 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Whisper to Grade Them All
Jul 23, 2025We present an efficient end-to-end approach for holistic Automatic Speaking Assessment (ASA) of multi-part second-language tests, developed for the 2025 Speak & Improve Challenge. Our system's main novelty is the ability to process all four spoken responses with a single Whisper-small encoder, combine all information via a lightweight aggregator, and predict the final score. This architecture removes the need for transcription and per-part models, cuts inference time, and makes ASA practical for large-scale Computer-Assisted Language Learning systems. Our system achieved a Root Mean Squared Error (RMSE) of 0.384, outperforming the text-based baseline (0.44) while using at most 168M parameters (about 70% of Whisper-small). Furthermore, we propose a data sampling strategy, allowing the model to train on only 44.8% of the speakers in the corpus and still reach 0.383 RMSE, demonstrating improved performance on imbalanced classes and strong data efficiency.
Multi-Teacher Language-Aware Knowledge Distillation for Multilingual Speech Emotion Recognition
Jun 10, 2025Speech Emotion Recognition (SER) is crucial for improving human-computer interaction. Despite strides in monolingual SER, extending them to build a multilingual system remains challenging. Our goal is to train a single model capable of multilingual SER by distilling knowledge from multiple teacher models. To address this, we introduce a novel language-aware multi-teacher knowledge distillation method to advance SER in English, Finnish, and French. It leverages Wav2Vec2.0 as the foundation of monolingual teacher models and then distills their knowledge into a single multilingual student model. The student model demonstrates state-of-the-art performance, with a weighted recall of 72.9 on the English dataset and an unweighted recall of 63.4 on the Finnish dataset, surpassing fine-tuning and knowledge distillation baselines. Our method excels in improving recall for sad and neutral emotions, although it still faces challenges in recognizing anger and happiness.
Non-native Children's Automatic Speech Assessment Challenge (NOCASA)
Apr 29, 2025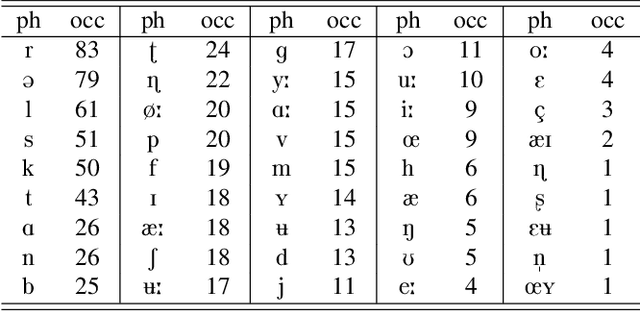
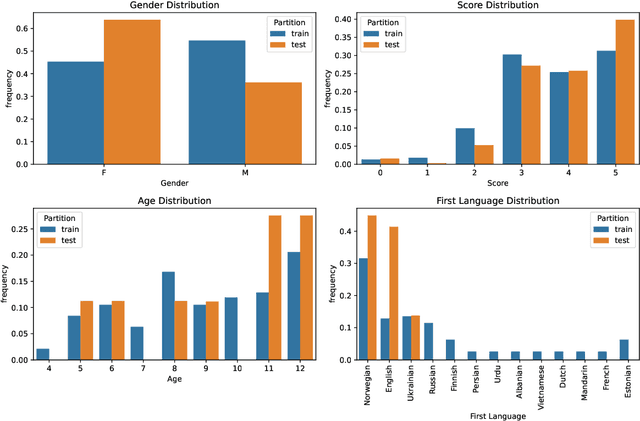

This paper presents the "Non-native Children's Automatic Speech Assessment" (NOCASA) - a data competition part of the IEEE MLSP 2025 conference. NOCASA challenges participants to develop new systems that can assess single-word pronunciations of young second language (L2) learners as part of a gamified pronunciation training app. To achieve this, several issues must be addressed, most notably the limited nature of available training data and the highly unbalanced distribution among the pronunciation level categories. To expedite the development, we provide a pseudo-anonymized training data (TeflonNorL2), containing 10,334 recordings from 44 speakers attempting to pronounce 205 distinct Norwegian words, human-rated on a 1 to 5 scale (number of stars that should be given in the game). In addition to the data, two already trained systems are released as official baselines: an SVM classifier trained on the ComParE_16 acoustic feature set and a multi-task wav2vec 2.0 model. The latter achieves the best performance on the challenge test set, with an unweighted average recall (UAR) of 36.37%.
