 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-Aware Natural Language Inference with Stochastic Weight Averaging
Apr 10, 2023This paper introduces Bayesian uncertainty modeling using Stochastic Weight Averaging-Gaussian (SWAG) in Natural Language Understanding (NLU) tasks. We apply the approach to standard tasks in natural language inference (NLI) and demonstrate the effectiveness of the method in terms of prediction accuracy and correlation with human annotation disagreements. We argue that the uncertainty representations in SWAG better reflect subjective interpretation and the natural variation that is also present in human language understanding. The results reveal the importance of uncertainty modeling, an often neglected aspect of neural language modeling, in NLU tasks.
Democratizing Machine Translation with OPUS-MT
Dec 04, 2022This paper presents the OPUS ecosystem with a focus on the development of open machine translation models and tools, and their integration into end-user applications, development platforms and professional workflows. We discuss our on-going mission of increasing language coverage and translation quality, and also describe on-going work on the development of modular translation models and speed-optimized compact solutions for real-time translation on regular desktops and small devices.
FinChat: Corpus and evaluation setup for Finnish chat conversations on everyday topics
Aug 19, 2020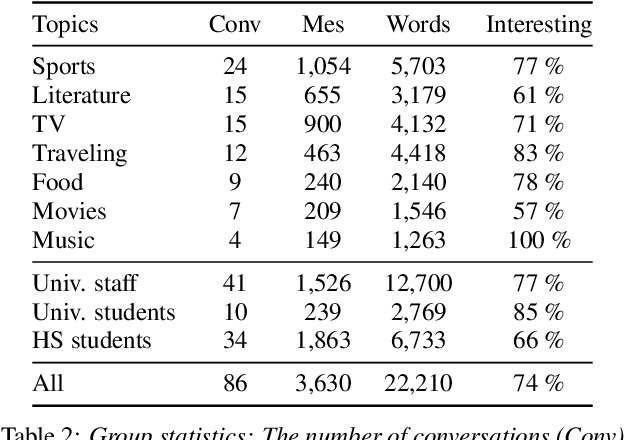
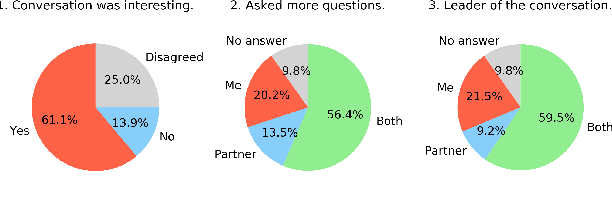
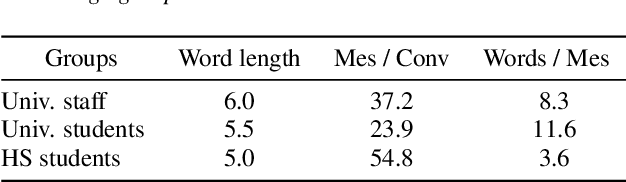
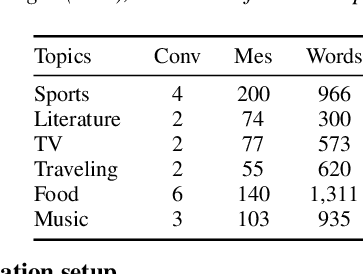
Creating open-domain chatbots requires large amounts of conversational data and related benchmark tasks to evaluate them. Standardized evaluation tasks are crucial for creating automatic evaluation metrics for model development; otherwise, comparing the models would require resource-expensive human evaluation. While chatbot challenges have recently managed to provide a plethora of such resources for English, resources in other languages are not yet available. In this work, we provide a starting point for Finnish open-domain chatbot research. We describe our collection efforts to create the Finnish chat conversation corpus FinChat, which is made available publicly. FinChat includes unscripted conversations on seven topics from people of different ages. Using this corpus, we also construct a retrieval-based evaluation task for Finnish chatbot development. We observe that off-the-shelf chatbot models trained on conversational corpora do not perform better than chance at choosing the right answer based on automatic metrics, while humans can do the same task almost perfectly. Similarly, in a human evaluation, responses to questions from the evaluation set generated by the chatbots are predominantly marked as incoherent. Thus, FinChat provides a challenging evaluation set, meant to encourage chatbot development in Finnish.
