 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised Visual Attention for Simultaneous Multimodal Machine Translation
Jan 23, 2022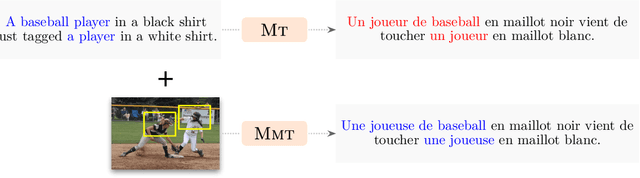
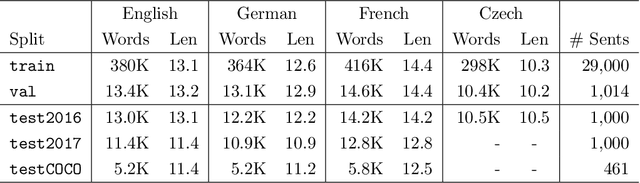
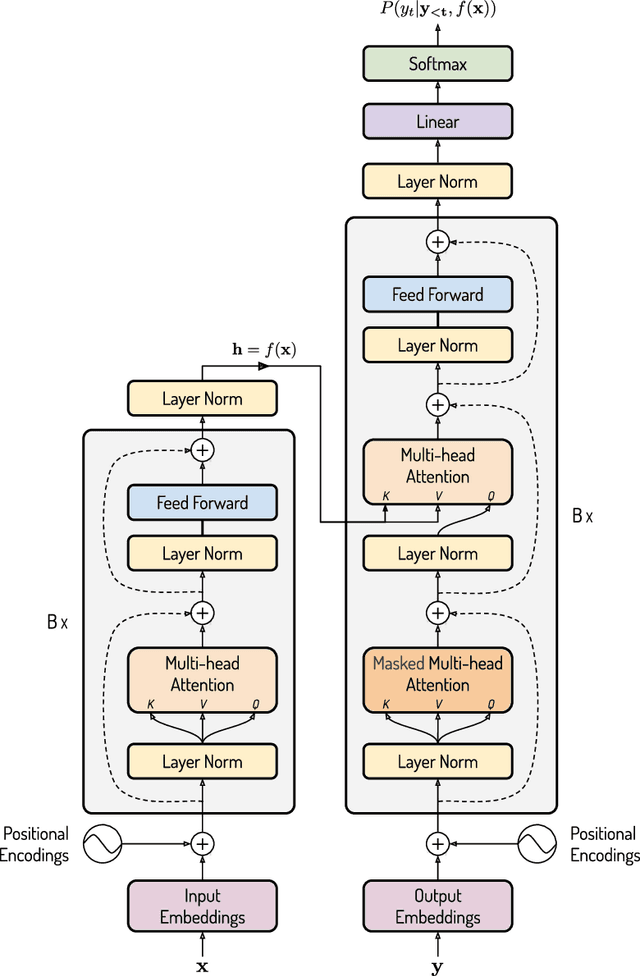
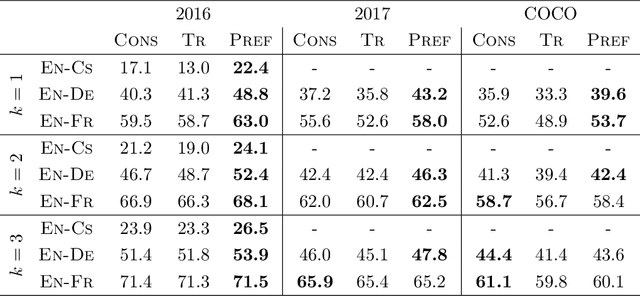
Recently, there has been a surge in research in multimodal machine translation (MMT), where additional modalities such as images are used to improve translation quality of textual systems. A particular use for such multimodal systems is the task of simultaneous machine translation, where visual context has been shown to complement the partial information provided by the source sentence, especially in the early phases of translation (Caglayanet al., 2020a; Imankulova et al., 2020). In this paper, we propose the first Transformer-based simultaneous MMT architecture, which has not been previously explored in the field. Additionally, we extend this model with an auxiliary supervision signal that guides its visual attention mechanism using labelled phrase-region alignments. We perform comprehensive experiments on three language directions and conduct thorough quantitative and qualitative analyses using both automatic metrics and manual inspection. Our results show that (i) supervised visual attention consistently improves the translation quality of the MMT models, and (ii) fine-tuning the MMT with supervision loss enabled leads to better performance than training the MMT from scratch. Compared to the state-of-the-art, our proposed model achieves improvements of up to 2.3 BLEU and 3.5 METEOR points.
