 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Learning of Time Series Representation via Diffusion Process and Imputation-Interpolation-Forecasting Mask
May 09, 2024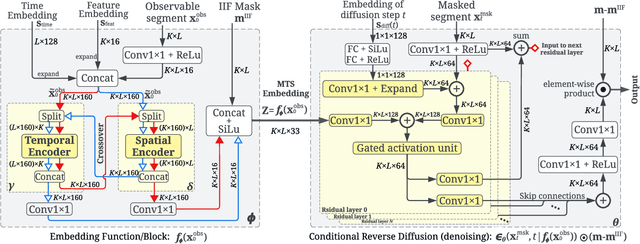
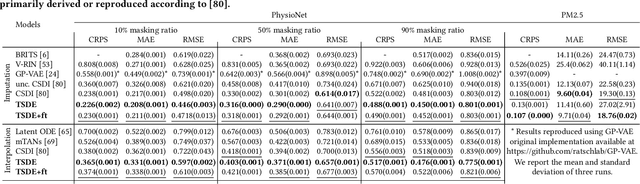

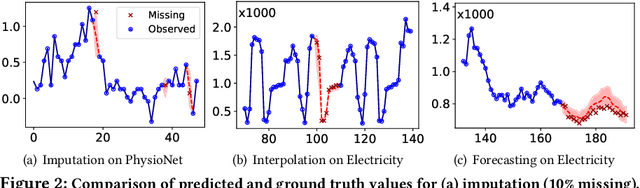
Time Series Representation Learning (TSRL) focuses on generating informative representations for various Time Series (TS) modeling tasks. Traditional Self-Supervised Learning (SSL) methods in TSRL fall into four main categories: reconstructive, adversarial, contrastive, and predictive, each with a common challenge of sensitivity to noise and intricate data nuances. Recently, diffusion-based methods have shown advanced generative capabilities. However, they primarily target specific application scenarios like imputation and forecasting, leaving a gap in leveraging diffusion models for generic TSRL. Our work, Time Series Diffusion Embedding (TSDE), bridges this gap as the first diffusion-based SSL TSRL approach. TSDE segments TS data into observed and masked parts using an Imputation-Interpolation-Forecasting (IIF) mask. It applies a trainable embedding function, featuring dual-orthogonal Transformer encoders with a crossover mechanism, to the observed part. We train a reverse diffusion process conditioned on the embeddings, designed to predict noise added to the masked part. Extensive experiments demonstrate TSDE's superiority in imputation, interpolation, forecasting, anomaly detection, classification, and clustering. We also conduct an ablation study, present embedding visualizations, and compare inference speed, further substantiating TSDE's efficiency and validity in learning representations of TS data.
Sourcing Investment Targets for Venture and Growth Capital Using Multivariate Time Series Transformer
Sep 28, 2023This paper addresses the growing application of data-driven approaches within the Private Equity (PE) industry, particularly in sourcing investment targets (i.e., companies) for Venture Capital (VC) and Growth Capital (GC). We present a comprehensive review of the relevant approaches and propose a novel approach leveraging a Transformer-based Multivariate Time Series Classifier (TMTSC) for predicting the success likelihood of any candidate company. The objective of our research is to optimize sourcing performance for VC and GC investments by formally defining the sourcing problem as a multivariate time series classification task. We consecutively introduce the key components of our implementation which collectively contribute to the successful application of TMTSC in VC/GC sourcing: input features, model architecture, optimization target, and investor-centric data augmentation and split. Our extensive experiments on four datasets, benchmarked towards three popular baselines, demonstrate the effectiveness of our approach in improving decision making within the VC and GC industry.
