 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer learning and subword sampling for asymmetric-resource one-to-many neural translation
Paper and Code
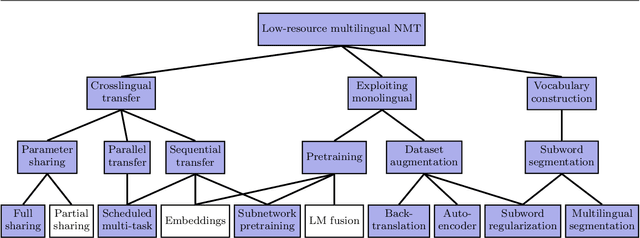

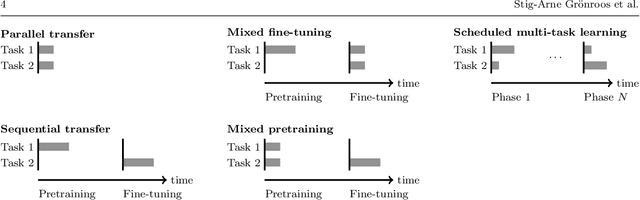
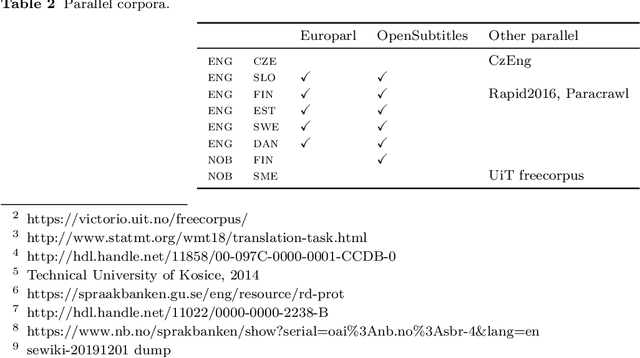
There are several approaches for improving neural machine translation for low-resource languages: Monolingual data can be exploited via pretraining or data augmentation; Parallel corpora on related language pairs can be used via parameter sharing or transfer learning in multilingual models; Subword segmentation and regularization techniques can be applied to ensure high coverage of the vocabulary. We review these approaches in the context of an asymmetric-resource one-to-many translation task, in which the pair of target languages are related, with one being a very low-resource and the other a higher-resource language. We test various methods on three artificially restricted translation tasks---English to Estonian (low-resource) and Finnish (high-resource), English to Slovak and Czech, English to Danish and Swedish---and one real-world task, Norwegian to North S\'ami and Finnish. The experiments show positive effects especially for scheduled multi-task learning, denoising autoencoder, and subword sampling.