BERTGEN: Multi-task Generation through BERT
Jun 07, 2021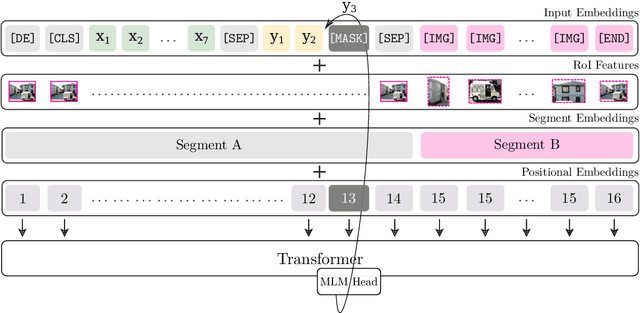

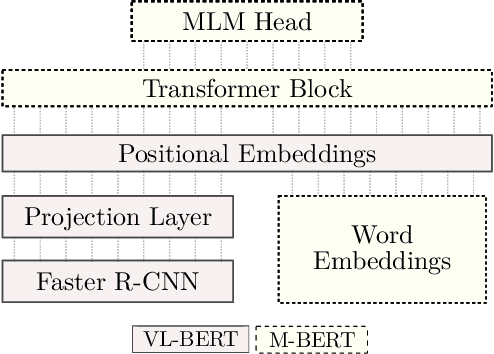

We present BERTGEN, a novel generative, decoder-only model which extends BERT by fusing multimodal and multilingual pretrained models VL-BERT and M-BERT, respectively. BERTGEN is auto-regressively trained for language generation tasks, namely image captioning, machine translation and multimodal machine translation, under a multitask setting. With a comprehensive set of evaluations, we show that BERTGEN outperforms many strong baselines across the tasks explored. We also show BERTGEN's ability for zero-shot language generation, where it exhibits competitive performance to supervised counterparts. Finally, we conduct ablation studies which demonstrate that BERTGEN substantially benefits from multi-tasking and effectively transfers relevant inductive biases from the pre-trained models.
Exploiting Multimodal Reinforcement Learning for Simultaneous Machine Translation
Feb 22, 2021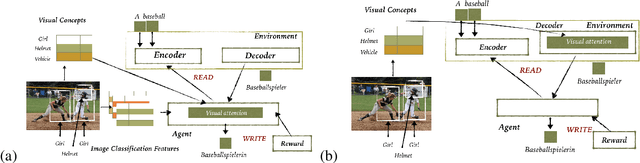
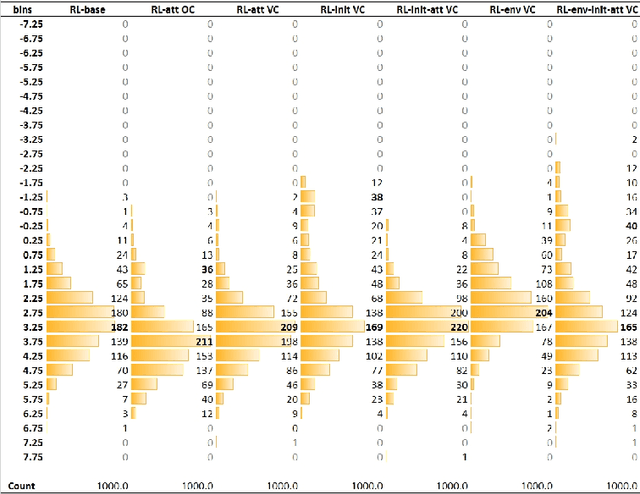

This paper addresses the problem of simultaneous machine translation (SiMT) by exploring two main concepts: (a) adaptive policies to learn a good trade-off between high translation quality and low latency; and (b) visual information to support this process by providing additional (visual) contextual information which may be available before the textual input is produced. For that, we propose a multimodal approach to simultaneous machine translation using reinforcement learning, with strategies to integrate visual and textual information in both the agent and the environment. We provide an exploration on how different types of visual information and integration strategies affect the quality and latency of simultaneous translation models, and demonstrate that visual cues lead to higher quality while keeping the latency low.
