 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Economics of Builder Saturation in Digital Markets
Mar 24, 2026Recent advances in generative AI systems have dramatically reduced the cost of digital production, fueling narratives that widespread participation in software creation will yield a proliferation of viable companies. This paper challenges that assumption. We introduce the Builder Saturation Effect, formalizing a model in which production scales elastically but human attention remains finite. In markets with near-zero marginal costs and free entry, increases in the number of producers dilute average attention and returns per producer, even as total output expands. Extending the framework to incorporate quality heterogeneity and reinforcement dynamics, we show that equilibrium outcomes exhibit declining average payoffs and increasing concentration, consistent with power-law-like distributions. These results suggest that AI-enabled, democratised production is more likely to intensify competition and produce winner-take-most outcomes than to generate broadly distributed entrepreneurial success. Contribution type: This paper is primarily a work of synthesis and applied formalisation. The individual theoretical ingredients - attention scarcity, free-entry dilution, superstar effects, preferential attachment - are well established in their respective literatures. The contribution is to combine them into a unified framework and direct the resulting predictions at a specific contemporary claim about AI-enabled entrepreneurship.
CompanyKG: A Large-Scale Heterogeneous Graph for Company Similarity Quantification
Jun 18, 2023



In the investment industry, it is often essential to carry out fine-grained company similarity quantification for a range of purposes, including market mapping, competitor analysis, and mergers and acquisitions. We propose and publish a knowledge graph, named CompanyKG, to represent and learn diverse company features and relations. Specifically, 1.17 million companies are represented as nodes enriched with company description embeddings; and 15 different inter-company relations result in 51.06 million weighted edges. To enable a comprehensive assessment of methods for company similarity quantification, we have devised and compiled three evaluation tasks with annotated test sets: similarity prediction, competitor retrieval and similarity ranking. We present extensive benchmarking results for 11 reproducible predictive methods categorized into three groups: node-only, edge-only, and node+edge. To the best of our knowledge, CompanyKG is the first large-scale heterogeneous graph dataset originating from a real-world investment platform, tailored for quantifying inter-company similarity.
A Scalable and Adaptive System to Infer the Industry Sectors of Companies: Prompt + Model Tuning of Generative Language Models
Jun 05, 2023
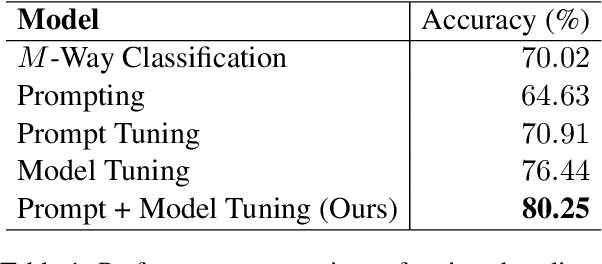