CompanyKG: A Large-Scale Heterogeneous Graph for Company Similarity Quantification
Jun 18, 2023



In the investment industry, it is often essential to carry out fine-grained company similarity quantification for a range of purposes, including market mapping, competitor analysis, and mergers and acquisitions. We propose and publish a knowledge graph, named CompanyKG, to represent and learn diverse company features and relations. Specifically, 1.17 million companies are represented as nodes enriched with company description embeddings; and 15 different inter-company relations result in 51.06 million weighted edges. To enable a comprehensive assessment of methods for company similarity quantification, we have devised and compiled three evaluation tasks with annotated test sets: similarity prediction, competitor retrieval and similarity ranking. We present extensive benchmarking results for 11 reproducible predictive methods categorized into three groups: node-only, edge-only, and node+edge. To the best of our knowledge, CompanyKG is the first large-scale heterogeneous graph dataset originating from a real-world investment platform, tailored for quantifying inter-company similarity.
A Scalable and Adaptive System to Infer the Industry Sectors of Companies: Prompt + Model Tuning of Generative Language Models
Jun 05, 2023
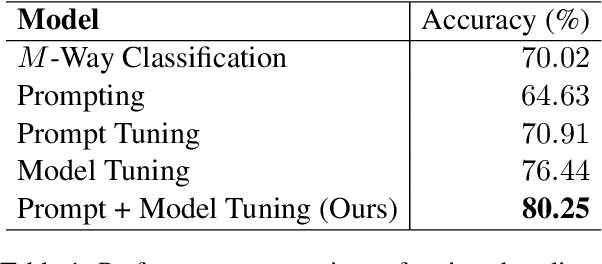


The Private Equity (PE) firms operate investment funds by acquiring and managing companies to achieve a high return upon selling. Many PE funds are thematic, meaning investment professionals aim to identify trends by covering as many industry sectors as possible, and picking promising companies within these sectors. So, inferring sectors for companies is critical to the success of thematic PE funds. In this work, we standardize the sector framework and discuss the typical