 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-Source Conversational AI with SpeechBrain 1.0
Jul 02, 2024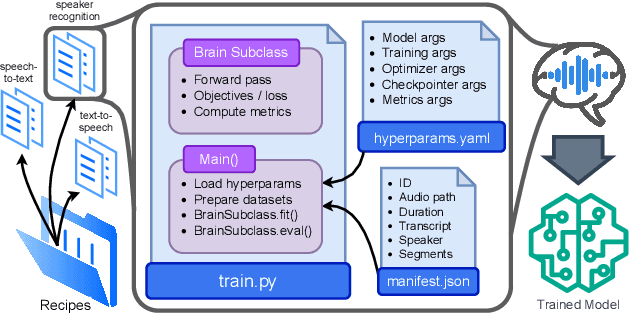

SpeechBrain is an open-source Conversational AI toolkit based on PyTorch, focused particularly on speech processing tasks such as speech recognition, speech enhancement, speaker recognition, text-to-speech, and much more. It promotes transparency and replicability by releasing both the pre-trained models and the complete "recipes" of code and algorithms required for training them. This paper presents SpeechBrain 1.0, a significant milestone in the evolution of the toolkit, which now has over 200 recipes for speech, audio, and language processing tasks, and more than 100 models available on Hugging Face. SpeechBrain 1.0 introduces new technologies to support diverse learning modalities, Large Language Model (LLM) integration, and advanced decoding strategies, along with novel models, tasks, and modalities. It also includes a new benchmark repository, offering researchers a unified platform for evaluating models across diverse tasks
Finnish Parliament ASR corpus - Analysis, benchmarks and statistics
Mar 28, 2022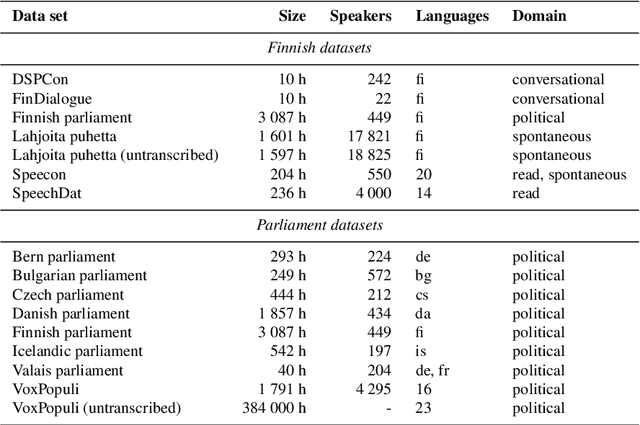
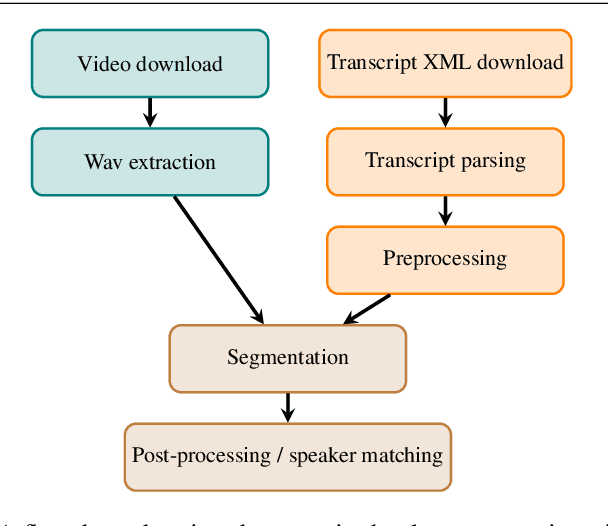
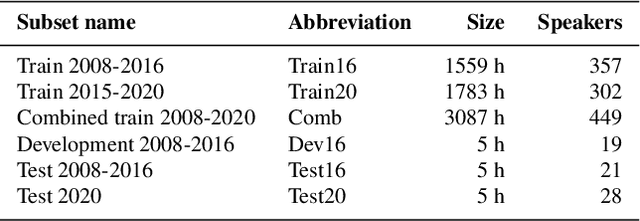
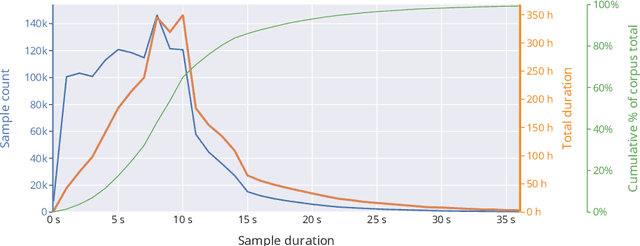
Public sources like parliament meeting recordings and transcripts provide ever-growing material for the training and evaluation of automatic speech recognition (ASR) systems. In this paper, we publish and analyse the Finnish parliament ASR corpus, the largest publicly available collection of manually transcribed speech data for Finnish with over 3000 hours of speech and 449 speakers for which it provides rich demographic metadata. This corpus builds on earlier initial work, and as a result the corpus has a natural split into two training subsets from two periods of time. Similarly, there are two official, corrected test sets covering different times, setting an ASR task with longitudinal distribution-shift characteristics. An official development set is also provided. We develop a complete