLLM benchmarking results. GenCeption may be extended to mitigate training data contamination by utilizing ubiquitous, previously unseen unimodal data.