 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubword RNNLM Approximations for Out-Of-Vocabulary Keyword Search
Paper and Code

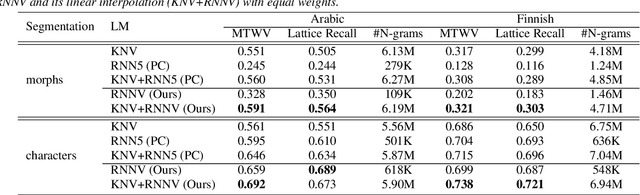
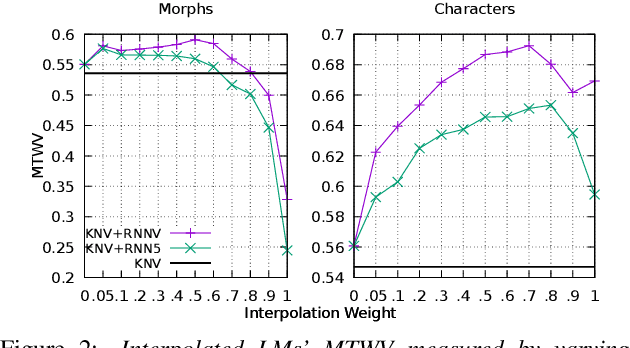
In spoken Keyword Search, the query may contain out-of-vocabulary (OOV) words not observed when training the speech recognition system. Using subword language models (LMs) in the first-pass recognition makes it possible to recognize the OOV words, but even the subword n-gram LMs suffer from data sparsity. Recurrent Neural Network (RNN) LMs alleviate the sparsity problems but are not suitable for first-pass recognition as such. One way to solve this is to approximate the RNNLMs by back-off n-gram models. In this paper, we propose to interpolate the conventional n-gram models and the RNNLM approximation for better OOV recognition. Furthermore, we develop a new RNNLM approximation method suitable for subword units: It produces variable-order n-grams to include long-span approximations and considers also n-grams that were not originally observed in the training corpus. To evaluate these models on OOVs, we setup Arabic and Finnish Keyword Search tasks concentrating only on OOV words. On these tasks, interpolating the baseline RNNLM approximation and a conventional LM outperforms the conventional LM in terms of the Maximum Term Weighted Value for single-character subwords. Moreover, replacing the baseline approximation with the proposed method achieves the best performance on both multi- and single-character subwords.