Effects of Language Relatedness for Cross-lingual Transfer Learning in Character-Based Language Models
Jul 22, 2020
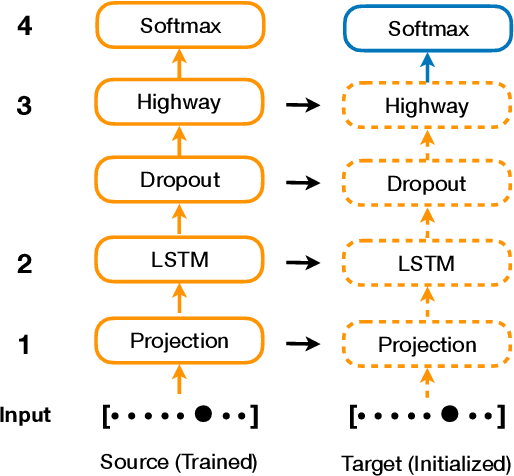
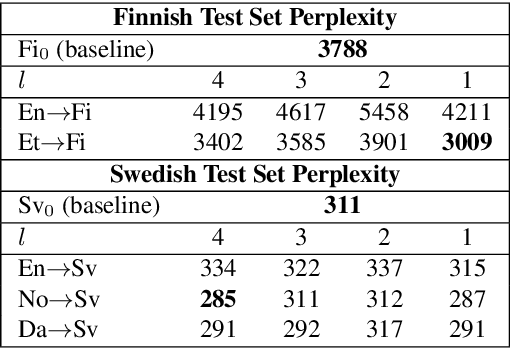

Character-based Neural Network Language Models (NNLM) have the advantage of smaller vocabulary and thus faster training times in comparison to NNLMs based on multi-character units. However, in low-resource scenarios, both the character and multi-character NNLMs suffer from data sparsity. In such scenarios, cross-lingual transfer has improved multi-character NNLM performance by allowing information transfer from a source to the target language. In the same vein, we propose to use cross-lingual transfer for character NNLMs applied to low-resource Automatic Speech Recognition (ASR). However, applying cross-lingual transfer to character NNLMs is not as straightforward. We observe that relatedness of the source language plays an important role in cross-lingual pretraining of character NNLMs. We evaluate this aspect on ASR tasks for two target languages: Finnish (with English and Estonian as source) and Swedish (with Danish, Norwegian, and English as source). Prior work has observed no difference between using the related or unrelated language for multi-character NNLMs. We, however, show that for character-based NNLMs, only pretraining with a related language improves the ASR performance, and using an unrelated language may deteriorate it. We also observe that the benefits are larger when there is much lesser target data than source data.