Advancing Audio Emotion and Intent Recognition with Large Pre-Trained Models and Bayesian Inference
Oct 16, 2023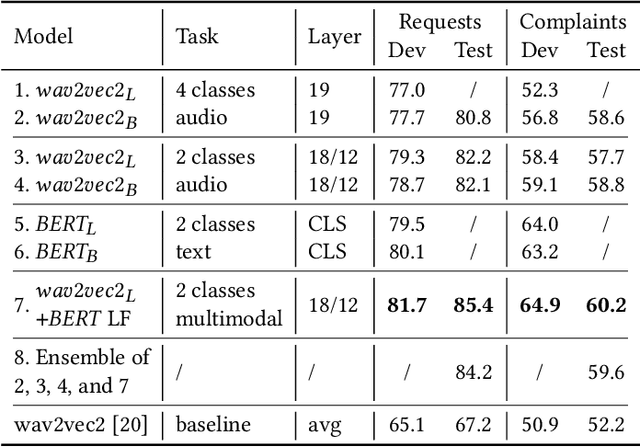

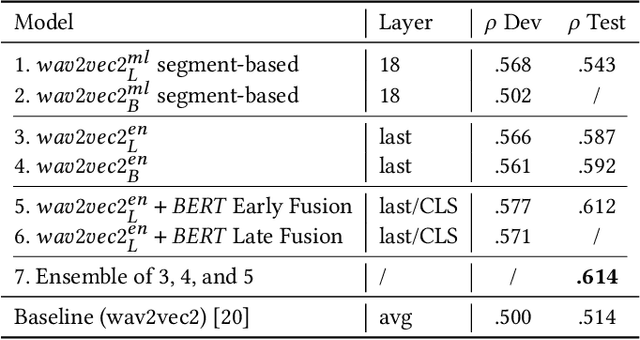
Large pre-trained models are essential in paralinguistic systems, demonstrating effectiveness in tasks like emotion recognition and stuttering detection. In this paper, we employ large pre-trained models for the ACM Multimedia Computational Paralinguistics Challenge, addressing the Requests and Emotion Share tasks. We explore audio-only and hybrid solutions leveraging audio and text modalities. Our empirical results consistently show the superiority of the hybrid approaches over the audio-only models. Moreover, we introduce a Bayesian layer as an alternative to the standard linear output layer. The multimodal fusion approach achieves an 85.4% UAR on HC-Requests and 60.2% on HC-Complaints. The ensemble model for the Emotion Share task yields the best rho value of .614. The Bayesian wav2vec2 approach, explored in this study, allows us to easily build ensembles, at the cost of fine-tuning only one model. Moreover, we can have usable confidence values instead of the usual overconfident posterior probabilities.
Topic Identification For Spontaneous Speech: Enriching Audio Features With Embedded Linguistic Information
Jul 21, 2023Traditional topic identification solutions from audio rely on an automatic speech recognition system (ASR) to produce transcripts used as input to a text-based model. These approaches work well in high-resource scenarios, where there are sufficient data to train both components of the pipeline. However, in low-resource situations, the ASR system, even if available, produces low-quality transcripts, leading to a bad text-based classifier. Moreover, spontaneous speech containing hesitations can further degrade the performance of the ASR model. In this paper, we investigate alternatives to the standard text-only solutions by comparing audio-only and hybrid techniques of jointly utilising text and audio features. The models evaluated on spontaneous Finnish speech demonstrate that purely audio-based solutions are a viable option when ASR components are not available, while the hybrid multi-modal solutions achieve the best results.
