 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffects of Language Relatedness for Cross-lingual Transfer Learning in Character-Based Language Models
Jul 22, 2020
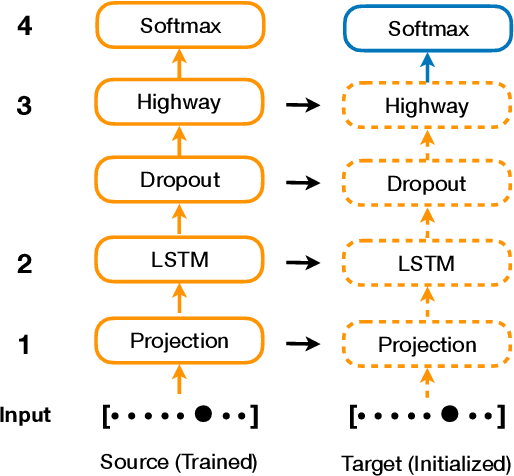
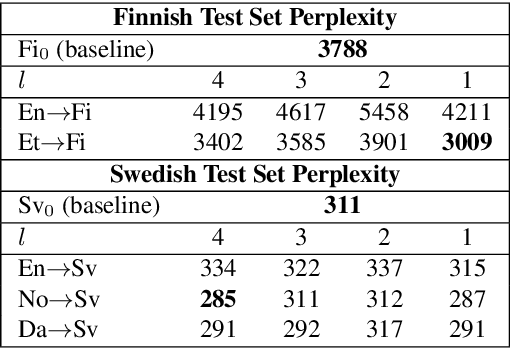

Character-based Neural Network Language Models (NNLM) have the advantage of smaller vocabulary and thus faster training times in comparison to NNLMs based on multi-character units. However, in low-resource scenarios, both the character and multi-character NNLMs suffer from data sparsity. In such scenarios, cross-lingual transfer has improved multi-character NNLM performance by allowing information transfer from a source to the target language. In the same vein, we propose to use cross-lingual transfer for character NNLMs applied to low-resource Automatic Speech Recognition (ASR). However, applying cross-lingual transfer to character NNLMs is not as straightforward. We observe that relatedness of the source language plays an important role in cross-lingual pretraining of character NNLMs. We evaluate this aspect on ASR tasks for two target languages: Finnish (with English and Estonian as source) and Swedish (with Danish, Norwegian, and English as source). Prior work has observed no difference between using the related or unrelated language for multi-character NNLMs. We, however, show that for character-based NNLMs, only pretraining with a related language improves the ASR performance, and using an unrelated language may deteriorate it. We also observe that the benefits are larger when there is much lesser target data than source data.
Subword RNNLM Approximations for Out-Of-Vocabulary Keyword Search
May 28, 2020
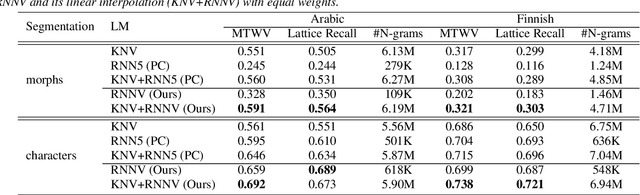
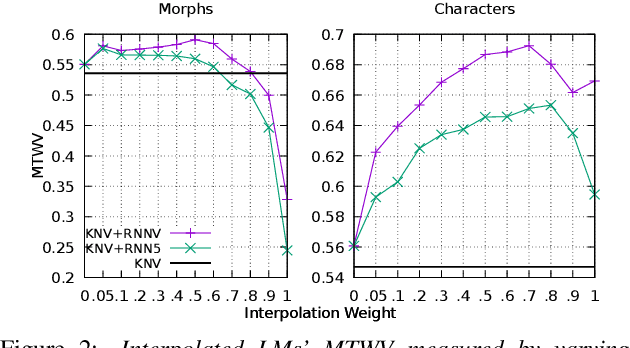
In spoken Keyword Search, the query may contain out-of-vocabulary (OOV) words not observed when training the speech recognition system. Using subword language models (LMs) in the first-pass recognition makes it possible to recognize the OOV words, but even the subword n-gram LMs suffer from data sparsity. Recurrent Neural Network (RNN) LMs alleviate the sparsity problems but are not suitable for first-pass recognition as such. One way to solve this is to approximate the RNNLMs by back-off n-gram models. In this paper, we propose to interpolate the conventional n-gram models and the RNNLM approximation for better OOV recognition. Furthermore, we develop a new RNNLM approximation method suitable for subword units: It produces variable-order n-grams to include long-span approximations and considers also n-grams that were not originally observed in the training corpus. To evaluate these models on OOVs, we setup Arabic and Finnish Keyword Search tasks concentrating only on OOV words. On these tasks, interpolating the baseline RNNLM approximation and a conventional LM outperforms the conventional LM in terms of the Maximum Term Weighted Value for single-character subwords. Moreover, replacing the baseline approximation with the proposed method achieves the best performance on both multi- and single-character subwords.
Automatic Speech Recognition with Very Large Conversational Finnish and Estonian Vocabularies
Sep 29, 2017



Today, the vocabulary size for language models in large vocabulary speech recognition is typically several hundreds of thousands of words. While this is already sufficient in some applications, the out-of-vocabulary words are still limiting the usability in others. In agglutinative languages the vocabulary for conversational speech should include millions of word forms to cover the spelling variations due to colloquial pronunciations, in addition to the word compounding and inflections. Very large vocabularies are also needed, for example, when the recognition of rare proper names is important.