Subword RNNLM Approximations for Out-Of-Vocabulary Keyword Search
May 28, 2020
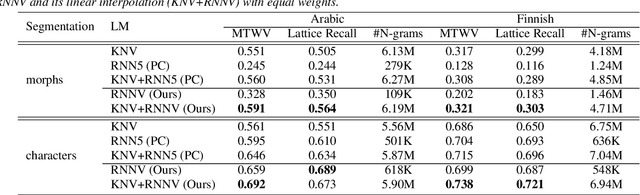
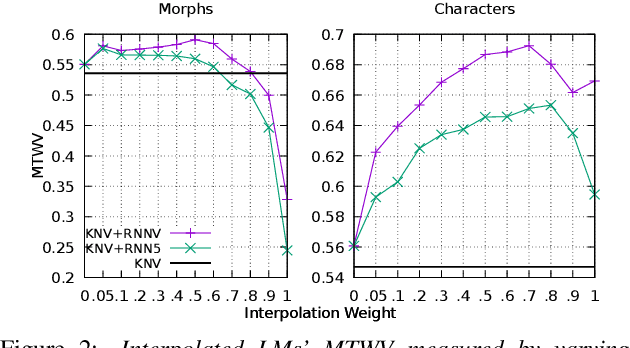
In spoken Keyword Search, the query may contain out-of-vocabulary (OOV) words not observed when training the speech recognition system. Using subword language models (LMs) in the first-pass recognition makes it possible to recognize the OOV words, but even the subword n-gram LMs suffer from data sparsity. Recurrent Neural Network (RNN) LMs alleviate the sparsity problems but are not suitable for first-pass recognition as such. One way to solve this is to approximate the RNNLMs by back-off n-gram models. In this paper, we propose to interpolate the conventional n-gram models and the RNNLM approximation for better OOV recognition. Furthermore, we develop a new RNNLM approximation method suitable for subword units: It produces variable-order n-grams to include long-span approximations and considers also n-grams that were not originally observed in the training corpus. To evaluate these models on OOVs, we setup Arabic and Finnish Keyword Search tasks concentrating only on OOV words. On these tasks, interpolating the baseline RNNLM approximation and a conventional LM outperforms the conventional LM in terms of the Maximum Term Weighted Value for single-character subwords. Moreover, replacing the baseline approximation with the proposed method achieves the best performance on both multi- and single-character subwords.
Transfer learning and subword sampling for asymmetric-resource one-to-many neural translation
Apr 08, 2020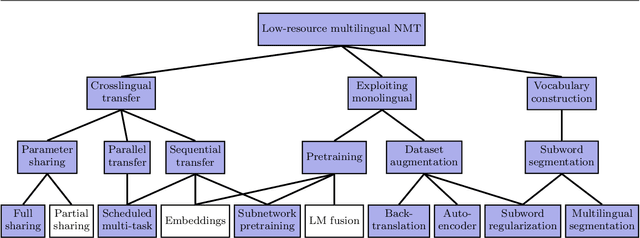

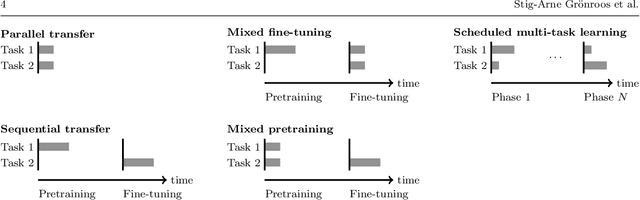
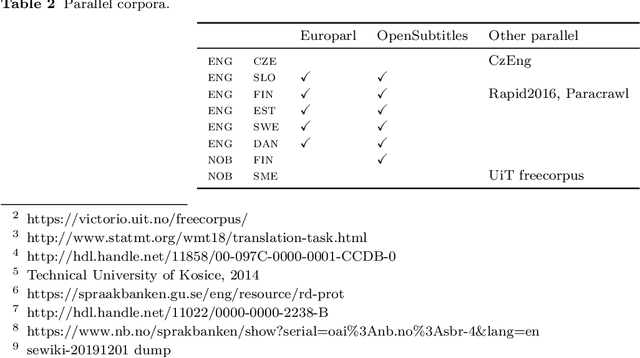
There are several approaches for improving neural machine translation for low-resource languages: Monolingual data can be exploited via pretraining or data augmentation; Parallel corpora on related language pairs can be used via parameter sharing or transfer learning in multilingual models; Subword segmentation and regularization techniques can be applied to ensure high coverage of the vocabulary. We review these approaches in the context of an asymmetric-resource one-to-many translation task, in which the pair of target languages are related, with one being a very low-resource and the other a higher-resource language. We test various methods on three artificially restricted translation tasks---English to Estonian (low-resource) and Finnish (high-resource), English to Slovak and Czech, English to Danish and Swedish---and one real-world task, Norwegian to North S\'ami and Finnish. The experiments show positive effects especially for scheduled multi-task learning, denoising autoencoder, and subword sampling.
