 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAMMOTH: Massively Multilingual Modular Open Translation @ Helsinki
Mar 12, 2024



NLP in the age of monolithic large language models is approaching its limits in terms of size and information that can be handled. The trend goes to modularization, a necessary step into the direction of designing smaller sub-networks and components with specialized functionality. In this paper, we present the MAMMOTH toolkit: a framework designed for training massively multilingual modular machine translation systems at scale, initially derived from OpenNMT-py and then adapted to ensure efficient training across computation clusters. We showcase its efficiency across clusters of A100 and V100 NVIDIA GPUs, and discuss our design philosophy and plans for future information. The toolkit is publicly available online.
Isotropy, Clusters, and Classifiers
Feb 05, 2024Whether embedding spaces use all their dimensions equally, i.e., whether they are isotropic, has been a recent subject of discussion. Evidence has been accrued both for and against enforcing isotropy in embedding spaces. In the present paper, we stress that isotropy imposes requirements on the embedding space that are not compatible with the presence of clusters -- which also negatively impacts linear classification objectives. We demonstrate this fact empirically and use it to shed light on previous results from the literature.
Democratizing Machine Translation with OPUS-MT
Dec 04, 2022This paper presents the OPUS ecosystem with a focus on the development of open machine translation models and tools, and their integration into end-user applications, development platforms and professional workflows. We discuss our on-going mission of increasing language coverage and translation quality, and also describe on-going work on the development of modular translation models and speed-optimized compact solutions for real-time translation on regular desktops and small devices.
Silo NLP's Participation at WAT2022
Aug 02, 2022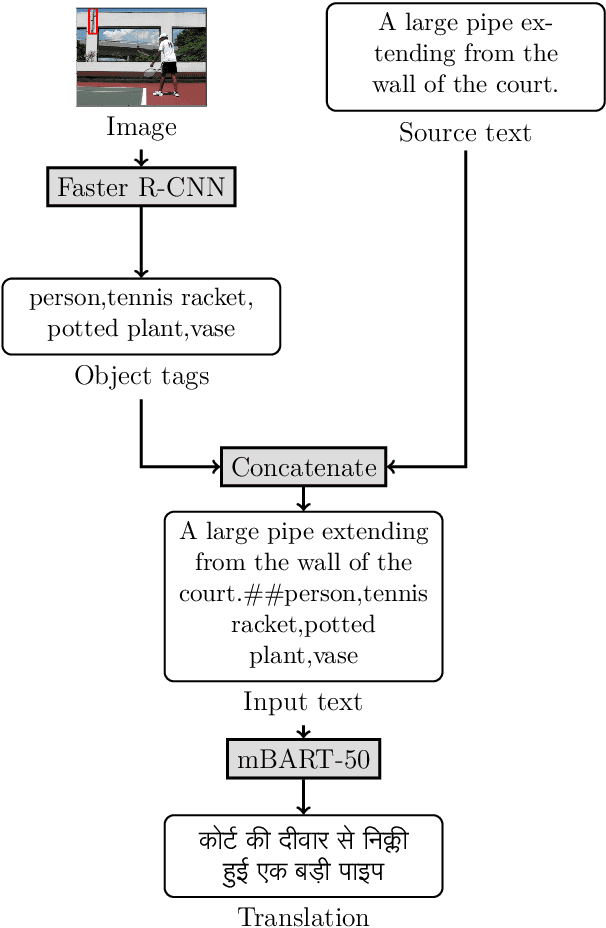

