 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-end Ensemble-based Feature Selection for Paralinguistics Tasks
Oct 28, 2022



The events of recent years have highlighted the importance of telemedicine solutions which could potentially allow remote treatment and diagnosis. Relatedly, Computational Paralinguistics, a unique subfield of Speech Processing, aims to extract information about the speaker and form an important part of telemedicine applications. In this work, we focus on two paralinguistic problems: mask detection and breathing state prediction. Solutions developed for these tasks could be invaluable and have the potential to help monitor and limit the spread of a virus like COVID-19. The current state-of-the-art methods proposed for these tasks are ensembles based on deep neural networks like ResNets in conjunction with feature engineering. Although these ensembles can achieve high accuracy, they also have a large footprint and require substantial computational power reducing portability to devices with limited resources. These drawbacks also mean that the previously proposed solutions are infeasible to be used in a telemedicine system due to their size and speed. On the other hand, employing lighter feature-engineered systems can be laborious and add further complexity making them difficult to create a deployable system quickly. This work proposes an ensemble-based automatic feature selection method to enable the development of fast and memory-efficient systems. In particular, we propose an output-gradient-based method to discover essential features using large, well-performing ensembles before training a smaller one. In our experiments, we observed considerable (25-32%) reductions in inference times using neural network ensembles based on output-gradient-based features. Our method offers a simple way to increase the speed of the system and enable real-time usage while maintaining competitive results with larger-footprint ensemble using all spectral features.
Data augmentation using prosody and false starts to recognize non-native children's speech
Aug 29, 2020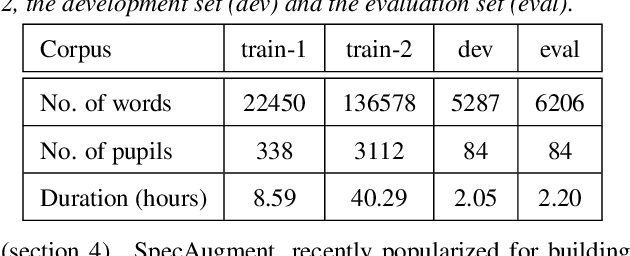
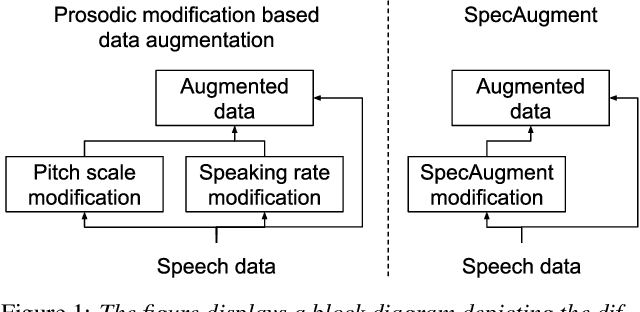
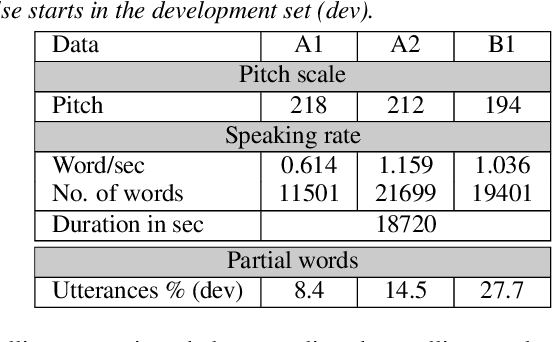
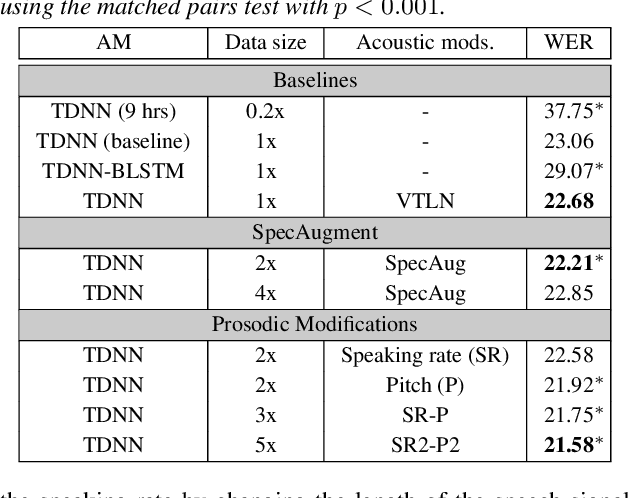