End-to-end Ensemble-based Feature Selection for Paralinguistics Tasks
Oct 28, 2022



The events of recent years have highlighted the importance of telemedicine solutions which could potentially allow remote treatment and diagnosis. Relatedly, Computational Paralinguistics, a unique subfield of Speech Processing, aims to extract information about the speaker and form an important part of telemedicine applications. In this work, we focus on two paralinguistic problems: mask detection and breathing state prediction. Solutions developed for these tasks could be invaluable and have the potential to help monitor and limit the spread of a virus like COVID-19. The current state-of-the-art methods proposed for these tasks are ensembles based on deep neural networks like ResNets in conjunction with feature engineering. Although these ensembles can achieve high accuracy, they also have a large footprint and require substantial computational power reducing portability to devices with limited resources. These drawbacks also mean that the previously proposed solutions are infeasible to be used in a telemedicine system due to their size and speed. On the other hand, employing lighter feature-engineered systems can be laborious and add further complexity making them difficult to create a deployable system quickly. This work proposes an ensemble-based automatic feature selection method to enable the development of fast and memory-efficient systems. In particular, we propose an output-gradient-based method to discover essential features using large, well-performing ensembles before training a smaller one. In our experiments, we observed considerable (25-32%) reductions in inference times using neural network ensembles based on output-gradient-based features. Our method offers a simple way to increase the speed of the system and enable real-time usage while maintaining competitive results with larger-footprint ensemble using all spectral features.
Comparison and Analysis of New Curriculum Criteria for End-to-End ASR
Aug 10, 2022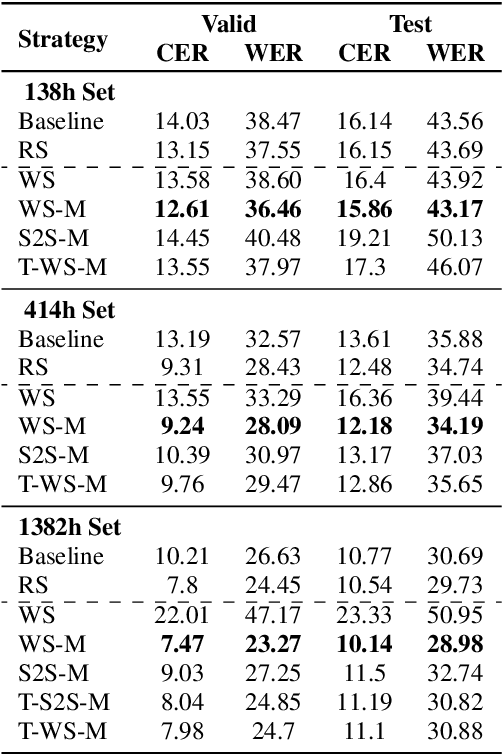
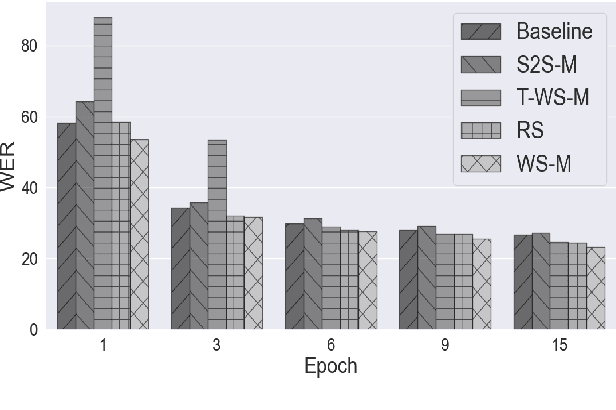
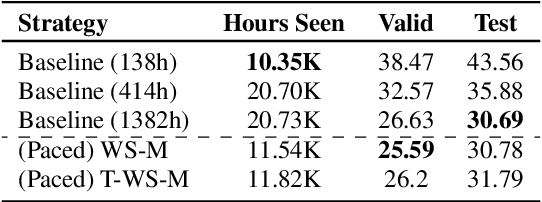
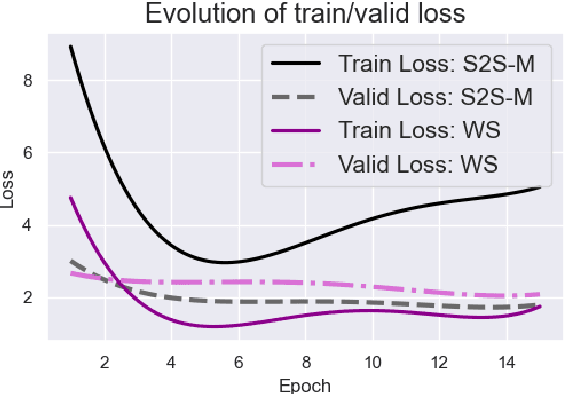
It is common knowledge that the quantity and quality of the training data play a significant role in the creation of a good machine learning model. In this paper, we take it one step further and demonstrate that the way the training examples are arranged is also of crucial importance. Curriculum Learning is built on the observation that organized and structured assimilation of knowledge has the ability to enable faster training and better comprehension. When humans learn to speak, they first try to utter basic phones and then gradually move towards more complex structures such as words and sentences. This methodology is known as Curriculum Learning, and we employ it in the context of Automatic Speech Recognition. We hypothesize that end-to-end models can achieve better performance when provided with an organized training set consisting of examples that exhibit an increasing level of difficulty (i.e. a curriculum). To impose structure on the training set and to define the notion of an easy example, we explored multiple scoring functions that either use feedback from an external neural network or incorporate feedback from the model itself. Empirical results show that with different curriculums we can balance the training times and the network's performance.
