 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-end Ensemble-based Feature Selection for Paralinguistics Tasks
Oct 28, 2022



The events of recent years have highlighted the importance of telemedicine solutions which could potentially allow remote treatment and diagnosis. Relatedly, Computational Paralinguistics, a unique subfield of Speech Processing, aims to extract information about the speaker and form an important part of telemedicine applications. In this work, we focus on two paralinguistic problems: mask detection and breathing state prediction. Solutions developed for these tasks could be invaluable and have the potential to help monitor and limit the spread of a virus like COVID-19. The current state-of-the-art methods proposed for these tasks are ensembles based on deep neural networks like ResNets in conjunction with feature engineering. Although these ensembles can achieve high accuracy, they also have a large footprint and require substantial computational power reducing portability to devices with limited resources. These drawbacks also mean that the previously proposed solutions are infeasible to be used in a telemedicine system due to their size and speed. On the other hand, employing lighter feature-engineered systems can be laborious and add further complexity making them difficult to create a deployable system quickly. This work proposes an ensemble-based automatic feature selection method to enable the development of fast and memory-efficient systems. In particular, we propose an output-gradient-based method to discover essential features using large, well-performing ensembles before training a smaller one. In our experiments, we observed considerable (25-32%) reductions in inference times using neural network ensembles based on output-gradient-based features. Our method offers a simple way to increase the speed of the system and enable real-time usage while maintaining competitive results with larger-footprint ensemble using all spectral features.
Data augmentation using prosody and false starts to recognize non-native children's speech
Aug 29, 2020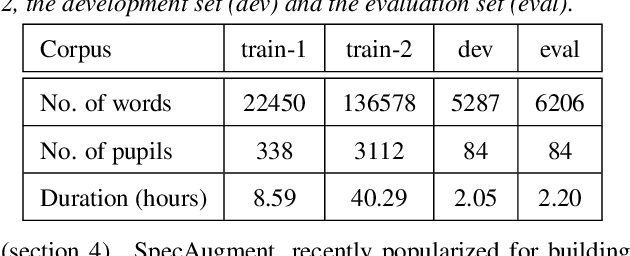
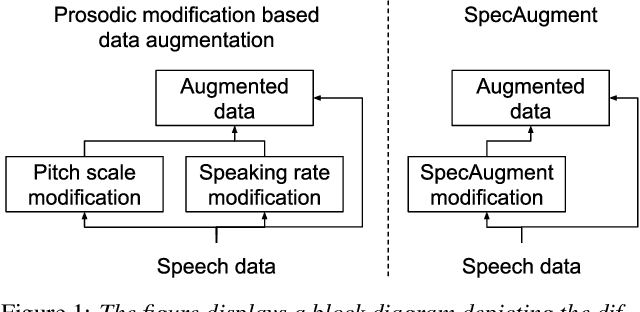
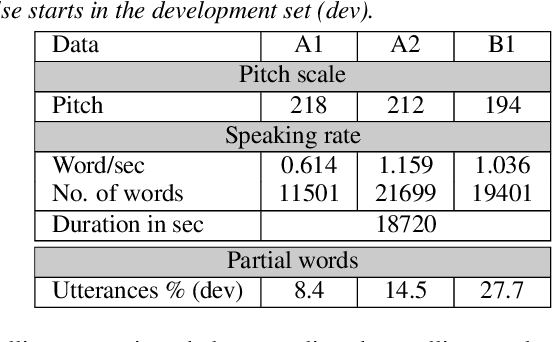
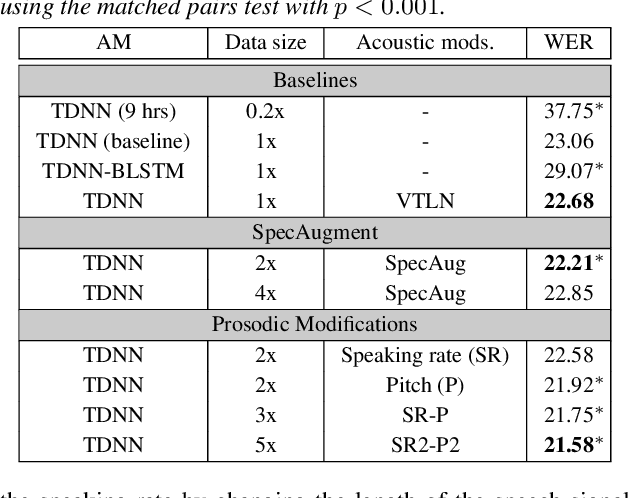