Morfessor EM+Prune: Improved Subword Segmentation with Expectation Maximization and Pruning
Mar 06, 2020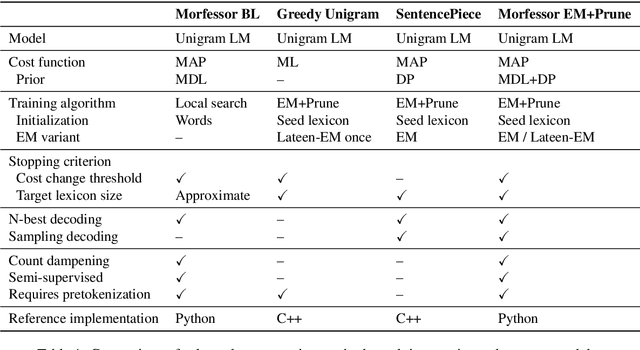
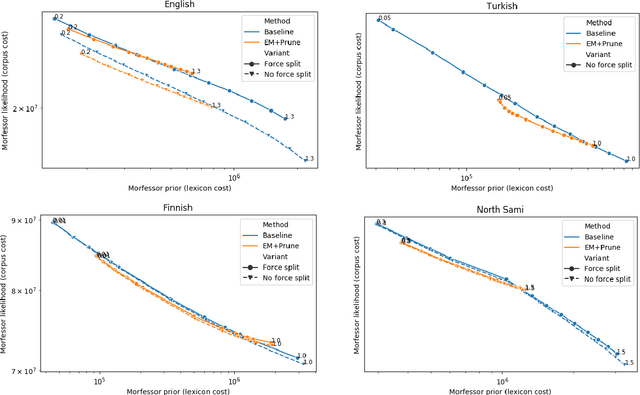
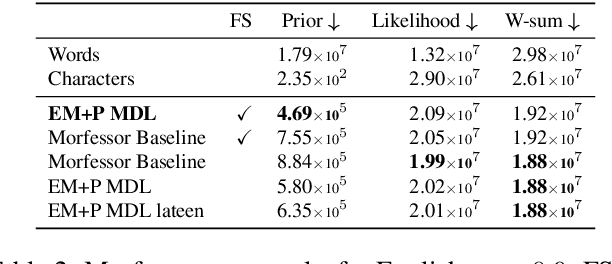
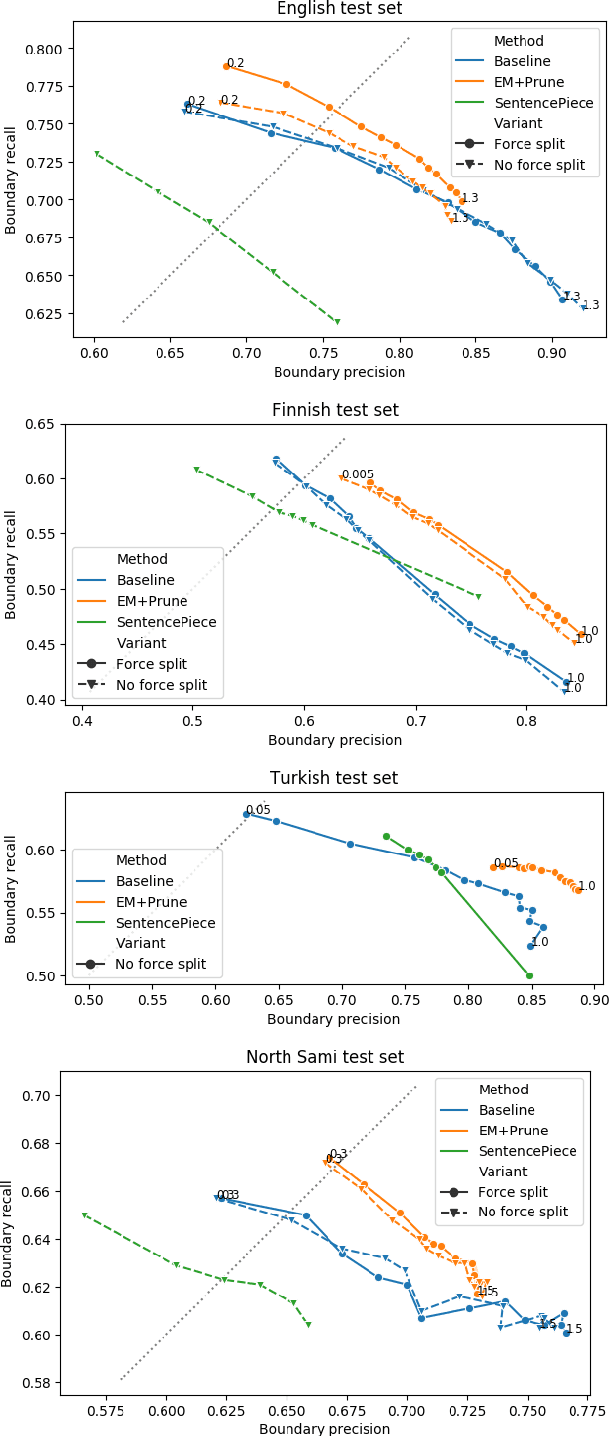
Data-driven segmentation of words into subword units has been used in various natural language processing applications such as automatic speech recognition and statistical machine translation for almost 20 years. Recently it has became more widely adopted, as models based on deep neural networks often benefit from subword units even for morphologically simpler languages. In this paper, we discuss and compare training algorithms for a unigram subword model, based on the Expectation Maximization algorithm and lexicon pruning. Using English, Finnish, North Sami, and Turkish data sets, we show that this approach is able to find better solutions to the optimization problem defined by the Morfessor Baseline model than its original recursive training algorithm. The improved optimization