challenges; we then introduce our sector inference system addressing these challenges. Specifically, our system is built on a medium-sized generative language model, finetuned with a prompt + model tuning procedure. The deployed model demonstrates a superior performance than the common baselines. The system has been serving many PE professionals for over a year, showing great scalability to data volume and adaptability to any change in sector framework and/or annotation.
Simulation-Informed Revenue Extrapolation with Confidence Estimate for Scaleup Companies Using Scarce Time-Series Data
Aug 23, 2022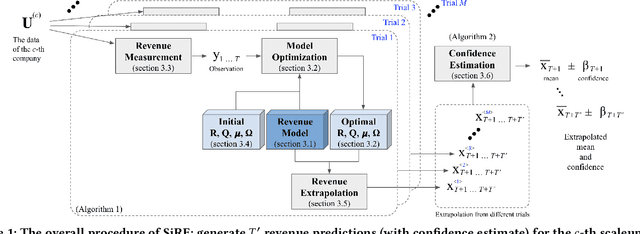
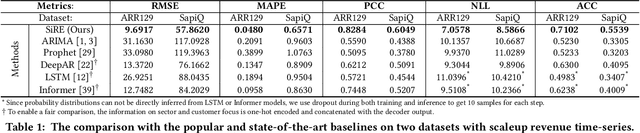
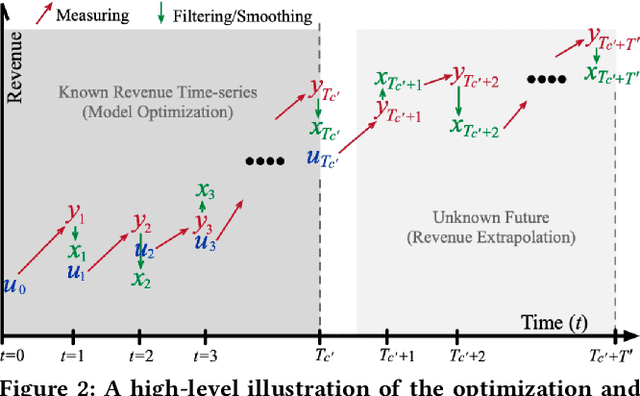
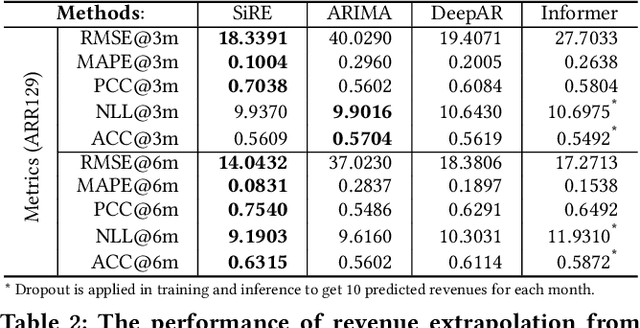
Investment professionals rely on extrapolating company revenue into the future (i.e. revenue forecast) to approximate the valuation of scaleups (private companies in a high-growth stage) and inform their investment decision. This task is manual and empirical, leaving the forecast quality heavily dependent on the investment professionals' experiences and insights. Furthermore, financial data on scaleups is typically proprietary, costly and scarce, ruling out the wide adoption of data-driven approaches. To this end, we propose a simulation-informed revenue extrapolation (SiRE) algorithm that generates fine-grained long-term revenue predictions on small datasets and short time-series. SiRE models the revenue dynamics as a linear dynamical system (LDS), which is solved using the EM algorithm. The main innovation lies in how the noisy revenue measurements are obtained during training and inferencing. SiRE works for scaleups that operate in various sectors and provides confidence estimates. The quantitative experiments on two practical tasks show that SiRE significantly surpasses the