Cross-lingual Visual Pre-training for Multimodal Machine Translation
Jan 25, 2021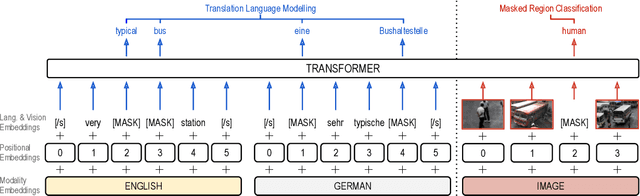
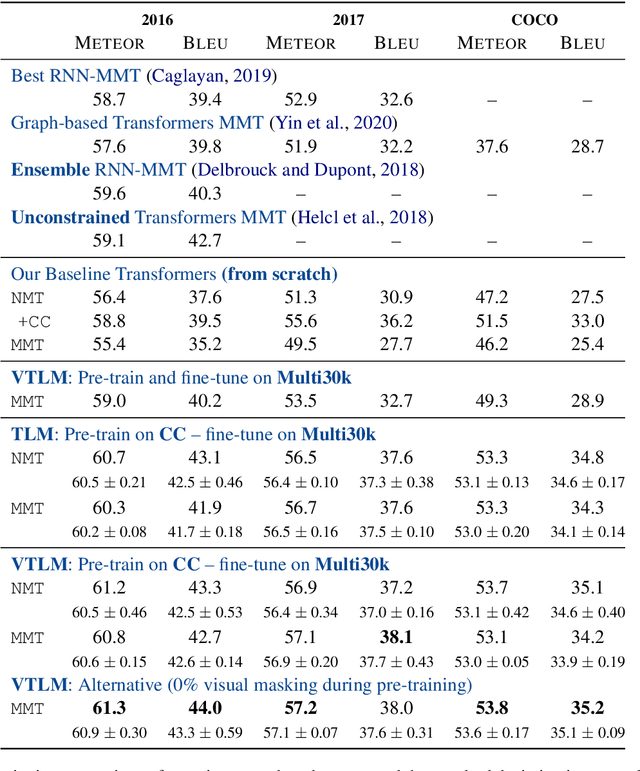
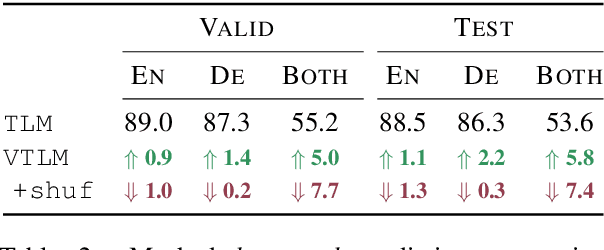
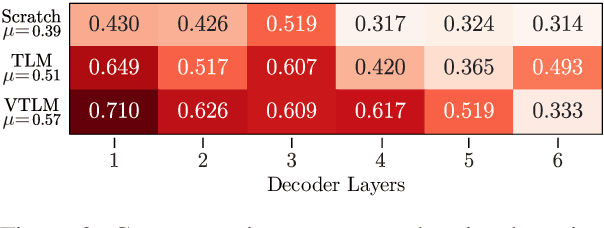
Pre-trained language models have been shown to improve performance in many natural language tasks substantially. Although the early focus of such models was single language pre-training, recent advances have resulted in cross-lingual and visual pre-training methods. In this paper, we combine these two approaches to learn visually-grounded cross-lingual representations. Specifically, we extend the translation language modelling (Lample and Conneau, 2019) with masked region classification and perform pre-training with three-way parallel vision & language corpora. We show that when fine-tuned for multimodal machine translation, these models obtain state-of-the-art performance. We also provide qualitative insights into the usefulness of the learned grounded representations.