This paper describes AaltoASR's speech recognition system for the INTERSPEECH 2020 shared task on Automatic Speech Recognition (ASR) for non-native children's speech. The task is to recognize non-native speech from children of various age groups given a limited amount of speech. Moreover, the speech being spontaneous has false starts transcribed as partial words, which in the test transcriptions leads to unseen partial words. To cope with these two challenges, we investigate a data augmentation-based approach. Firstly, we apply the prosody-based data augmentation to supplement the audio data. Secondly, we simulate false starts by introducing partial-word noise in the language modeling corpora creating new words. Acoustic models trained on prosody-based augmented data outperform the models using the baseline recipe or the SpecAugment-based augmentation. The partial-word noise also helps to improve the baseline language model. Our ASR system, a combination of these schemes, is placed third in the evaluation period and achieves the word error rate of 18.71%. Post-evaluation period, we observe that increasing the amounts of prosody-based augmented data leads to better performance. Furthermore, removing low-confidence-score words from hypotheses can lead to further gains. These two improvements lower the ASR error rate to 17.99%.
FinChat: Corpus and evaluation setup for Finnish chat conversations on everyday topics
Aug 19, 2020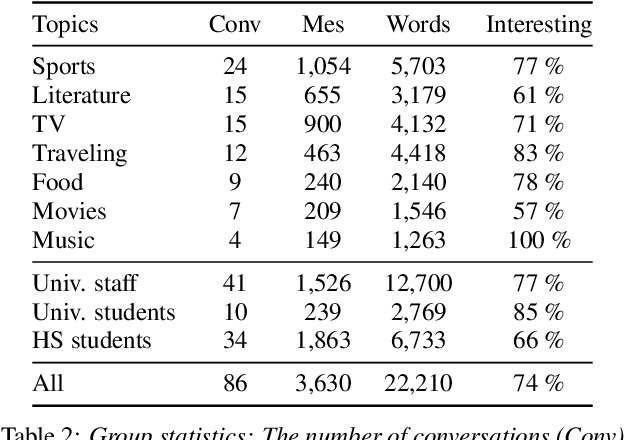
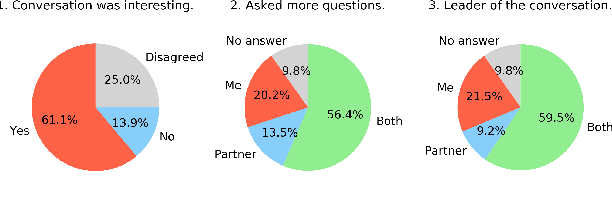
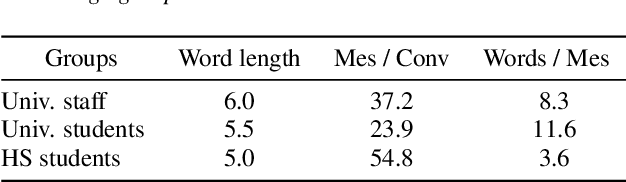
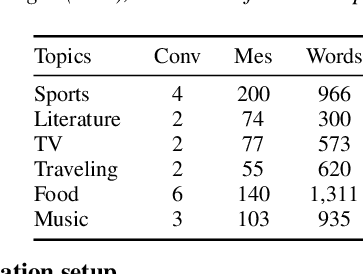
Creating open-domain chatbots requires large amounts of conversational data and related benchmark tasks to evaluate them. Standardized evaluation tasks are crucial for creating automatic evaluation metrics for model development; otherwise, comparing the models would require resource-expensive human evaluation. While chatbot challenges have recently managed to provide a plethora of such resources for English, resources in other languages are not yet available. In this work, we provide a starting point for Finnish open-domain chatbot research. We describe our collection efforts to create the Finnish chat conversation corpus FinChat, which is made available publicly. FinChat includes unscripted conversations on seven topics from people of different ages. Using this corpus, we also construct a retrieval-based evaluation task for Finnish chatbot development. We observe that off-the-shelf chatbot models trained on conversational corpora do not perform better than chance at choosing the right answer based on automatic metrics, while humans can do the same task almost perfectly. Similarly, in a human evaluation, responses to questions from the evaluation set generated by the chatbots are predominantly marked as incoherent. Thus, FinChat provides a challenging evaluation set, meant to encourage chatbot development in Finnish.
