 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Teacher Language-Aware Knowledge Distillation for Multilingual Speech Emotion Recognition
Jun 10, 2025Speech Emotion Recognition (SER) is crucial for improving human-computer interaction. Despite strides in monolingual SER, extending them to build a multilingual system remains challenging. Our goal is to train a single model capable of multilingual SER by distilling knowledge from multiple teacher models. To address this, we introduce a novel language-aware multi-teacher knowledge distillation method to advance SER in English, Finnish, and French. It leverages Wav2Vec2.0 as the foundation of monolingual teacher models and then distills their knowledge into a single multilingual student model. The student model demonstrates state-of-the-art performance, with a weighted recall of 72.9 on the English dataset and an unweighted recall of 63.4 on the Finnish dataset, surpassing fine-tuning and knowledge distillation baselines. Our method excels in improving recall for sad and neutral emotions, although it still faces challenges in recognizing anger and happiness.
Out-of-distribution generalisation in spoken language understanding
Jul 10, 2024


Test data is said to be out-of-distribution (OOD) when it unexpectedly differs from the training data, a common challenge in real-world use cases of machine learning. Although OOD generalisation has gained interest in recent years, few works have focused on OOD generalisation in spoken language understanding (SLU) tasks. To facilitate research on this topic, we introduce a modified version of the popular SLU dataset SLURP, featuring data splits for testing OOD generalisation in the SLU task. We call our modified dataset SLURP For OOD generalisation, or SLURPFOOD. Utilising our OOD data splits, we find end-to-end SLU models to have limited capacity for generalisation. Furthermore, by employing model interpretability techniques, we shed light on the factors contributing to the generalisation difficulties of the models. To improve the generalisation, we experiment with two techniques, which improve the results on some, but not all the splits, emphasising the need for new techniques.
Advancing Audio Emotion and Intent Recognition with Large Pre-Trained Models and Bayesian Inference
Oct 16, 2023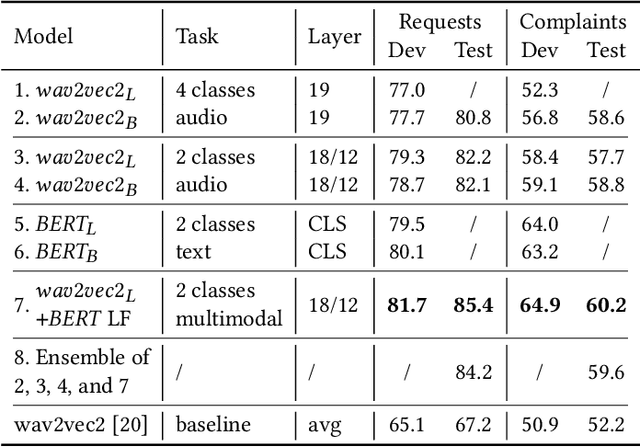

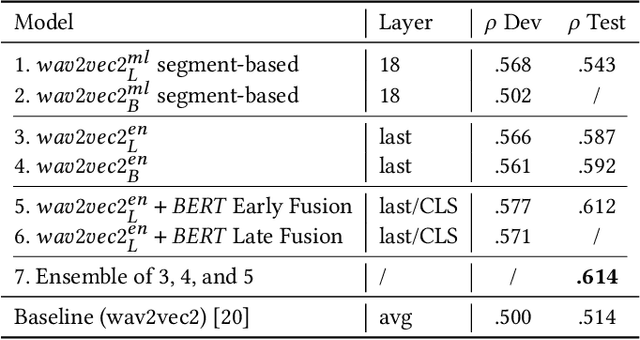
Large pre-trained models are essential in paralinguistic systems, demonstrating effectiveness in tasks like emotion recognition and stuttering detection. In this paper, we employ large pre-trained models for the ACM Multimedia Computational Paralinguistics Challenge, addressing the Requests and Emotion Share tasks. We explore audio-only and hybrid solutions leveraging audio and text modalities. Our empirical results consistently show the superiority of the hybrid approaches over the audio-only models. Moreover, we introduce a Bayesian layer as an alternative to the standard linear output layer. The multimodal fusion approach achieves an 85.4% UAR on HC-Requests and 60.2% on HC-Complaints. The ensemble model for the Emotion Share task yields the best rho value of .614. The Bayesian wav2vec2 approach, explored in this study, allows us to easily build ensembles, at the cost of fine-tuning only one model. Moreover, we can have usable confidence values instead of the usual overconfident posterior probabilities.