MSVD-Turkish: A Comprehensive Multimodal Dataset for Integrated Vision and Language Research in Turkish
Dec 13, 2020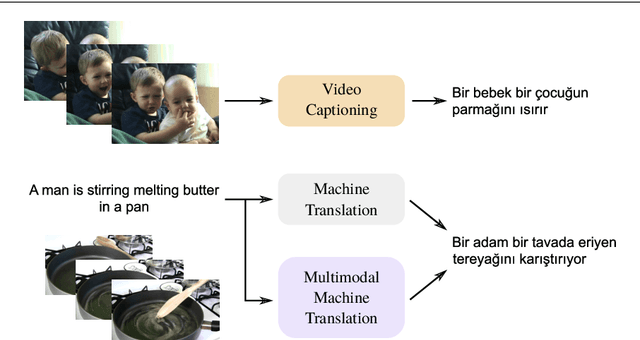
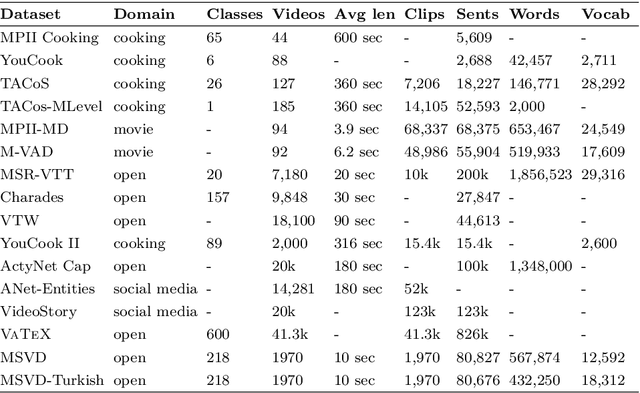
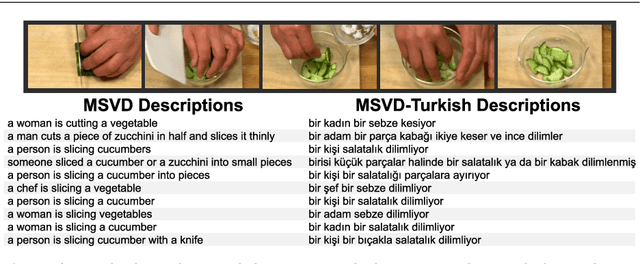

Automatic generation of video descriptions in natural language, also called video captioning, aims to understand the visual content of the video and produce a natural language sentence depicting the objects and actions in the scene. This challenging integrated vision and language problem, however, has been predominantly addressed for English. The lack of data and the linguistic properties of other languages limit the success of existing approaches for such languages. In this paper we target Turkish, a morphologically rich and agglutinative language that has very different properties compared to English. To do so, we create the first large scale video captioning dataset for this language by carefully translating the English descriptions of the videos in the MSVD (Microsoft Research Video Description Corpus) dataset into Turkish. In addition to enabling research in video captioning in Turkish, the parallel English-Turkish descriptions also enables the study of the role of video context in (multimodal) machine translation. In our experiments, we build models for both video captioning and multimodal machine translation and investigate the effect of different word segmentation approaches and different neural architectures to better address the properties of Turkish. We hope that the MSVD-Turkish dataset and the results reported in this work will lead to better video captioning and multimodal machine translation models for Turkish and other morphology rich and agglutinative languages.