Kaldi-based data preparation pipeline, and hidden Markov model (HMM), hybrid deep neural network (HMM-DNN) and attention-based encoder-decoder (AED) ASR recipes. We set benchmarks on the official test sets, as well as multiple other recently used test sets. Both temporal corpus subsets are already large, and we observe that beyond their scale, ASR performance on the official test sets plateaus, whereas other domains benefit from added data. The HMM-DNN and AED approaches are compared in a carefully matched equal data setting, with the HMM-DNN system consistently performing better. Finally, the variation of the ASR accuracy is compared between the speaker categories available in the parliament metadata to detect potential biases based on factors such as gender, age, and education.
Lahjoita puhetta -- a large-scale corpus of spoken Finnish with some benchmarks
Mar 24, 2022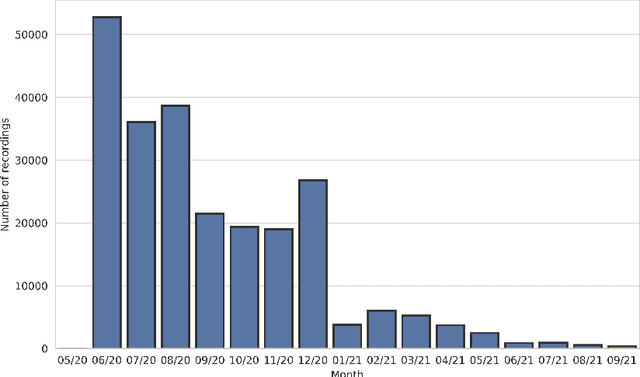
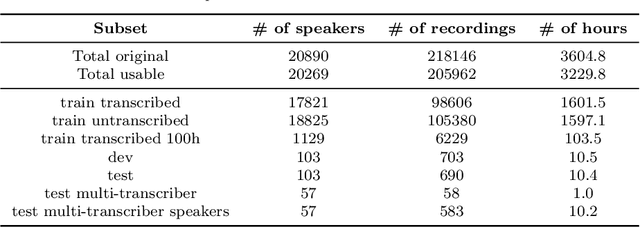
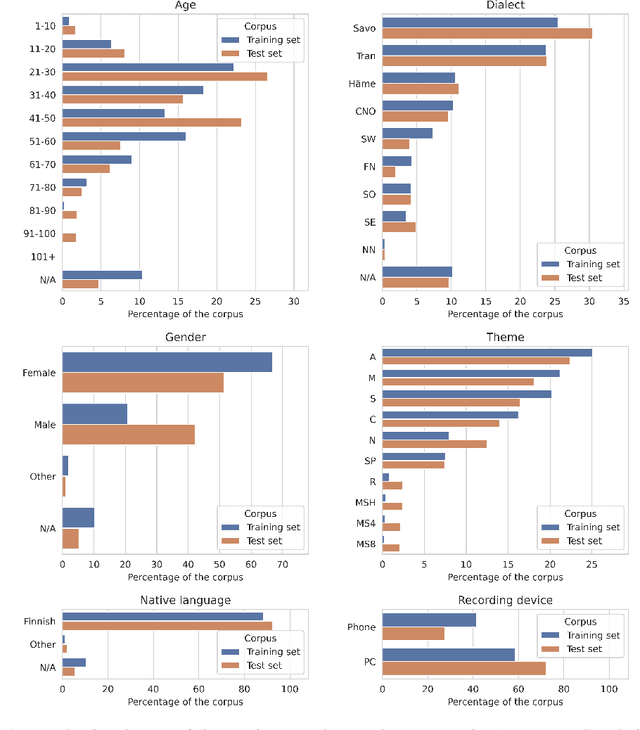
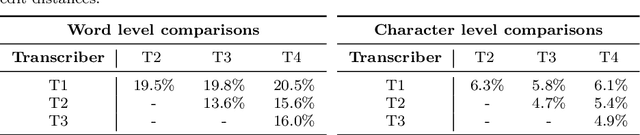
The Donate Speech campaign has so far succeeded in gathering approximately 3600 hours of ordinary, colloquial Finnish speech into the Lahjoita puhetta (Donate Speech) corpus. The corpus includes over twenty thousand speakers from all the regions of Finland and from all age brackets. The primary goals of the collection were to create a representative, large-scale resource to study spontaneous spoken Finnish and to accelerate the development of language technology and speech-based services. In this paper, we present the collection process and the collected corpus, and showcase its versatility through multiple use cases. The evaluated use cases include: automatic speech recognition of spontaneous speech, detection of age, gender, dialect and topic and metadata analysis. We provide benchmarks for the use cases, as well down loadable, trained baseline systems with open-source code for reproducibility. One further use case is to verify the metadata and transcripts given in this corpus itself, and to suggest artificial metadata and transcripts for the part of the corpus where it is missing.