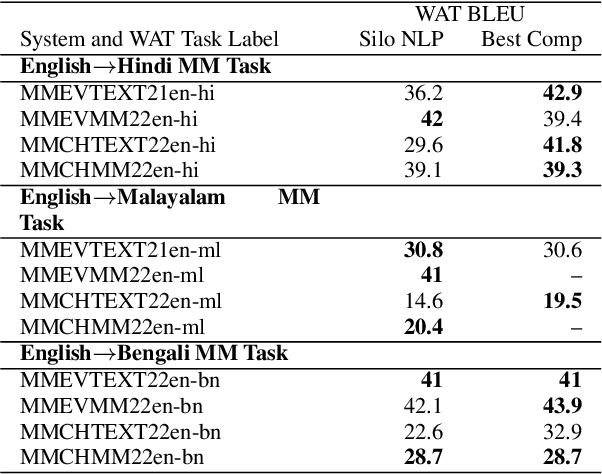

This paper provides the system description of "Silo NLP's" submission to the Workshop on Asian Translation (WAT2022). We have participated in the Indic Multimodal tasks (English->Hindi, English->Malayalam, and English->Bengali Multimodal Translation). For text-only translation, we trained Transformers from scratch and fine-tuned mBART-50 models. For multimodal translation, we used the same mBART architecture and extracted object tags from the images to use as visual features concatenated with the text sequence. Our submission tops many tasks including English->Hindi multimodal translation (evaluation test), English->Malayalam text-only and multimodal translation (evaluation test), English->Bengali multimodal translation (challenge test), and English->Bengali text-only translation (evaluation test).
Transfer learning and subword sampling for asymmetric-resource one-to-many neural translation
Apr 08, 2020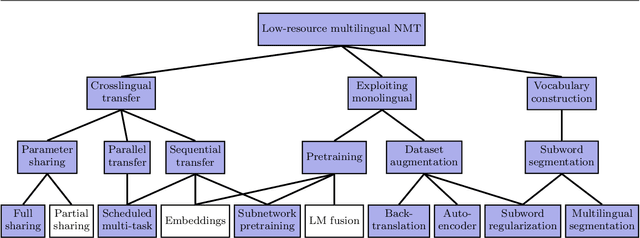

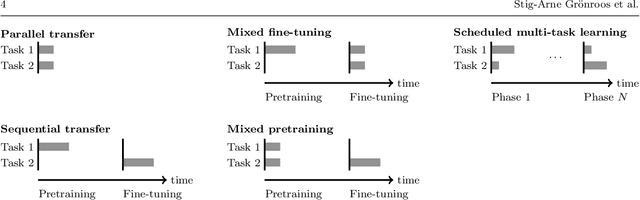
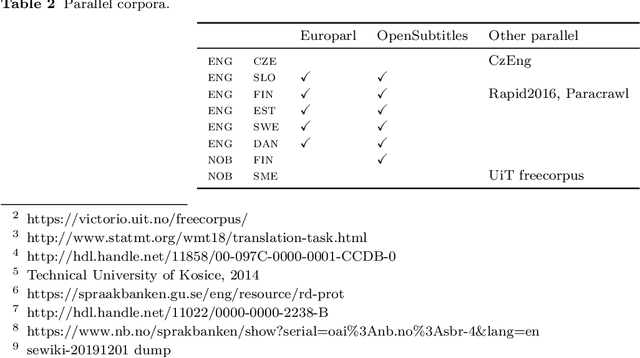
There are several approaches for improving neural machine translation for low-resource languages: Monolingual data can be exploited via pretraining or data augmentation; Parallel corpora on related language pairs can be used via parameter sharing or transfer learning in multilingual models; Subword segmentation and regularization techniques can be applied to ensure high coverage of the vocabulary. We review these approaches in the context of an asymmetric-resource one-to-many translation task, in which the pair of target languages are related, with one being a very low-resource and the other a higher-resource language. We test various methods on three artificially restricted translation tasks---English to Estonian (low-resource) and Finnish (high-resource), English to Slovak and Czech, English to Danish and Swedish---and one real-world task, Norwegian to North S\'ami and Finnish. The experiments show positive effects especially for scheduled multi-task learning, denoising autoencoder, and subword sampling.
Finnish Language Modeling with Deep Transformer Models
Mar 27, 2020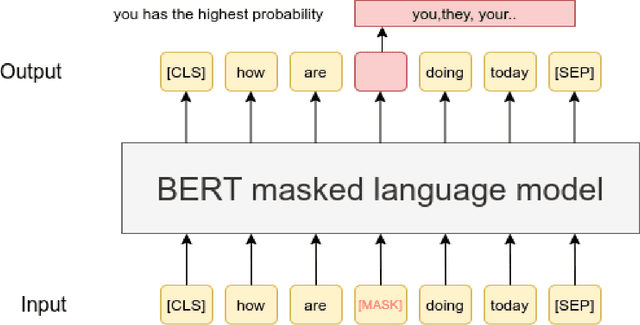