The Private Equity (PE) firms operate investment funds by acquiring and managing companies to achieve a high return upon selling. Many PE funds are thematic, meaning investment professionals aim to identify trends by covering as many industry sectors as possible, and picking promising companies within these sectors. So, inferring sectors for companies is critical to the success of thematic PE funds. In this work, we standardize the sector framework and discuss the typical challenges; we then introduce our sector inference system addressing these challenges. Specifically, our system is built on a medium-sized generative language model, finetuned with a prompt + model tuning procedure. The deployed model demonstrates a superior performance than the common baselines. The system has been serving many PE professionals for over a year, showing great scalability to data volume and adaptability to any change in sector framework and/or annotation.
Linnaeus: A highly reusable and adaptable ML based log classification pipeline
Mar 11, 2021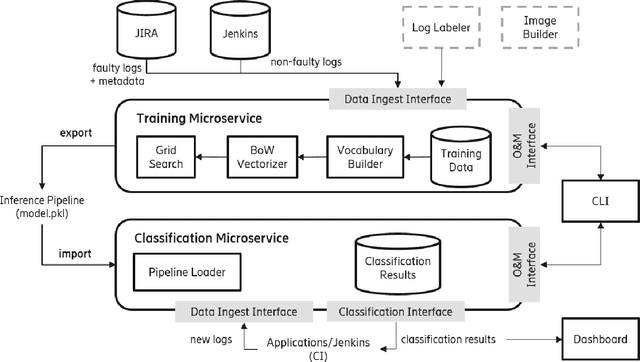
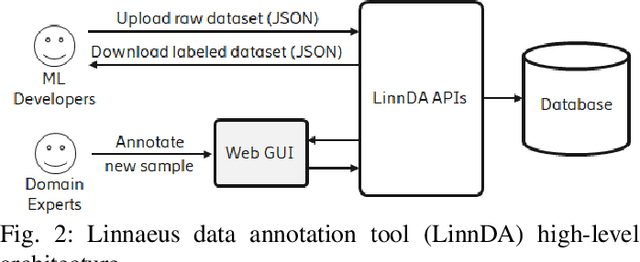
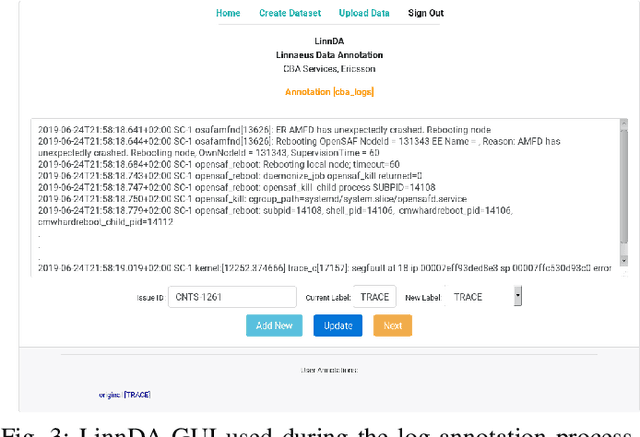
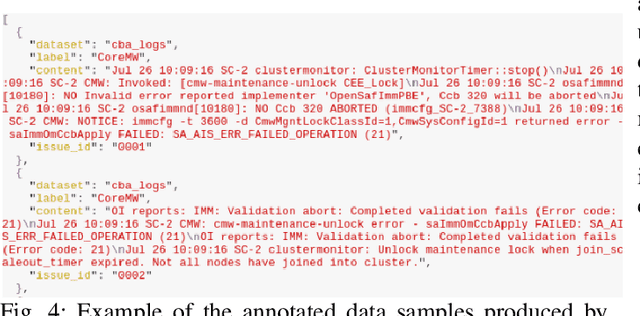
Logs are a common way to record detailed run-time information in software. As modern software systems evolve in scale and complexity, logs have become indispensable to understanding the internal states of the system. At the same time however, manually inspecting logs has become impractical. In recent times, there has been more emphasis on statistical and machine learning (ML) based methods for analyzing logs. While the results have shown promise, most of the literature focuses on algorithms and state-of-the-art (SOTA), while largely ignoring the practical aspects. In this paper we demonstrate our end-to-end log classification pipeline, Linnaeus. Besides showing the more traditional ML flow, we also demonstrate our solutions for adaptability and re-use, integration towards large scale software development processes, and how we cope with lack of labelled data. We hope Linnaeus can serve as a blueprint for, and inspire the integration of, various ML based solutions in other large scale industrial settings.
Traffic Flow Estimation using LTE Radio Frequency Counters and Machine Learning
Jan 22, 2021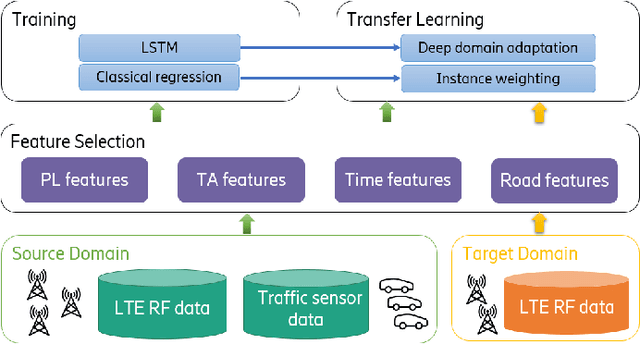



As the demand for vehicles continues to outpace construction of new roads, it becomes imperative we implement strategies that improve utilization of existing transport infrastructure. Traffic sensors form a crucial part of many such strategies, giving us valuable insights into road utilization. However, due to cost and lead time associated with installation and maintenance of traffic sensors, municipalities and traffic authorities look toward cheaper and more scalable alternatives. Due to their ubiquitous nature and wide global deployment, cellular networks offer one such alternative. In this paper we present a novel method for traffic flow estimation using standardized LTE/4G radio frequency performance measurement counters. The problem is cast as a supervised regression task using both classical and deep learning methods. We further apply transfer learning to compensate that many locations lack traffic sensor data that could be used for training. We show that our approach benefits from applying transfer learning to generalize the solution not only in time but also in space (i.e., various parts of the city). The results are very promising and, unlike competing solutions, our approach utilizes aggregate LTE radio frequency counter data that is inherently privacy-preserving, readily available, and scales globally without any additional network impact.