Lahjoita puhetta -- a large-scale corpus of spoken Finnish with some benchmarks
Mar 24, 2022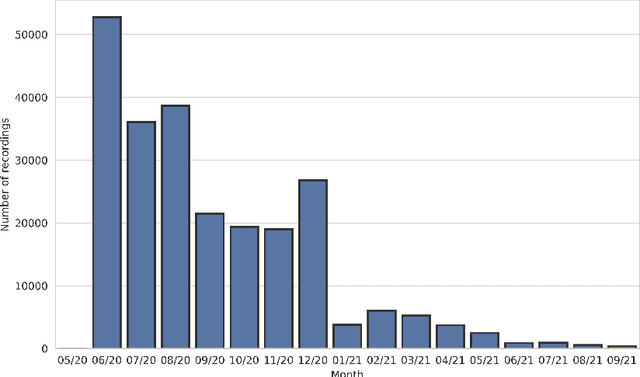
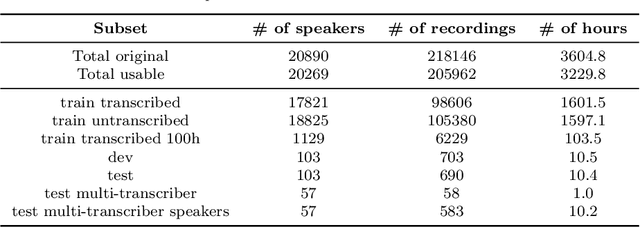
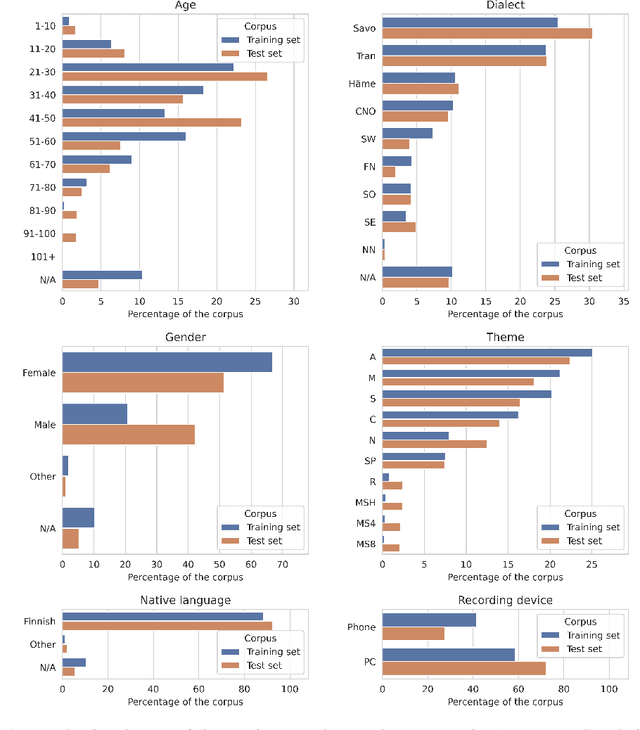
The Donate Speech campaign has so far succeeded in gathering approximately 3600 hours of ordinary, colloquial Finnish speech into the Lahjoita puhetta (Donate Speech) corpus. The corpus includes over twenty thousand speakers from all the regions of Finland and from all age brackets. The primary goals of the collection were to create a representative, large-scale resource to study spontaneous spoken Finnish and to accelerate the development of language technology and speech-based services. In this paper, we present the collection process and the collected corpus, and showcase its versatility through multiple use cases. The evaluated use cases include: automatic speech recognition of spontaneous speech, detection of age, gender, dialect and topic and metadata analysis. We provide benchmarks for the use cases, as well down loadable, trained baseline systems with open-source code for reproducibility. One further use case is to verify the metadata and transcripts given in this corpus itself, and to suggest artificial metadata and transcripts for the part of the corpus where it is missing.