Transformers have recently taken the center stage in language modeling after LSTM's were considered the dominant model architecture for a long time. In this project, we investigate the performance of the Transformer architectures-BERT and Transformer-XL for the language modeling task. We use a sub-word model setting with the Finnish language and compare it to the previous State of the art (SOTA) LSTM model. BERT achieves a pseudo-perplexity score of 14.5, which is the first such measure achieved as far as we know. Transformer-XL improves upon the perplexity score to 73.58 which is 27\% better than the LSTM model.
Morfessor EM+Prune: Improved Subword Segmentation with Expectation Maximization and Pruning
Mar 06, 2020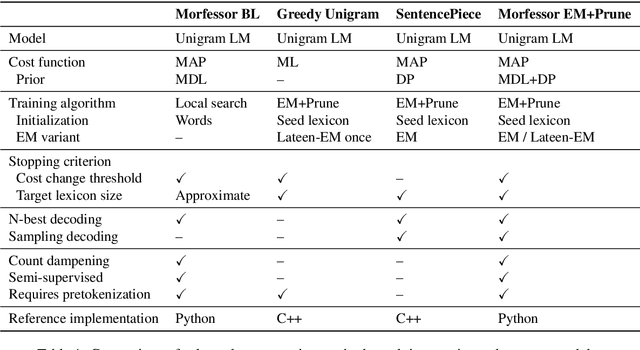
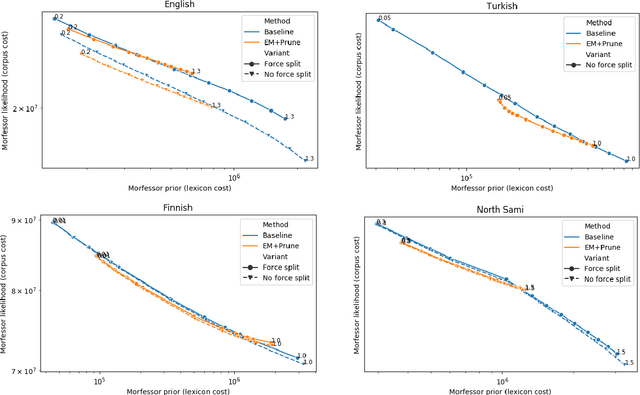
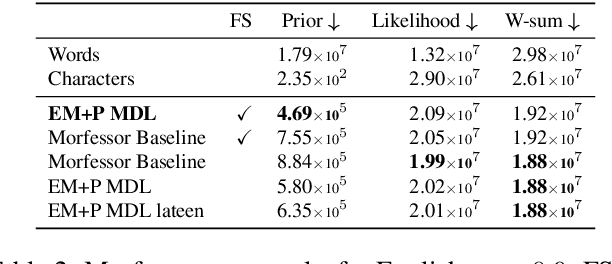
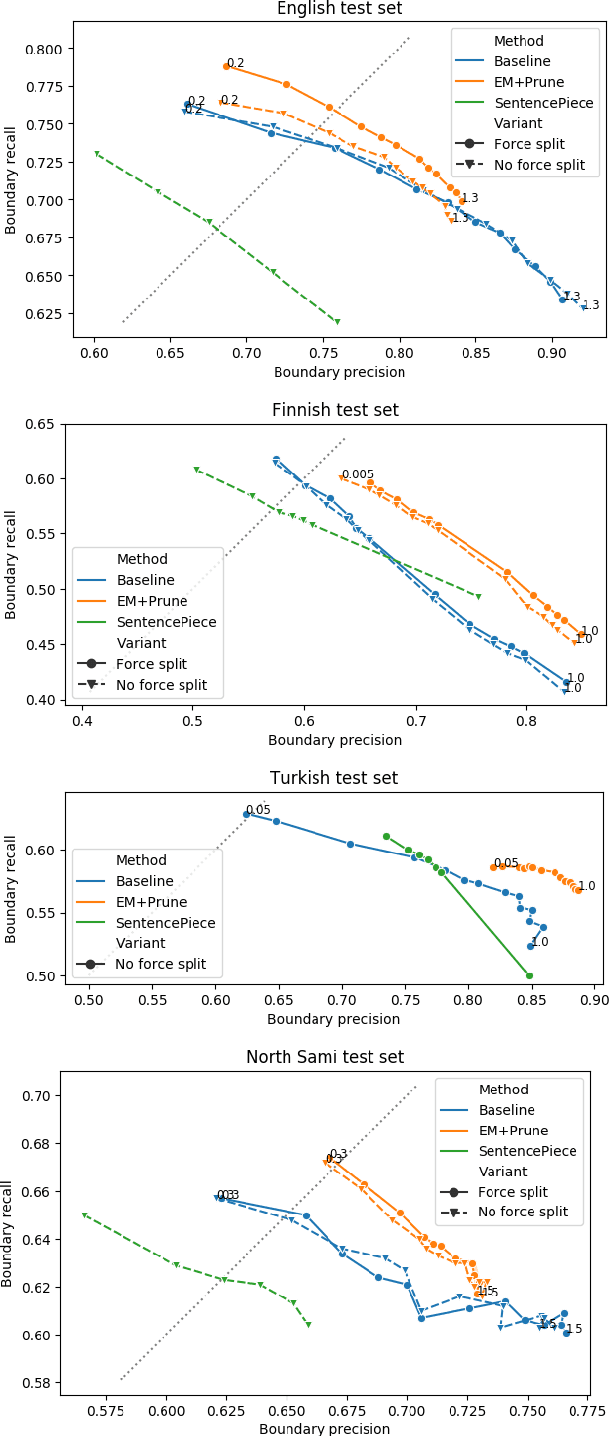
Data-driven segmentation of words into subword units has been used in various natural language processing applications such as automatic speech recognition and statistical machine translation for almost 20 years. Recently it has became more widely adopted, as models based on deep neural networks often benefit from subword units even for morphologically simpler languages. In this paper, we discuss and compare training algorithms for a unigram subword model, based on the Expectation Maximization algorithm and lexicon pruning. Using English, Finnish, North Sami, and Turkish data sets, we show that this approach is able to find better solutions to the optimization problem defined by the Morfessor Baseline model than its original recursive training algorithm. The improved optimization also leads to higher morphological segmentation accuracy when compared to a linguistic gold standard. We publish implementations of the new algorithms in the widely-used Morfessor software package.
Multimodal Machine Translation through Visuals and Speech
Nov 28, 2019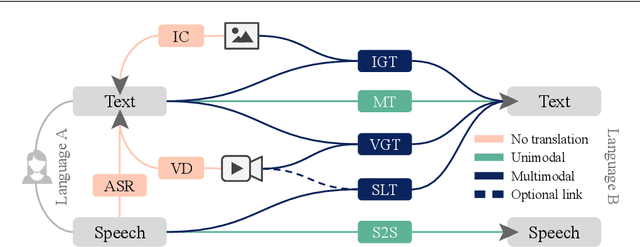
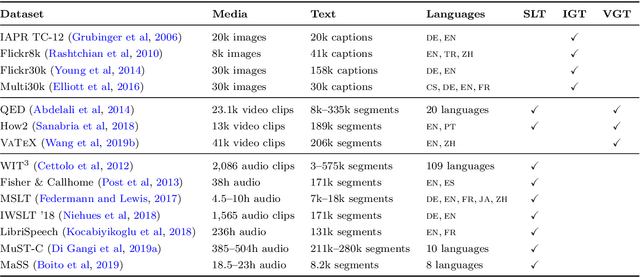

