 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing Beyond Words: Self-Supervised Visual Learning for Multimodal Large Language Models
Dec 17, 2025Multimodal Large Language Models (MLLMs) have recently demonstrated impressive capabilities in connecting vision and language, yet their proficiency in fundamental visual reasoning tasks remains limited. This limitation can be attributed to the fact that MLLMs learn visual understanding primarily from textual descriptions, which constitute a subjective and inherently incomplete supervisory signal. Furthermore, the modest scale of multimodal instruction tuning compared to massive text-only pre-training leads MLLMs to overfit language priors while overlooking visual details. To address these issues, we introduce JARVIS, a JEPA-inspired framework for self-supervised visual enhancement in MLLMs. Specifically, we integrate the I-JEPA learning paradigm into the standard vision-language alignment pipeline of MLLMs training. Our approach leverages frozen vision foundation models as context and target encoders, while training the predictor, implemented as the early layers of an LLM, to learn structural and semantic regularities from images without relying exclusively on language supervision. Extensive experiments on standard MLLM benchmarks show that JARVIS consistently improves performance on vision-centric benchmarks across different LLM families, without degrading multimodal reasoning abilities. Our source code is publicly available at: https://github.com/aimagelab/JARVIS.
CompanyKG: A Large-Scale Heterogeneous Graph for Company Similarity Quantification
Jun 18, 2023



In the investment industry, it is often essential to carry out fine-grained company similarity quantification for a range of purposes, including market mapping, competitor analysis, and mergers and acquisitions. We propose and publish a knowledge graph, named CompanyKG, to represent and learn diverse company features and relations. Specifically, 1.17 million companies are represented as nodes enriched with company description embeddings; and 15 different inter-company relations result in 51.06 million weighted edges. To enable a comprehensive assessment of methods for company similarity quantification, we have devised and compiled three evaluation tasks with annotated test sets: similarity prediction, competitor retrieval and similarity ranking. We present extensive benchmarking results for 11 reproducible predictive methods categorized into three groups: node-only, edge-only, and node+edge. To the best of our knowledge, CompanyKG is the first large-scale heterogeneous graph dataset originating from a real-world investment platform, tailored for quantifying inter-company similarity.
Silo NLP's Participation at WAT2022
Aug 02, 2022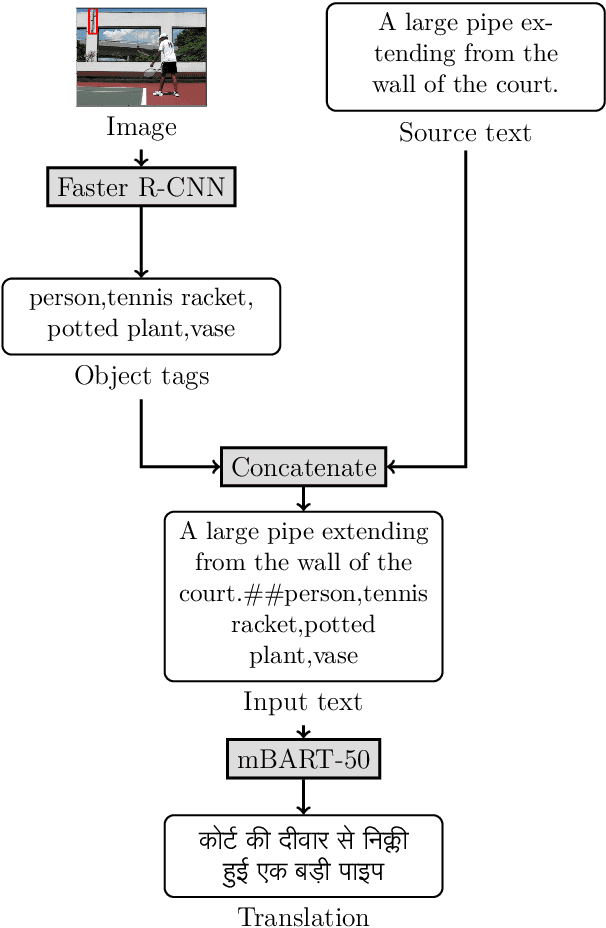

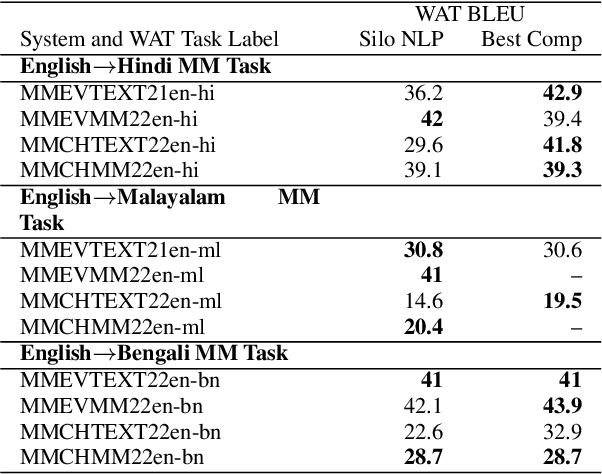

This paper provides the system description of "Silo NLP's" submission to the Workshop on Asian Translation (WAT2022). We have participated in the Indic Multimodal tasks (English->Hindi, English->Malayalam, and English->Bengali Multimodal Translation). For text-only translation, we trained Transformers from scratch and fine-tuned mBART-50 models. For multimodal translation, we used the same mBART architecture and extracted object tags from the images to use as visual features concatenated with the text sequence. Our submission tops many tasks including English->Hindi multimodal translation (evaluation test), English->Malayalam text-only and multimodal translation (evaluation test), English->Bengali multimodal translation (challenge test), and English->Bengali text-only translation (evaluation test).
CoSimLex: A Resource for Evaluating Graded Word Similarity in Context
Dec 18, 2019
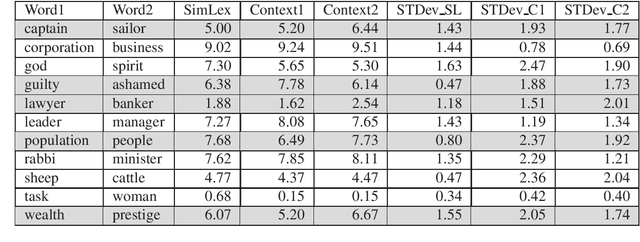

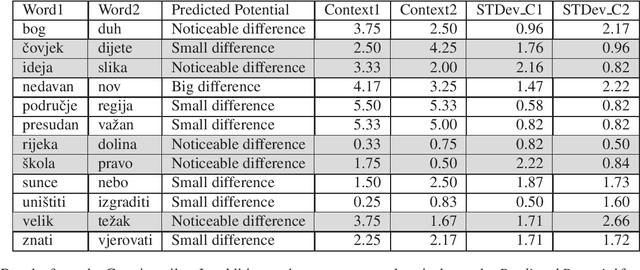
State of the art natural language processing tools are built on context-dependent word embeddings, but no direct method for evaluating these representations currently exists. Standard tasks and datasets for intrinsic evaluation of embeddings are based on judgements of similarity, but ignore context; standard tasks for word sense disambiguation take account of context but do not provide continuous measures of meaning similarity. This paper describes an effort to build a new dataset, CoSimLex, intended to fill this gap. Building on the standard pairwise similarity task of SimLex-999, it provides context-dependent similarity measures; covers not only discrete differences in word sense but more subtle, graded changes in meaning; and covers not only a well-resourced language (English) but a number of less-resourced languages. We define the task and evaluation metrics, outline the dataset collection methodology, and describe the status of the dataset so far.