Aalto's End-to-End DNN systems for the INTERSPEECH 2020 Computational Paralinguistics Challenge
Aug 06, 2020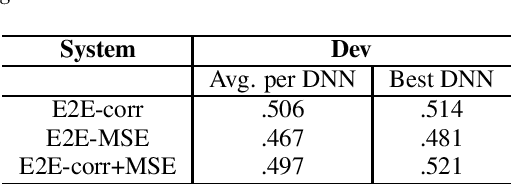
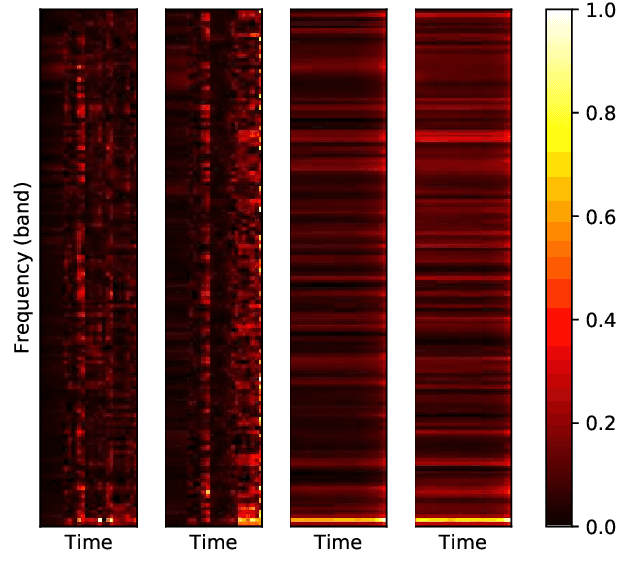
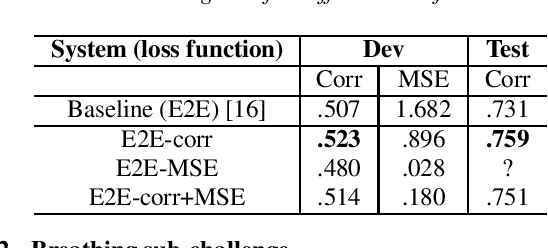
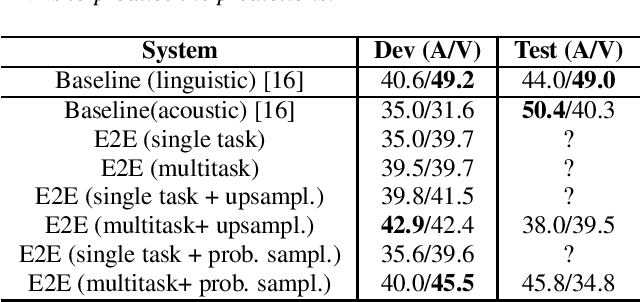
End-to-end neural network models (E2E) have shown significant performance benefits on different INTERSPEECH ComParE tasks. Prior work has applied either a single instance of an E2E model for a task or the same E2E architecture for different tasks. However, applying a single model is unstable or using the same architecture under-utilizes task-specific information. On ComParE 2020 tasks, we investigate applying an ensemble of E2E models for robust performance and developing task-specific modifications for each task. ComParE 2020 introduces three sub-challenges: the breathing sub-challenge to predict the output of a respiratory belt worn by a patient while speaking, the elderly sub-challenge to estimate the elderly speaker's arousal and valence levels and the mask sub-challenge to classify if the speaker is wearing a mask or not. On each of these tasks, an ensemble outperforms the single E2E model. On the breathing sub-challenge, we study the impact of multi-loss strategies on task performance. On the elderly sub-challenge, predicting the valence and arousal levels prompts us to investigate multi-task training and implement data sampling strategies to handle class imbalance. On the mask sub-challenge, using an E2E system without feature engineering is competitive to feature-engineered baselines and provides substantial gains when combined with feature-engineered baselines.