also leads to higher morphological segmentation accuracy when compared to a linguistic gold standard. We publish implementations of the new algorithms in the widely-used Morfessor software package.
The University of Helsinki submissions to the WMT19 news translation task
Jun 10, 2019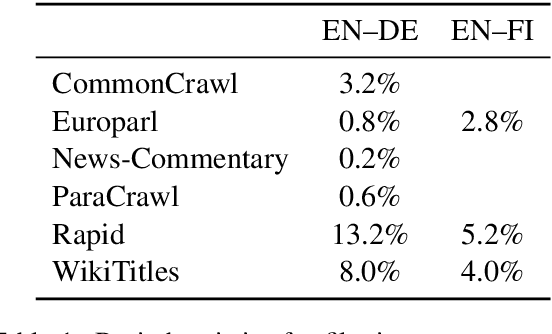
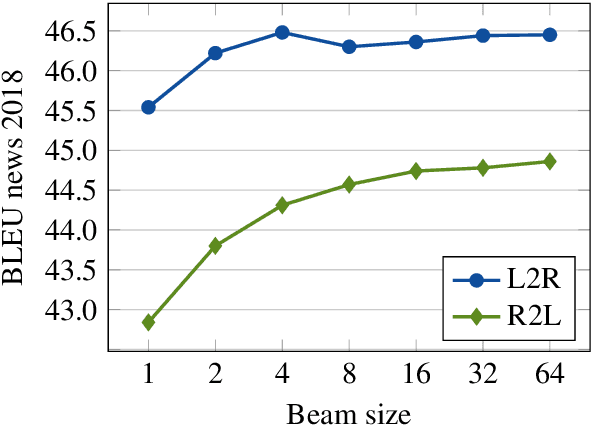

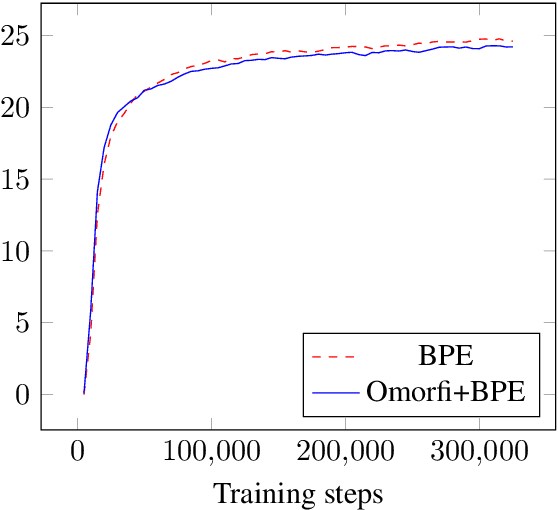
In this paper, we present the University of Helsinki submissions to the WMT 2019 shared task on news translation in three language pairs: English-German, English-Finnish and Finnish-English. This year, we focused first on cleaning and filtering the training data using multiple data-filtering approaches, resulting in much smaller and cleaner training sets. For English-German, we trained both sentence-level transformer models and compared different document-level translation approaches. For Finnish-English and English-Finnish we focused on different segmentation approaches, and we also included a rule-based system for English-Finnish.