SpeechBrain: A General-Purpose Speech Toolkit
Jun 08, 2021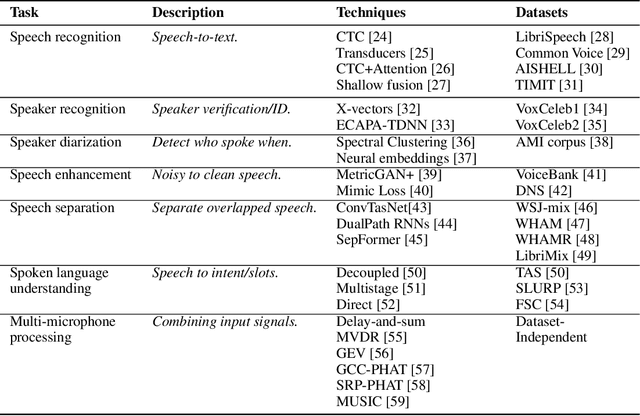
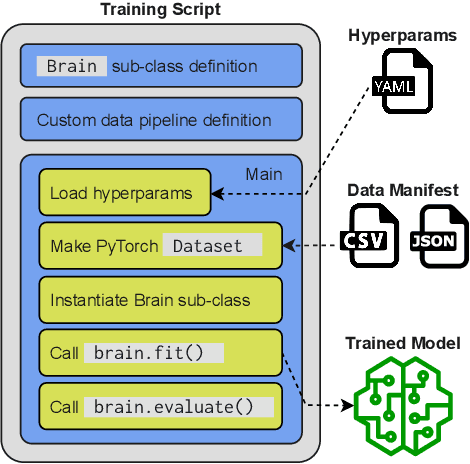

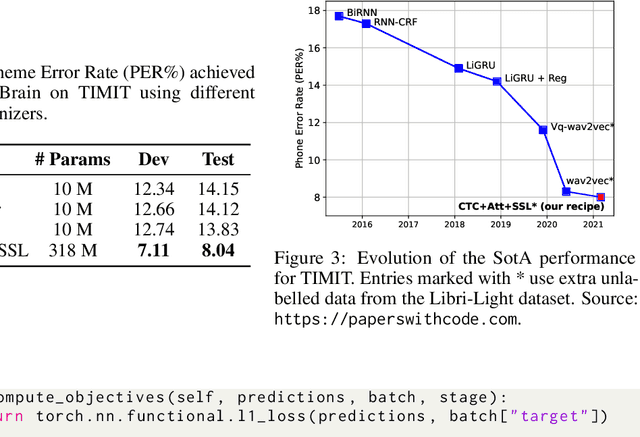
SpeechBrain is an open-source and all-in-one speech toolkit. It is designed to facilitate the research and development of neural speech processing technologies by being simple, flexible, user-friendly, and well-documented. This paper describes the core architecture designed to support several tasks of common interest, allowing users to naturally conceive, compare and share novel speech processing pipelines. SpeechBrain achieves competitive or state-of-the-art performance in a wide range of speech benchmarks. It also provides training recipes, pretrained models, and inference scripts for popular speech datasets, as well as tutorials which allow anyone with basic Python proficiency to familiarize themselves with speech technologies.