Curious Case of Language Generation Evaluation Metrics: A Cautionary Tale
Oct 26, 2020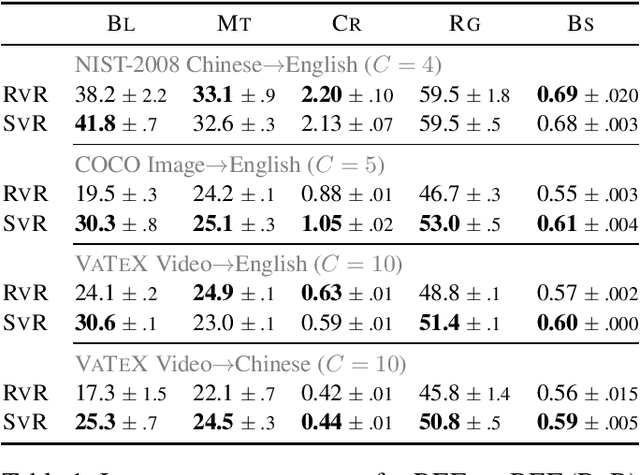

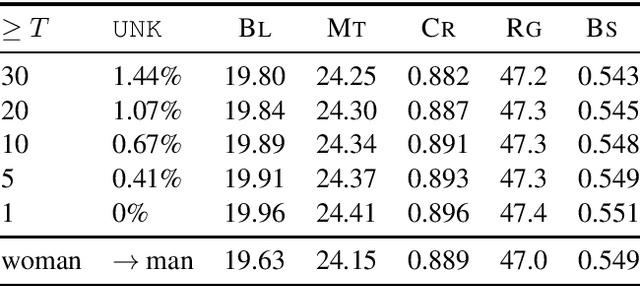
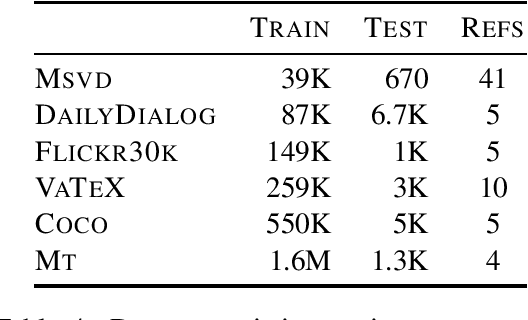
Automatic evaluation of language generation systems is a well-studied problem in Natural Language Processing. While novel metrics are proposed every year, a few popular metrics remain as the de facto metrics to evaluate tasks such as image captioning and machine translation, despite their known limitations. This is partly due to ease of use, and partly because researchers expect to see them and know how to interpret them. In this paper, we urge the community for more careful consideration of how they automatically evaluate their models by demonstrating important failure cases on multiple datasets, language pairs and tasks. Our experiments show that metrics (i) usually prefer system outputs to human-authored texts, (ii) can be insensitive to correct translations of rare words, (iii) can yield surprisingly high scores when given a single sentence as system output for the entire test set.