Effects of Language Relatedness for Cross-lingual Transfer Learning in Character-Based Language Models
Jul 22, 2020
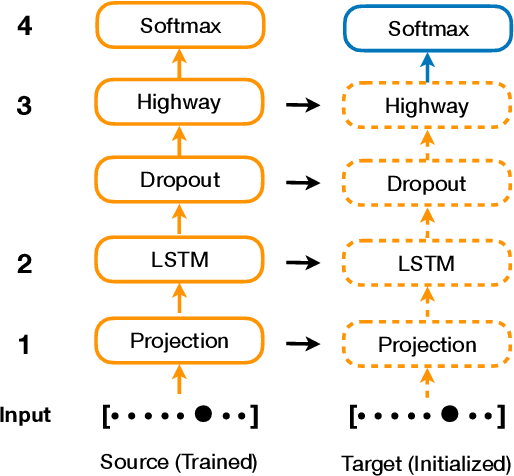
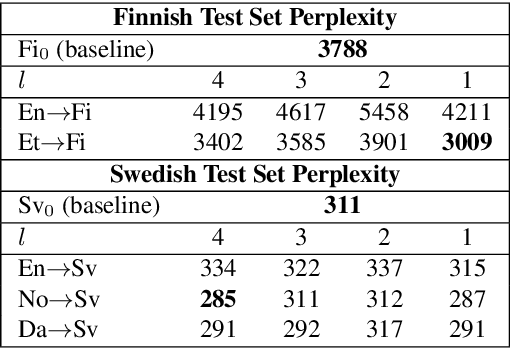

Character-based Neural Network Language Models (NNLM) have the advantage of smaller vocabulary and thus faster training times in comparison to NNLMs based on multi-character units. However, in low-resource scenarios, both the character and multi-character NNLMs suffer from data sparsity. In such scenarios, cross-lingual transfer has improved multi-character NNLM performance by allowing information transfer from a source to the target language. In the same vein, we propose to use cross-lingual transfer for character NNLMs applied to low-resource Automatic Speech Recognition (ASR). However, applying cross-lingual transfer to character NNLMs is not as straightforward. We observe that relatedness of the source language plays an important role in cross-lingual pretraining of character NNLMs. We evaluate this aspect on ASR tasks for two target languages: Finnish (with English and Estonian as source) and Swedish (with Danish, Norwegian, and English as source). Prior work has observed no difference between using the related or unrelated language for multi-character NNLMs. We, however, show that for character-based NNLMs, only pretraining with a related language improves the ASR performance, and using an unrelated language may deteriorate it. We also observe that the benefits are larger when there is much lesser target data than source data.