Cognate-aware morphological segmentation for multilingual neural translation
Aug 31, 2018
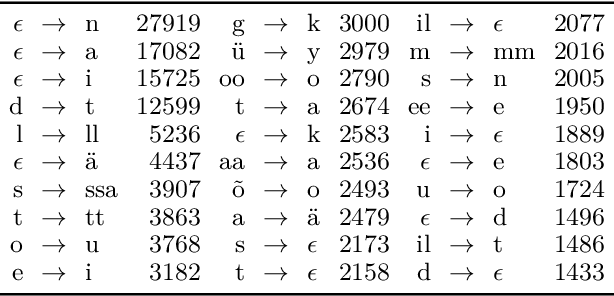
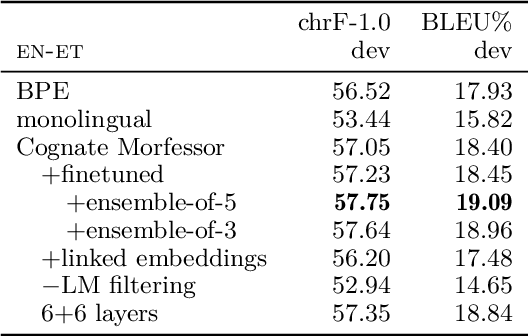
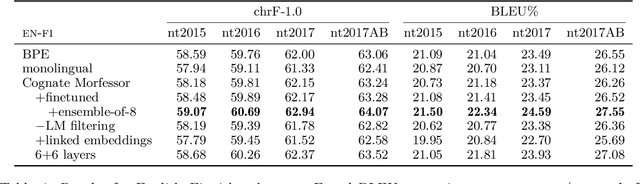
This article describes the Aalto University entry to the WMT18 News Translation Shared Task. We participate in the multilingual subtrack with a system trained under the constrained condition to translate from English to both Finnish and Estonian. The system is based on the Transformer model. We focus on improving the consistency of morphological segmentation for words that are similar orthographically, semantically, and distributionally; such words include etymological cognates, loan words, and proper names. For this, we introduce Cognate Morfessor, a multilingual variant of the Morfessor method. We show that our approach improves the translation quality particularly for Estonian, which has less resources for training the translation model.
Automatic Speech Recognition with Very Large Conversational Finnish and Estonian Vocabularies
Sep 29, 2017



Today, the vocabulary size for language models in large vocabulary speech recognition is typically several hundreds of thousands of words. While this is already sufficient in some applications, the out-of-vocabulary words are still limiting the usability in others. In agglutinative languages the vocabulary for conversational speech should include millions of word forms to cover the spelling variations due to colloquial pronunciations, in addition to the word compounding and inflections. Very large vocabularies are also needed, for example, when the recognition of rare proper names is important.