baseline methods by a large margin. We also observe high performance when SiRE extrapolates long-term predictions from short time-series. The performance-efficiency balance and result explainability of SiRE are also validated empirically. Evaluated from the perspective of investment professionals, SiRE can precisely locate the scaleups that have a great potential return in 2 to 5 years. Furthermore, our qualitative inspection illustrates some advantageous attributes of the SiRE revenue forecasts.
PAUSE: Positive and Annealed Unlabeled Sentence Embedding
Sep 07, 2021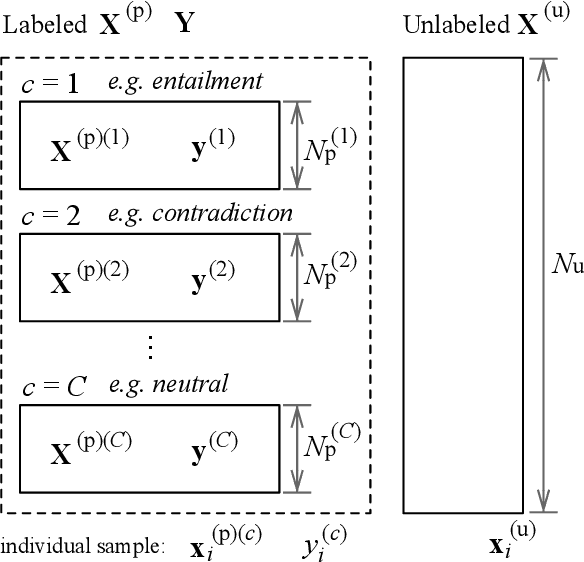
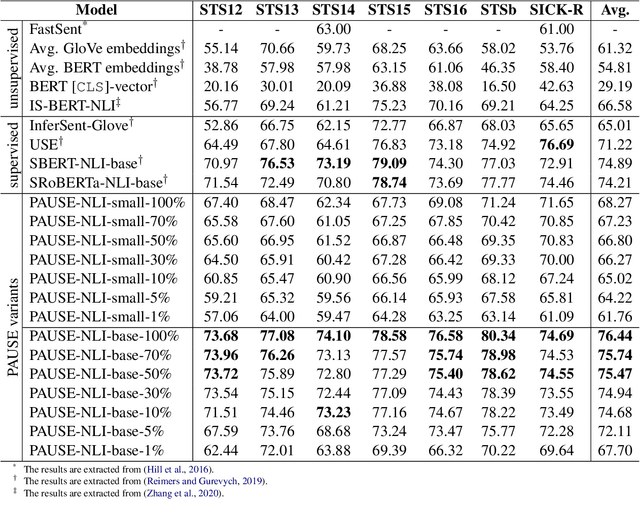
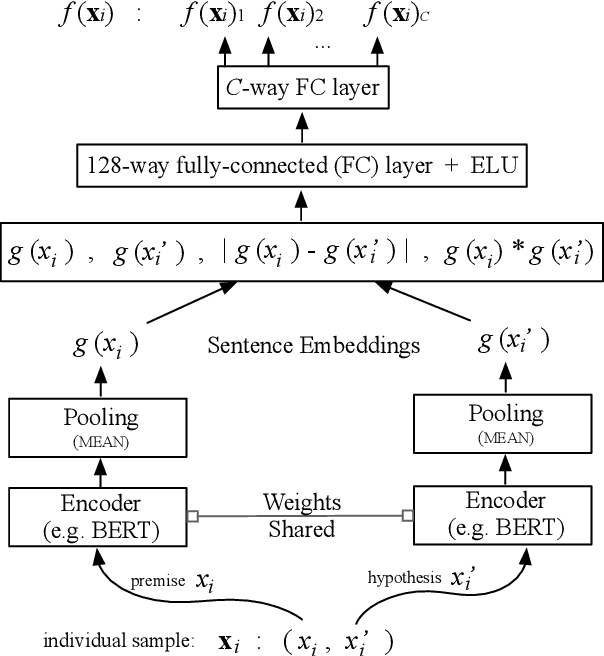
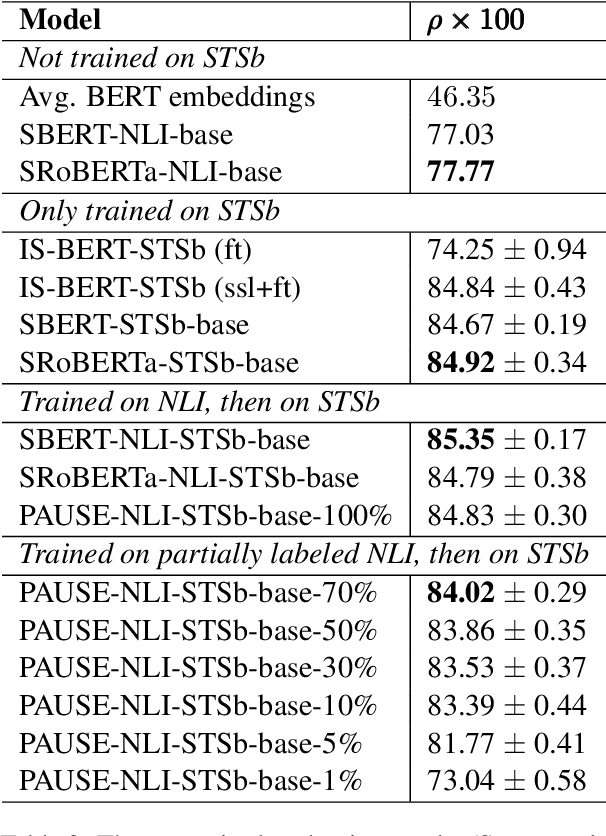
Sentence embedding refers to a set of effective and versatile techniques for converting raw text into numerical vector representations that can be used in a wide range of natural language processing (NLP) applications. The majority of these techniques are either supervised or unsupervised. Compared to the unsupervised methods, the supervised ones make less assumptions about optimization objectives and usually achieve better results. However, the training requires a large amount of labeled sentence pairs, which is not available in many industrial scenarios. To that end, we propose a generic and end-to-end approach -- PAUSE (Positive and Annealed Unlabeled Sentence Embedding), capable of learning high-quality sentence embeddings from a partially labeled dataset. We experimentally show that PAUSE achieves, and sometimes surpasses, state-of-the-art results using only a small fraction of labeled sentence pairs on various benchmark tasks. When applied to a real industrial use case where labeled samples are scarce, PAUSE encourages us to extend our dataset without the liability of extensive manual annotation work.