Data augmentation using prosody and false starts to recognize non-native children's speech
Aug 29, 2020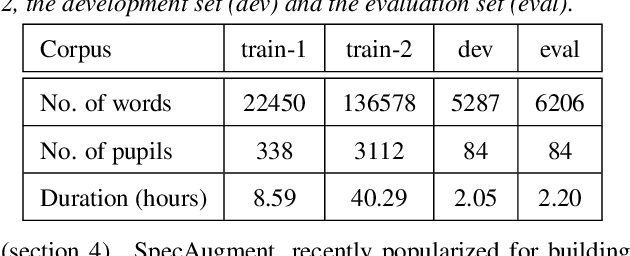
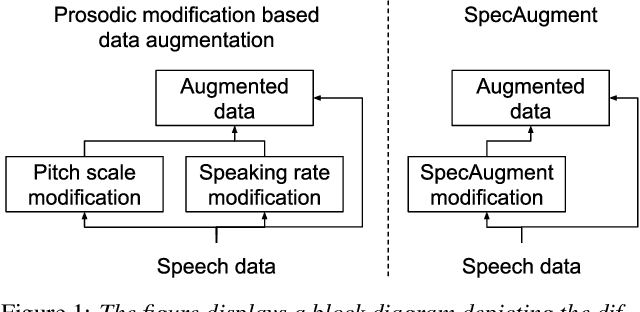
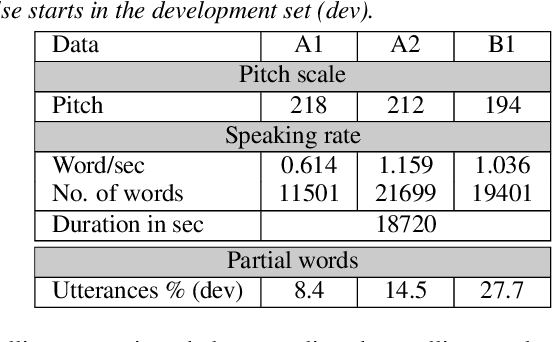
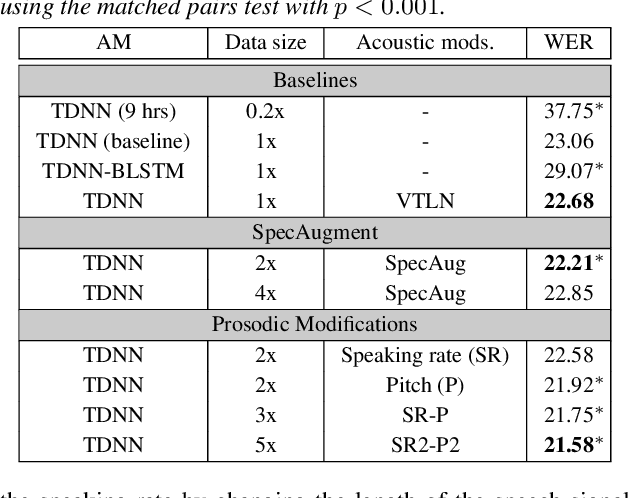
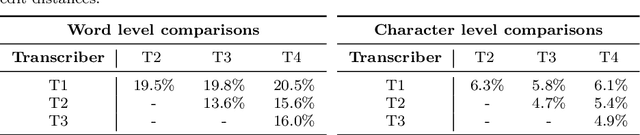
This paper describes AaltoASR's speech recognition system for the INTERSPEECH 2020 shared task on Automatic Speech Recognition (ASR) for non-native children's speech. The task is to recognize non-native speech from children of various age groups given a limited amount of speech. Moreover, the speech being spontaneous has false starts transcribed as partial words, which in the test transcriptions leads to unseen partial words. To cope with these two challenges, we investigate a data augmentation-based approach. Firstly, we apply the prosody-based data augmentation to supplement the audio data. Secondly, we simulate false starts by introducing partial-word noise in the language modeling corpora creating new words. Acoustic models trained on prosody-based augmented data outperform the models using the baseline recipe or the SpecAugment-based augmentation. The partial-word noise also helps to improve the baseline language model. Our ASR system, a combination of these schemes, is placed third in the evaluation period and achieves the word error rate of 18.71%. Post-evaluation period, we observe that increasing the amounts of prosody-based augmented data leads to better performance. Furthermore, removing low-confidence-score words from hypotheses can lead to further gains. These two improvements lower the ASR error rate to 17.99%.