Subword RNNLM Approximations for Out-Of-Vocabulary Keyword Search
May 28, 2020
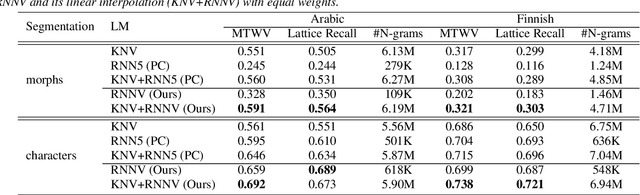
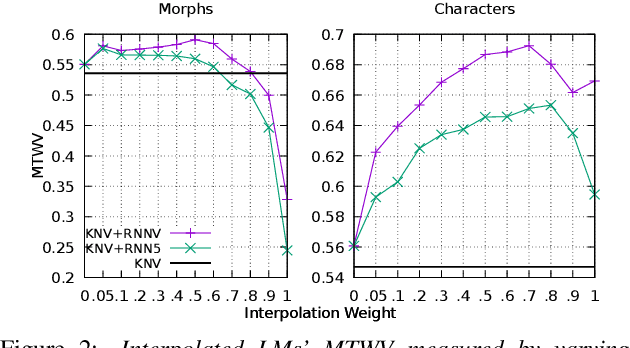
In spoken Keyword Search, the query may contain out-of-vocabulary (OOV) words not observed when training the speech recognition system. Using subword language models (LMs) in the first-pass recognition makes it possible to recognize the OOV words, but even the subword n-gram LMs suffer from data sparsity. Recurrent Neural Network (RNN) LMs alleviate the sparsity problems but are not suitable for first-pass recognition as such. One way to solve this is to approximate the RNNLMs by back-off n-gram models. In this paper, we propose to interpolate the conventional n-gram models and the RNNLM approximation for better OOV recognition. Furthermore, we develop a new RNNLM approximation method suitable for subword units: It produces variable-order n-grams to include long-span approximations and considers also n-grams that were not originally observed in the training corpus. To evaluate these models on OOVs, we setup Arabic and Finnish Keyword Search tasks concentrating only on OOV words. On these tasks, interpolating the baseline RNNLM approximation and a conventional LM outperforms the conventional LM in terms of the Maximum Term Weighted Value for single-character subwords. Moreover, replacing the baseline approximation with the proposed method achieves the best performance on both multi- and single-character subwords.
Handling Noisy Labels for Robustly Learning from Self-Training Data for Low-Resource Sequence Labeling
Mar 28, 2019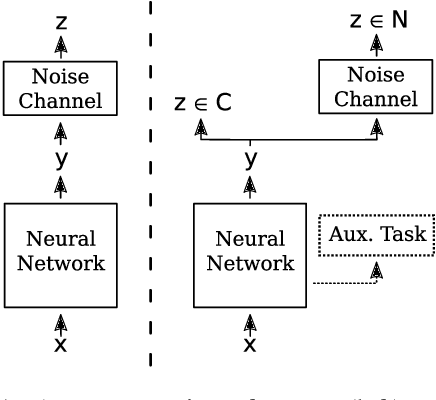

In this paper, we address the problem of effectively self-training neural networks in a low-resource setting. Self-training is frequently used to automatically increase the amount of training data. However, in a low-resource scenario, it is less effective due to unreliable annotations created using self-labeling of unlabeled data. We propose to combine self-training with noise handling on the self-labeled data. Directly estimating noise on the combined clean training set and self-labeled data can lead to corruption of the clean data and hence, performs worse. Thus, we propose the Clean and Noisy Label Neural Network which trains on clean and noisy self-labeled data simultaneously by explicitly modelling clean and noisy labels separately. In our experiments on Chunking and NER, this approach performs more robustly than the baselines. Complementary to this explicit approach, noise can also be handled implicitly with the help of an auxiliary learning task. To such a complementary approach, our method is more beneficial than other baseline methods and together provides the best performance overall.