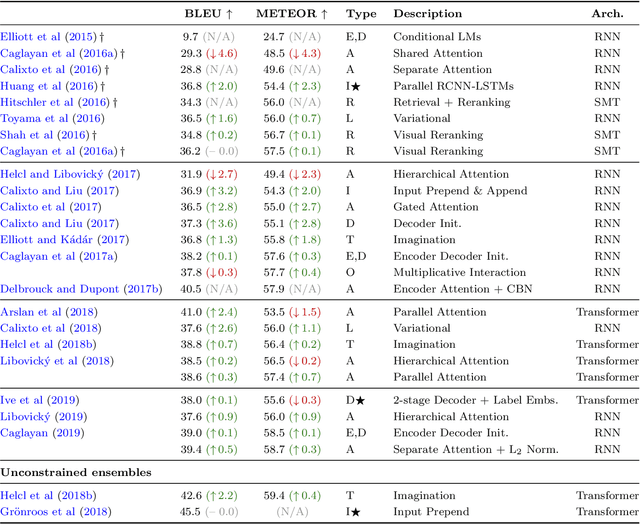
Multimodal machine translation involves drawing information from more than one modality, based on the assumption that the additional modalities will contain useful alternative views of the input data. The most prominent tasks in this area are spoken language translation, image-guided translation, and video-guided translation, which exploit audio and visual modalities, respectively. These tasks are distinguished from their monolingual counterparts of speech recognition, image captioning, and video captioning by the requirement of models to generate outputs in a different language. This survey reviews the major data resources for these tasks, the evaluation campaigns concentrated around them, the state of the art in end-to-end and pipeline approaches, and also the challenges in performance evaluation. The paper concludes with a discussion of directions for future research in these areas: the need for more expansive and challenging datasets, for targeted evaluations of model performance, and for multimodality in both the input and output space.
The MeMAD Submission to the IWSLT 2018 Speech Translation Task
Oct 24, 2018