Simultaneous Machine Translation with Visual Context
Oct 13, 2020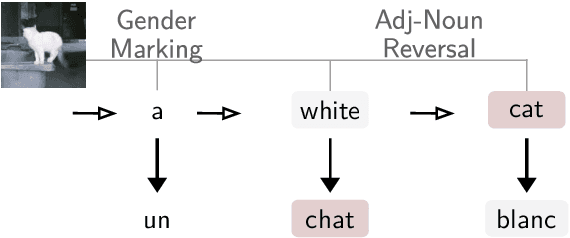
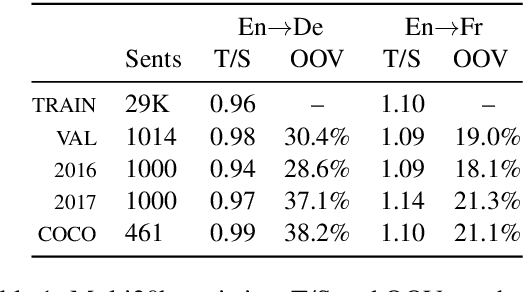
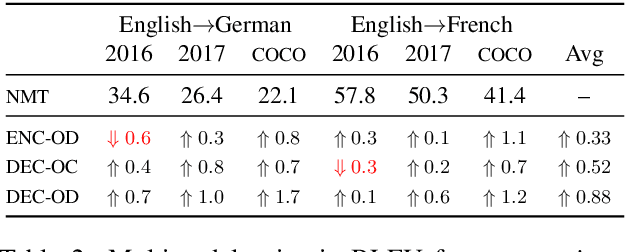
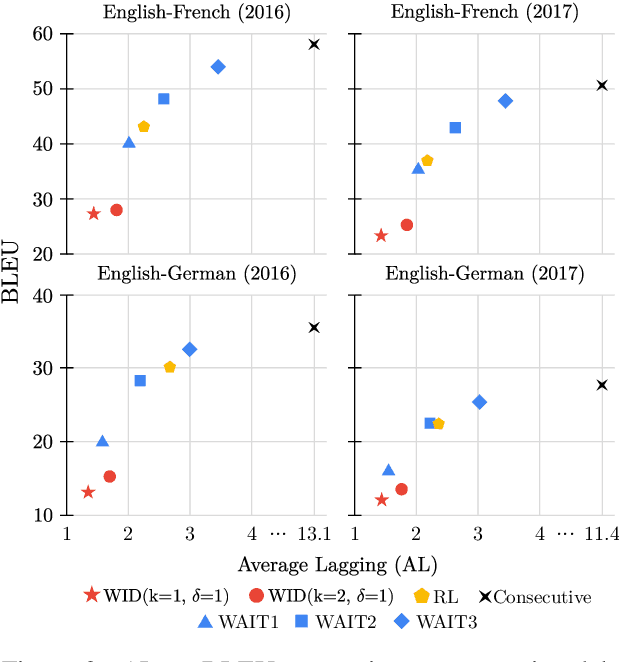
Simultaneous machine translation (SiMT) aims to translate a continuous input text stream into another language with the lowest latency and highest quality possible. The translation thus has to start with an incomplete source text, which is read progressively, creating the need for anticipation. In this paper, we seek to understand whether the addition of visual information can compensate for the missing source context. To this end, we analyse the impact of different multimodal approaches and visual features on state-of-the-art SiMT frameworks. Our results show that visual context is helpful and that visually-grounded models based on explicit object region information are much better than commonly used global features, reaching up to 3 BLEU points improvement under low latency scenarios. Our qualitative analysis illustrates cases where only the multimodal systems are able to translate correctly from English into gender-marked languages, as well as deal with differences in word order, such as adjective-noun placement between English and French.