Long-Short Range Context Neural Networks for Language Modeling
Aug 22, 2017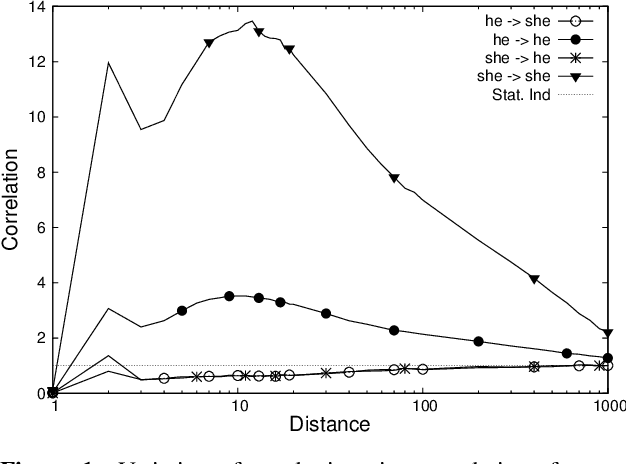

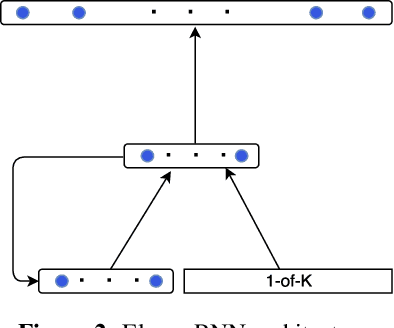
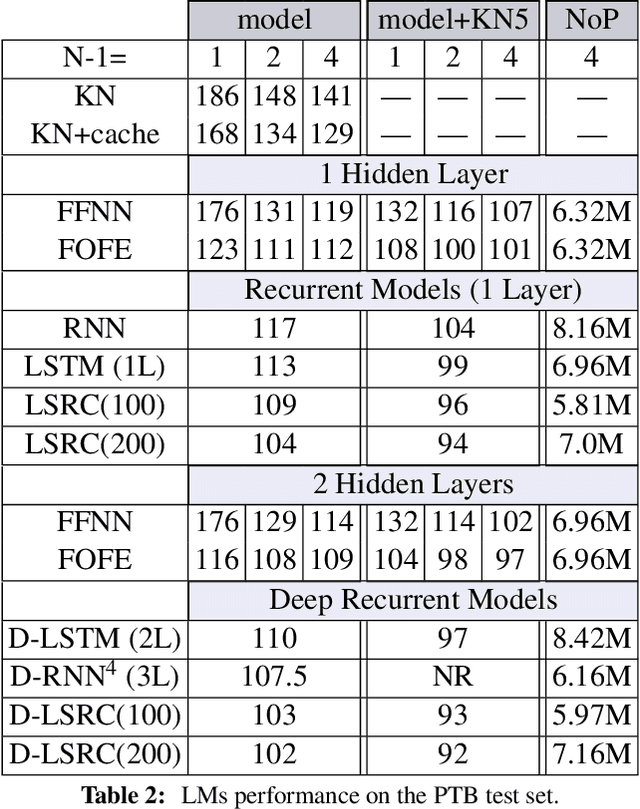
The goal of language modeling techniques is to capture the statistical and structural properties of natural languages from training corpora. This task typically involves the learning of short range dependencies, which generally model the syntactic properties of a language and/or long range dependencies, which are semantic in nature. We propose in this paper a new multi-span architecture, which separately models the short and long context information while it dynamically merges them to perform the language modeling task. This is done through a novel recurrent Long-Short Range Context (LSRC) network, which explicitly models the local (short) and global (long) context using two separate hidden states that evolve in time. This new architecture is an adaptation of the Long-Short Term Memory network (LSTM) to take into account the linguistic properties. Extensive experiments conducted on the Penn Treebank (PTB) and the Large Text Compression Benchmark (LTCB) corpus showed a significant reduction of the perplexity when compared to state-of-the-art language modeling techniques.