This paper describes AaltoASR's speech recognition system for the INTERSPEECH 2020 shared task on Automatic Speech Recognition (ASR) for non-native children's speech. The task is to recognize non-native speech from children of various age groups given a limited amount of speech. Moreover, the speech being spontaneous has false starts transcribed as partial words, which in the test transcriptions leads to unseen partial words. To cope with these two challenges, we investigate a data augmentation-based approach. Firstly, we apply the prosody-based data augmentation to supplement the audio data. Secondly, we simulate false starts by introducing partial-word noise in the language modeling corpora creating new words. Acoustic models trained on prosody-based augmented data outperform the models using the baseline recipe or the SpecAugment-based augmentation. The partial-word noise also helps to improve the baseline language model. Our ASR system, a combination of these schemes, is placed third in the evaluation period and achieves the word error rate of 18.71%. Post-evaluation period, we observe that increasing the amounts of prosody-based augmented data leads to better performance. Furthermore, removing low-confidence-score words from hypotheses can lead to further gains. These two improvements lower the ASR error rate to 17.99%.
Aalto's End-to-End DNN systems for the INTERSPEECH 2020 Computational Paralinguistics Challenge
Aug 06, 2020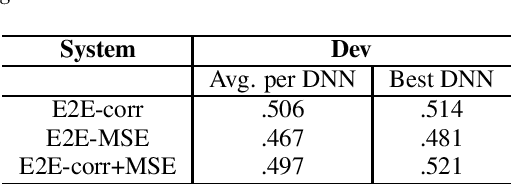
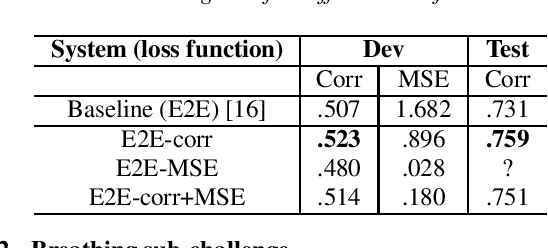
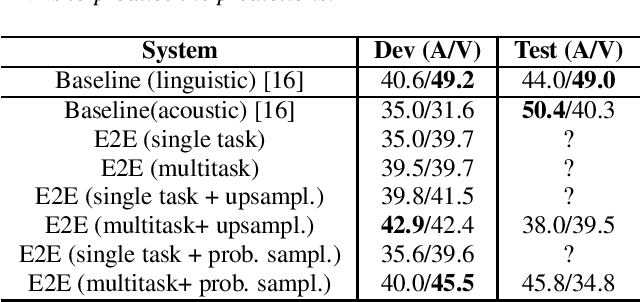
End-to-end neural network models (E2E) have shown significant performance benefits on different INTERSPEECH ComParE tasks. Prior work has applied either a single instance of an E2E model for a task or the same E2E architecture for different tasks. However, applying a single model is unstable or using the same architecture under-utilizes task-specific information. On ComParE 2020 tasks, we investigate applying an ensemble of E2E models for robust performance and developing task-specific modifications for each task. ComParE 2020 introduces three sub-challenges: the breathing sub-challenge to predict the output of a respiratory belt worn by a patient while speaking, the elderly sub-challenge to estimate the elderly speaker's arousal and valence levels and the mask sub-challenge to classify if the speaker is wearing a mask or not. On each of these tasks, an ensemble outperforms the single E2E model. On the breathing sub-challenge, we study the impact of multi-loss strategies on task performance. On the elderly sub-challenge, predicting the valence and arousal levels prompts us to investigate multi-task training and implement data sampling strategies to handle class imbalance. On the mask sub-challenge, using an E2E system without feature engineering is competitive to feature-engineered baselines and provides substantial gains when combined with feature-engineered baselines.