Multimodal Machine Translation through Visuals and Speech
Nov 28, 2019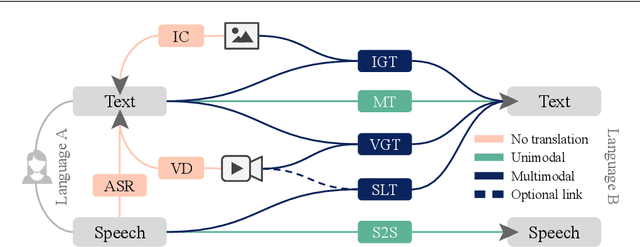
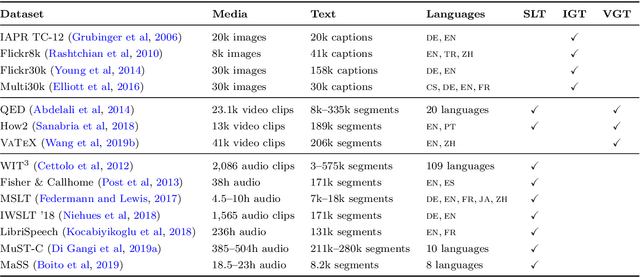

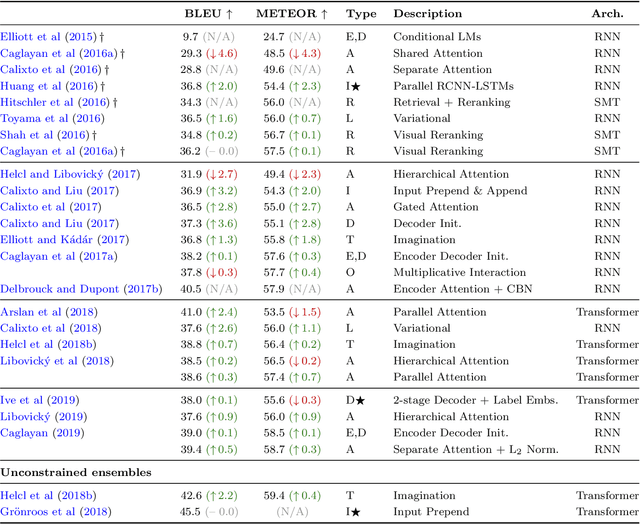
Multimodal machine translation involves drawing information from more than one modality, based on the assumption that the additional modalities will contain useful alternative views of the input data. The most prominent tasks in this area are spoken language translation, image-guided translation, and video-guided translation, which exploit audio and visual modalities, respectively. These tasks are distinguished from their monolingual counterparts of speech recognition, image captioning, and video captioning by the requirement of models to generate outputs in a different language. This survey reviews the major data resources for these tasks, the evaluation campaigns concentrated around them, the state of the art in end-to-end and pipeline approaches, and also the challenges in performance evaluation. The paper concludes with a discussion of directions for future research in these areas: the need for more expansive and challenging datasets, for targeted evaluations of model performance, and for multimodality in both the input and output space.
Transformer-based Cascaded Multimodal Speech Translation
Nov 08, 2019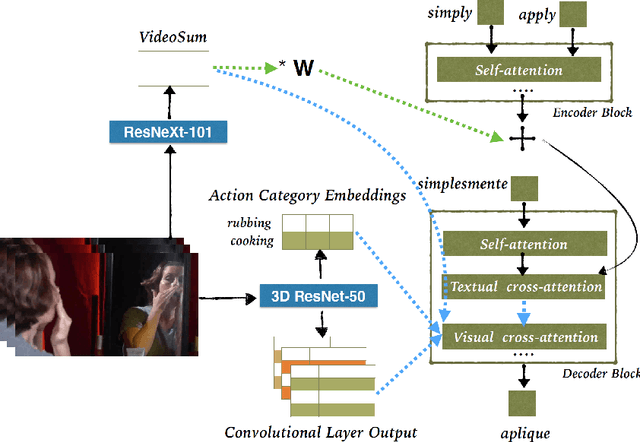
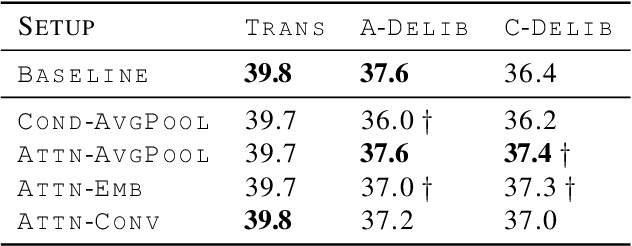
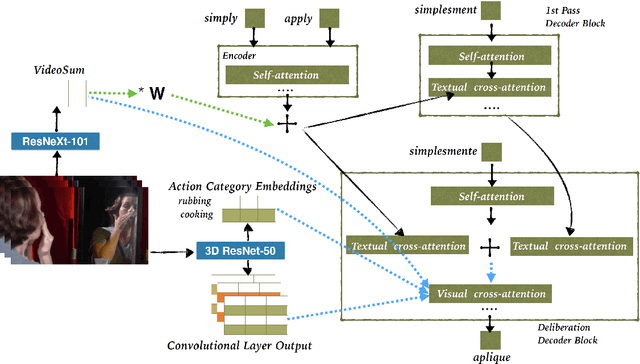
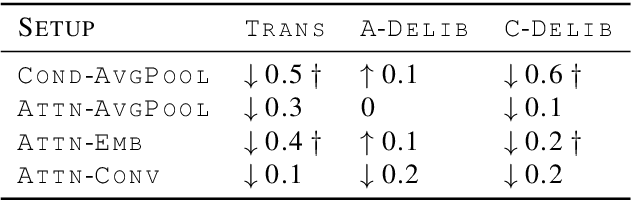
This paper describes the cascaded multimodal speech translation systems developed by Imperial College London for the IWSLT 2019 evaluation campaign. The architecture consists of an automatic speech recognition (ASR) system followed by a Transformer-based multimodal machine translation (MMT) system. While the ASR component is identical across the experiments, the