 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMs' morphological analyses of complex FST-generated Finnish words
Jul 11, 2024



Rule-based language processing systems have been overshadowed by neural systems in terms of utility, but it remains unclear whether neural NLP systems, in practice, learn the grammar rules that humans use. This work aims to shed light on the issue by evaluating state-of-the-art LLMs in a task of morphological analysis of complex Finnish noun forms. We generate the forms using an FST tool, and they are unlikely to have occurred in the training sets of the LLMs, therefore requiring morphological generalisation capacity. We find that GPT-4-turbo has some difficulties in the task while GPT-3.5-turbo struggles and smaller models Llama2-70B and Poro-34B fail nearly completely.
Out-of-distribution generalisation in spoken language understanding
Jul 10, 2024


Test data is said to be out-of-distribution (OOD) when it unexpectedly differs from the training data, a common challenge in real-world use cases of machine learning. Although OOD generalisation has gained interest in recent years, few works have focused on OOD generalisation in spoken language understanding (SLU) tasks. To facilitate research on this topic, we introduce a modified version of the popular SLU dataset SLURP, featuring data splits for testing OOD generalisation in the SLU task. We call our modified dataset SLURP For OOD generalisation, or SLURPFOOD. Utilising our OOD data splits, we find end-to-end SLU models to have limited capacity for generalisation. Furthermore, by employing model interpretability techniques, we shed light on the factors contributing to the generalisation difficulties of the models. To improve the generalisation, we experiment with two techniques, which improve the results on some, but not all the splits, emphasising the need for new techniques.
On Using Distribution-Based Compositionality Assessment to Evaluate Compositional Generalisation in Machine Translation
Nov 14, 2023

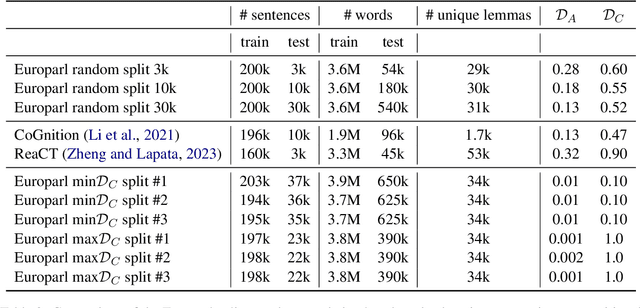

Compositional generalisation (CG), in NLP and in machine learning more generally, has been assessed mostly using artificial datasets. It is important to develop benchmarks to assess CG also in real-world natural language tasks in order to understand the abilities and limitations of systems deployed in the wild. To this end, our GenBench Collaborative Benchmarking Task submission utilises the distribution-based compositionality assessment (DBCA) framework to split the Europarl translation corpus into a training and a test set in such a way that the test set requires compositional generalisation capacity. Specifically, the training and test sets have divergent distributions of dependency relations, testing NMT systems' capability of translating dependencies that they have not been trained on. This is a fully-automated procedure to create natural language compositionality benchmarks, making it simple and inexpensive to apply it further to other datasets and languages. The code and data for the experiments is available at https://github.com/aalto-speech/dbca.
Lahjoita puhetta -- a large-scale corpus of spoken Finnish with some benchmarks
Mar 24, 2022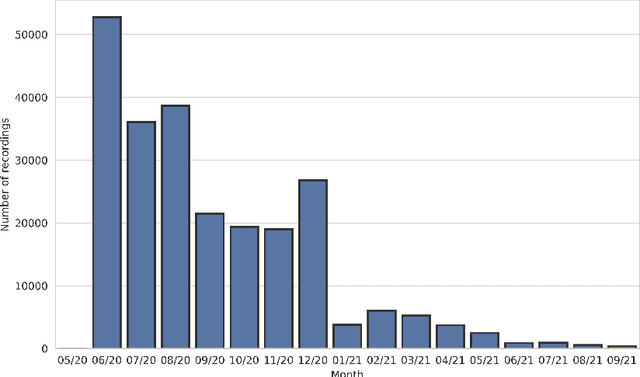
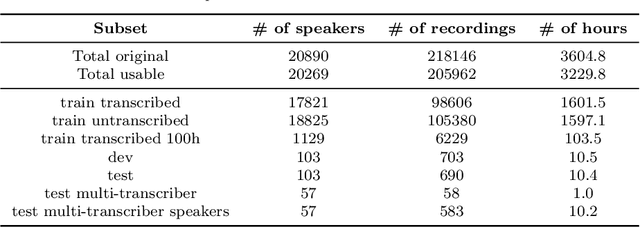
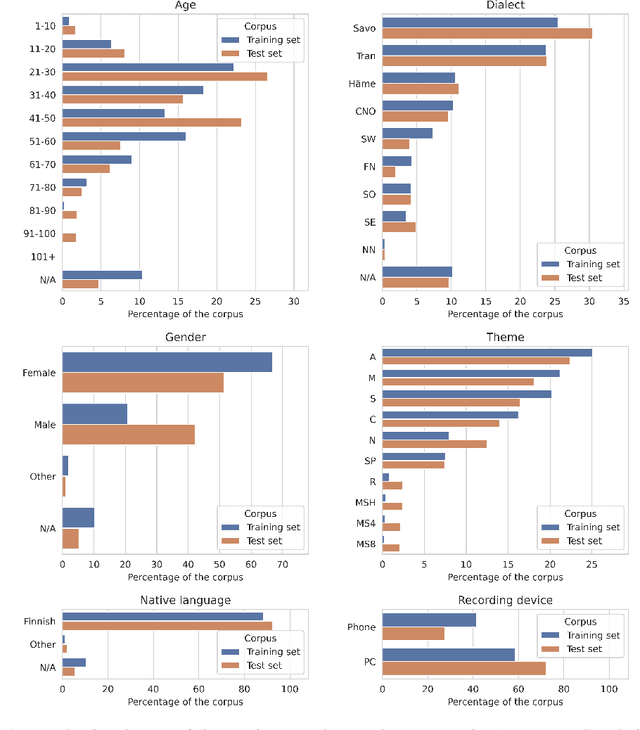
The Donate Speech campaign has so far succeeded in gathering approximately 3600 hours of ordinary, colloquial Finnish speech into the Lahjoita puhetta (Donate Speech) corpus. The corpus includes over twenty thousand speakers from all the regions of Finland and from all age brackets. The primary goals of the collection were to create a representative, large-scale resource to study spontaneous spoken Finnish and to accelerate the development of language technology and speech-based services. In this paper, we present the collection process and the collected corpus, and showcase its versatility through multiple use cases. The evaluated use cases include: automatic speech recognition of spontaneous speech, detection of age, gender, dialect and topic and metadata analysis. We provide benchmarks for the use cases, as well down loadable, trained baseline systems with open-source code for reproducibility. One further use case is to verify the metadata and transcripts given in this corpus itself, and to suggest artificial metadata and transcripts for the part of the corpus where it is missing.