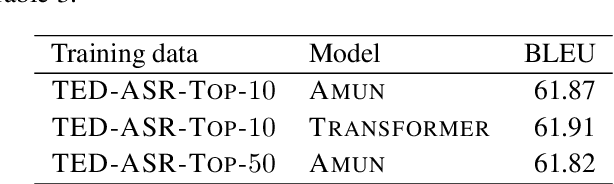

This paper describes the MeMAD project entry to the IWSLT Speech Translation Shared Task, addressing the translation of English audio into German text. Between the pipeline and end-to-end model tracks, we participated only in the former, with three contrastive systems. We tried also the latter, but were not able to finish our end-to-end model in time. All of our systems start by transcribing the audio into text through an automatic speech recognition (ASR) model trained on the TED-LIUM English Speech Recognition Corpus (TED-LIUM). Afterwards, we feed the transcripts into English-German text-based neural machine translation (NMT) models. Our systems employ three different translation models trained on separate training sets compiled from the English-German part of the TED Speech Translation Corpus (TED-Trans) and the OpenSubtitles2018 section of the OPUS collection. In this paper, we also describe the experiments leading up to our final systems. Our experiments indicate that using OpenSubtitles2018 in training significantly improves translation performance. We also experimented with various pre- and postprocessing routines for the NMT module, but we did not have much success with these. Our best-scoring system attains a BLEU score of 16.45 on the test set for this year's task.
The MeMAD Submission to the WMT18 Multimodal Translation Task
Sep 03, 2018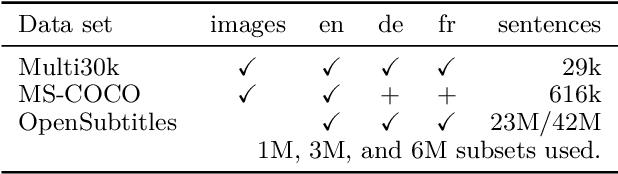
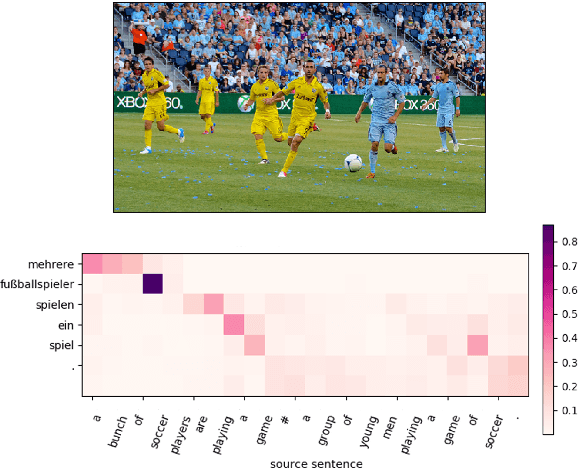
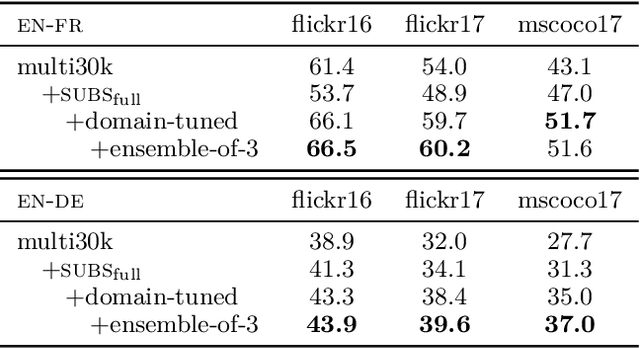

This paper describes the MeMAD project entry to the WMT Multimodal Machine Translation Shared Task. We propose adapting the Transformer neural machine translation (NMT) architecture to a multi-modal setting. In this paper, we also describe the preliminary experiments with text-only translation systems leading us up to this choice. We have the top scoring system for both English-to-German and English-to-French, according to the automatic metrics for flickr18. Our experiments show that the effect of the visual features in our system is small. Our largest gains come from the quality of the underlying text-only NMT system. We find that appropriate use of additional data is effective.