Topic Identification For Spontaneous Speech: Enriching Audio Features With Embedded Linguistic Information
Jul 21, 2023Traditional topic identification solutions from audio rely on an automatic speech recognition system (ASR) to produce transcripts used as input to a text-based model. These approaches work well in high-resource scenarios, where there are sufficient data to train both components of the pipeline. However, in low-resource situations, the ASR system, even if available, produces low-quality transcripts, leading to a bad text-based classifier. Moreover, spontaneous speech containing hesitations can further degrade the performance of the ASR model. In this paper, we investigate alternatives to the standard text-only solutions by comparing audio-only and hybrid techniques of jointly utilising text and audio features. The models evaluated on spontaneous Finnish speech demonstrate that purely audio-based solutions are a viable option when ASR components are not available, while the hybrid multi-modal solutions achieve the best results.
Lahjoita puhetta -- a large-scale corpus of spoken Finnish with some benchmarks
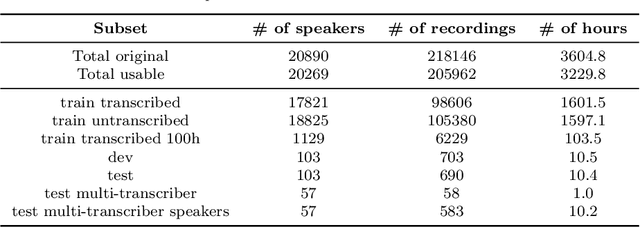
Mar 24, 2022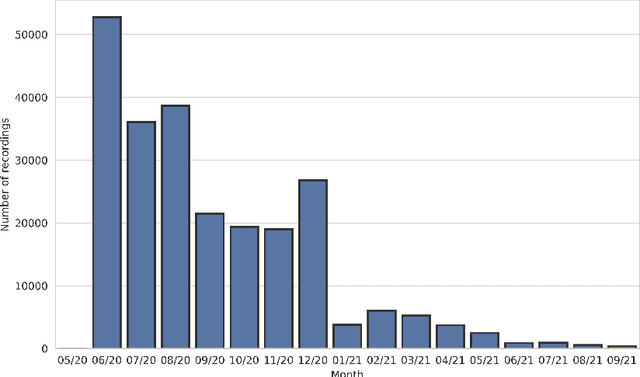
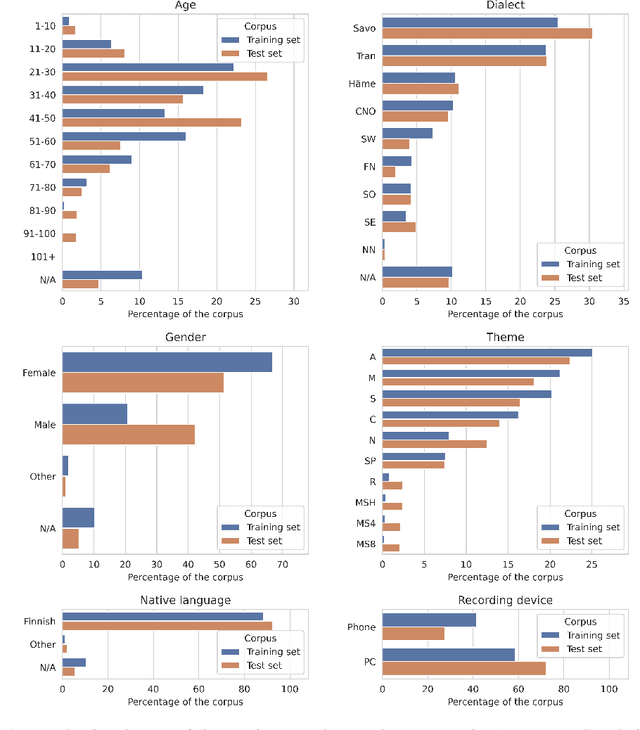
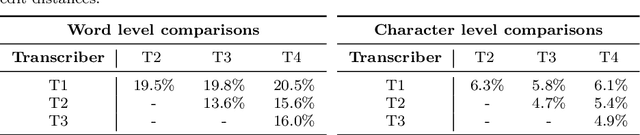
The Donate Speech campaign has so far succeeded in gathering approximately 3600 hours of ordinary, colloquial Finnish speech into the Lahjoita puhetta (Donate Speech) corpus. The corpus includes over twenty thousand speakers from all the regions of Finland and from all age brackets. The primary goals of the collection were to create a representative, large-scale resource to study spontaneous spoken Finnish and to accelerate the development of language technology and speech-based services. In this paper, we present the collection process and the collected corpus, and showcase its versatility through multiple use cases. The evaluated use cases include: automatic speech recognition of spontaneous speech, detection of age, gender, dialect and topic and metadata analysis. We provide benchmarks for the use cases, as well down loadable, trained baseline systems with open-source code for reproducibility. One further use case is to verify the metadata and transcripts given in this corpus itself, and to suggest artificial metadata and transcripts for the part of the corpus where it is missing.