Aalto's End-to-End DNN systems for the INTERSPEECH 2020 Computational Paralinguistics Challenge
Aug 06, 2020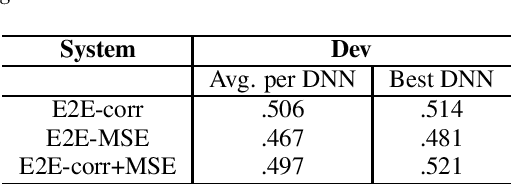
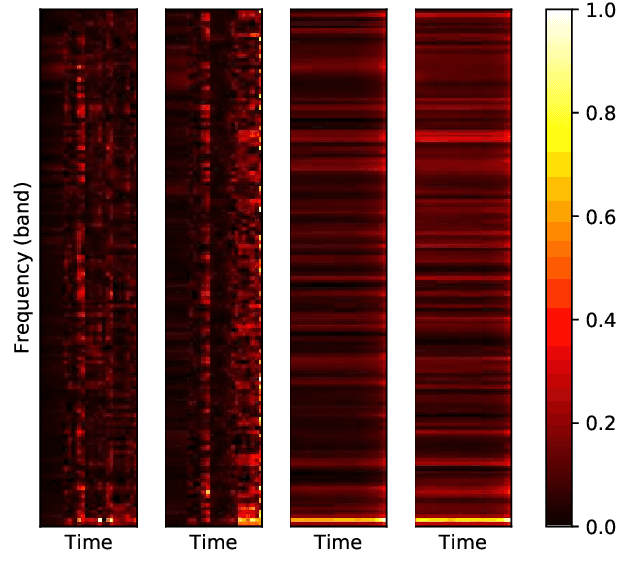
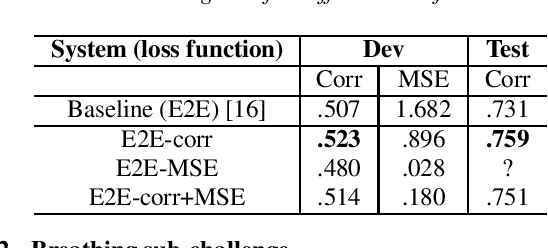
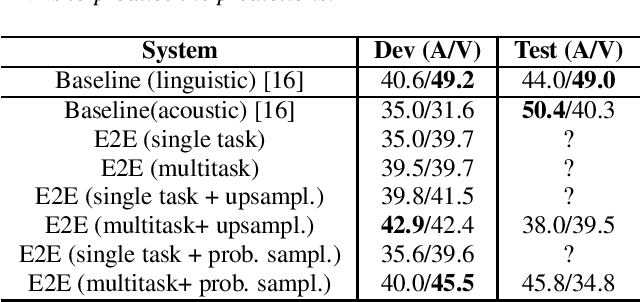
End-to-end neural network models (E2E) have shown significant performance benefits on different INTERSPEECH ComParE tasks. Prior work has applied either a single instance of an E2E model for a task or the same E2E architecture for different tasks. However, applying a single model is unstable or using the same architecture under-utilizes task-specific information. On ComParE 2020 tasks, we investigate applying an ensemble of E2E models for robust performance and developing task-specific modifications for each task. ComParE 2020 introduces three sub-challenges: the breathing sub-challenge to predict the output of a respiratory belt worn by a patient while speaking, the elderly sub-challenge to estimate the elderly speaker's arousal and valence levels and the mask sub-challenge to classify if the speaker is wearing a mask or not. On each of these tasks, an ensemble outperforms the single E2E model. On the breathing sub-challenge, we study the impact of multi-loss strategies on task performance. On the elderly sub-challenge, predicting the valence and arousal levels prompts us to investigate multi-task training and implement data sampling strategies to handle class imbalance. On the mask sub-challenge, using an E2E system without feature engineering is competitive to feature-engineered baselines and provides substantial gains when combined with feature-engineered baselines.