MMT model varies in terms of the way of integrating the visual context (simple conditioning vs. attention), the type of visual features exploited (pooled, convolutional, action categories) and the underlying architecture. For the latter, we explore both the canonical transformer and its deliberation version with additive and cascade variants which differ in how they integrate the textual attention. Upon conducting extensive experiments, we found that (i) the explored visual integration schemes often harm the translation performance for the transformer and additive deliberation, but considerably improve the cascade deliberation; (ii) the transformer and cascade deliberation integrate the visual modality better than the additive deliberation, as shown by the incongruence analysis.
Imperial College London Submission to VATEX Video Captioning Task
Oct 16, 2019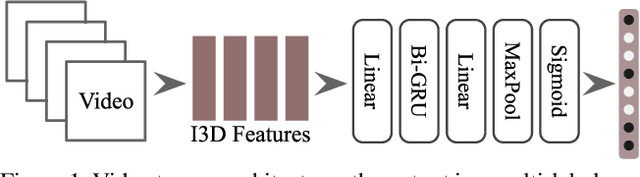
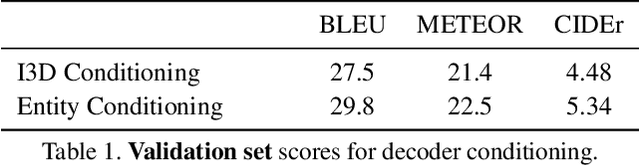
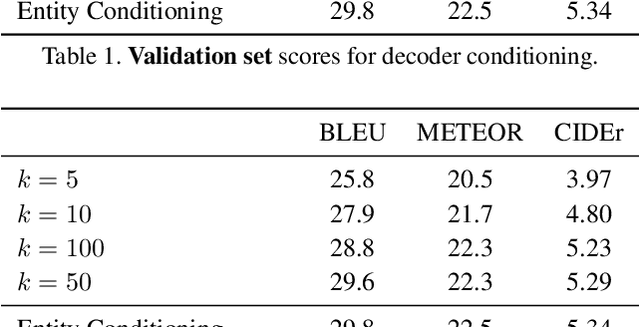

This paper describes the Imperial College London team's submission to the 2019' VATEX video captioning challenge, where we first explore two sequence-to-sequence models, namely a recurrent (GRU) model and a transformer model, which generate captions from the I3D action features. We then investigate the effect of dropping the encoder and the attention mechanism and instead conditioning the GRU decoder over two different vectorial representations: (i) a max-pooled action feature vector and (ii) the output of a multi-label classifier trained to predict visual entities from the action features. Our baselines achieved scores comparable to the official baseline. Conditioning over entity predictions performed substantially better than conditioning on the max-pooled feature vector, and only marginally worse than the GRU-based sequence-to-sequence baseline.