Multimodal Machine Translation through Visuals and Speech
Nov 28, 2019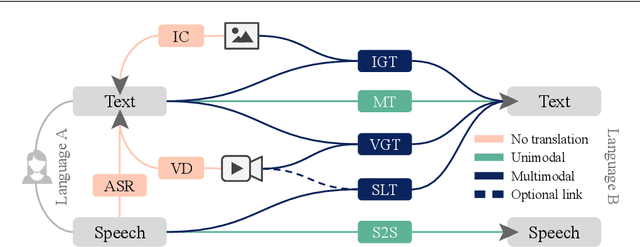
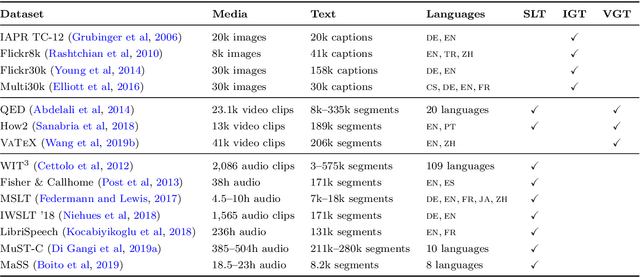

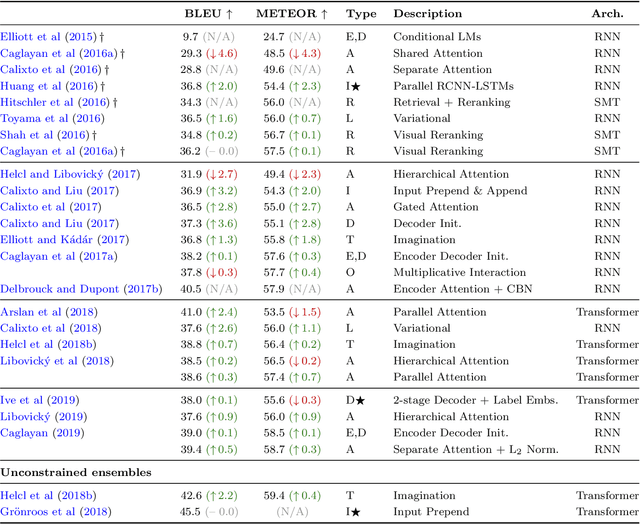
Multimodal machine translation involves drawing information from more than one modality, based on the assumption that the additional modalities will contain useful alternative views of the input data. The most prominent tasks in this area are spoken language translation, image-guided translation, and video-guided translation, which exploit audio and visual modalities, respectively. These tasks are distinguished from their monolingual counterparts of speech recognition, image captioning, and video captioning by the requirement of models to generate outputs in a different language. This survey reviews the major data resources for these tasks, the evaluation campaigns concentrated around them, the state of the art in end-to-end and pipeline approaches, and also the challenges in performance evaluation. The paper concludes with a discussion of directions for future research in these areas: the need for more expansive and challenging datasets, for targeted evaluations of model performance, and for multimodality in both the input and output space.
The MeMAD Submission to the IWSLT 2018 Speech Translation Task
Oct 24, 2018

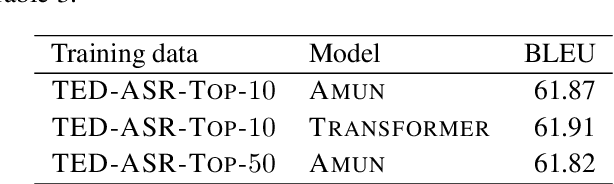

This paper describes the MeMAD project entry to the IWSLT Speech Translation Shared Task, addressing the translation of English audio into German text. Between the pipeline and end-to-end model tracks, we participated only in the former, with three contrastive systems. We tried also the latter, but were not able to finish our end-to-end model in time. All of our systems start by transcribing the audio into text through an automatic speech recognition (ASR) model trained on the TED-LIUM English Speech Recognition Corpus (TED-LIUM). Afterwards, we feed the transcripts into English-German text-based neural machine translation (NMT) models. Our systems employ three different translation models trained on separate training sets compiled from the English-German part of the TED Speech Translation Corpus (TED-Trans) and the OpenSubtitles2018 section of the OPUS collection. In this paper, we also describe the experiments leading up to our final systems. Our experiments indicate that using OpenSubtitles2018 in training significantly improves translation performance. We also experimented with various pre- and postprocessing routines for the NMT module, but we did not have much success with these. Our best-scoring system attains a BLEU score of 16.45 on the test set for this year's task.