Sequential Recurrent Neural Networks for Language Modeling
Mar 23, 2017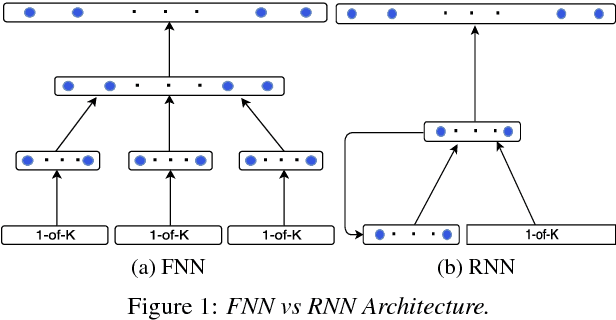
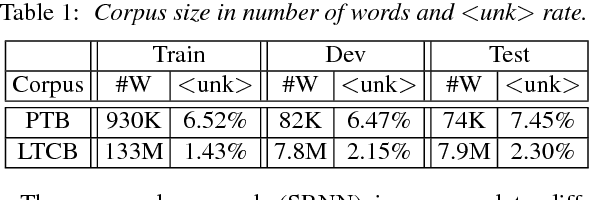
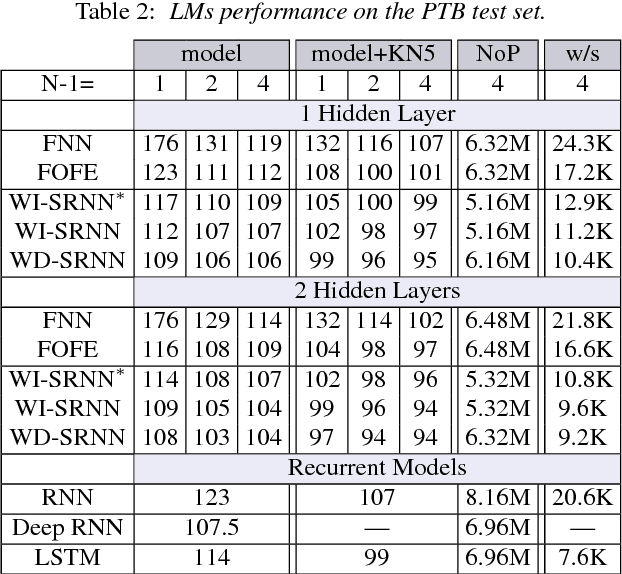
Feedforward Neural Network (FNN)-based language models estimate the probability of the next word based on the history of the last N words, whereas Recurrent Neural Networks (RNN) perform the same task based only on the last word and some context information that cycles in the network. This paper presents a novel approach, which bridges the gap between these two categories of networks. In particular, we propose an architecture which takes advantage of the explicit, sequential enumeration of the word history in FNN structure while enhancing each word representation at the projection layer through recurrent context information that evolves in the network. The context integration is performed using an additional word-dependent weight matrix that is also learned during the training. Extensive experiments conducted on the Penn Treebank (PTB) and the Large Text Compression Benchmark (LTCB) corpus showed a significant reduction of the perplexity when compared to state-of-the-art feedforward as well as recurrent neural network architectures.
Effective Slot Filling Based on Shallow Distant Supervision Methods
Jan 06, 2014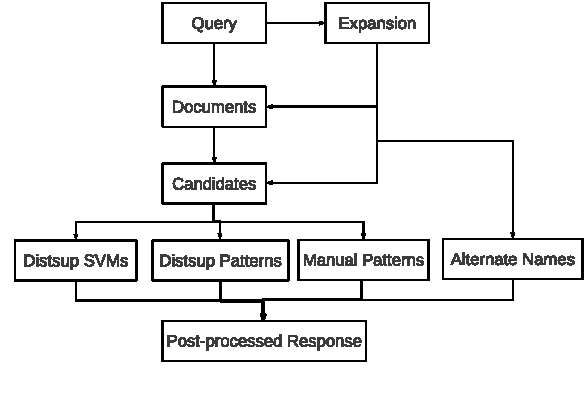


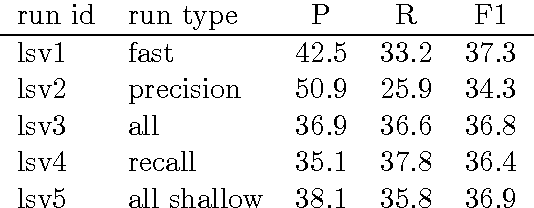
Spoken Language Systems at Saarland University (LSV) participated this year with 5 runs at the TAC KBP English slot filling track. Effective algorithms for all parts of the pipeline, from document retrieval to relation prediction and response post-processing, are bundled in a modular end-to-end relation extraction system called RelationFactory. The main run solely focuses on shallow techniques and achieved significant improvements over LSV's last year's system, while using the same training data and patterns. Improvements mainly have been obtained by a feature representation focusing on surface skip n-grams and improved scoring for extracted distant supervision patterns. Important factors for effective extraction are the training and tuning scheme for distant supervision classifiers, and the query expansion by a translation model based on Wikipedia links. In the TAC KBP 2013 English Slotfilling evaluation, the submitted main run of the LSV RelationFactory system achieved the top-ranked F1-score of 37.3%.