 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-lingual Visual Pre-training for Multimodal Machine Translation
Jan 25, 2021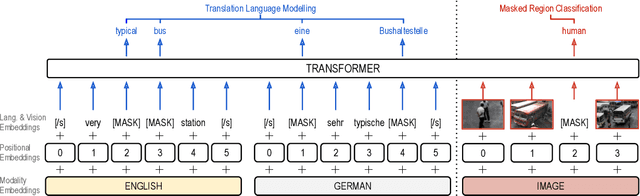
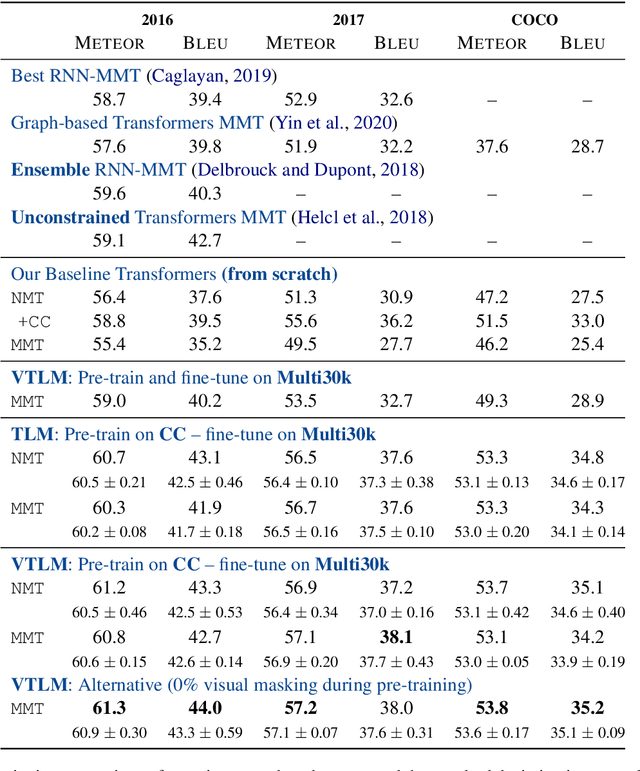
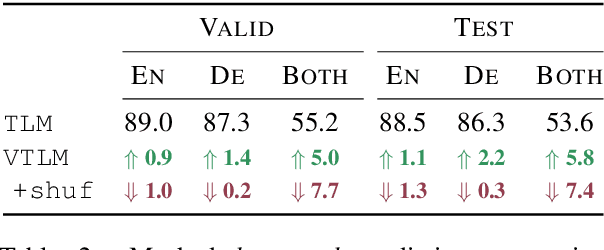
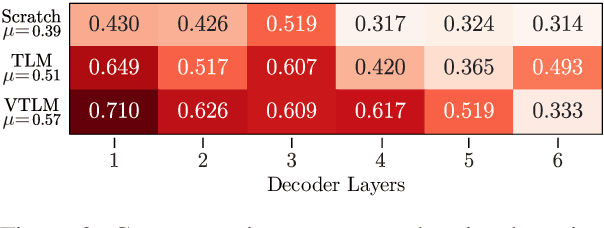
Pre-trained language models have been shown to improve performance in many natural language tasks substantially. Although the early focus of such models was single language pre-training, recent advances have resulted in cross-lingual and visual pre-training methods. In this paper, we combine these two approaches to learn visually-grounded cross-lingual representations. Specifically, we extend the translation language modelling (Lample and Conneau, 2019) with masked region classification and perform pre-training with three-way parallel vision & language corpora. We show that when fine-tuned for multimodal machine translation, these models obtain state-of-the-art performance. We also provide qualitative insights into the usefulness of the learned grounded representations.
MSVD-Turkish: A Comprehensive Multimodal Dataset for Integrated Vision and Language Research in Turkish
Dec 13, 2020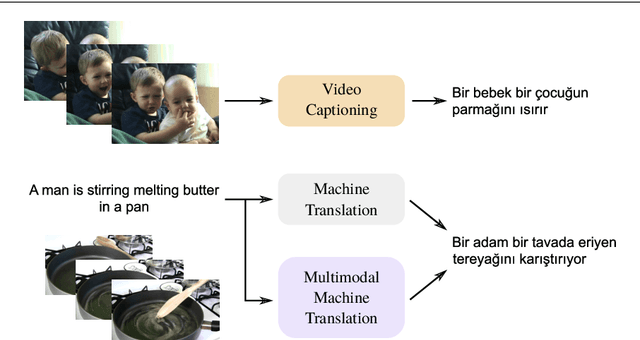
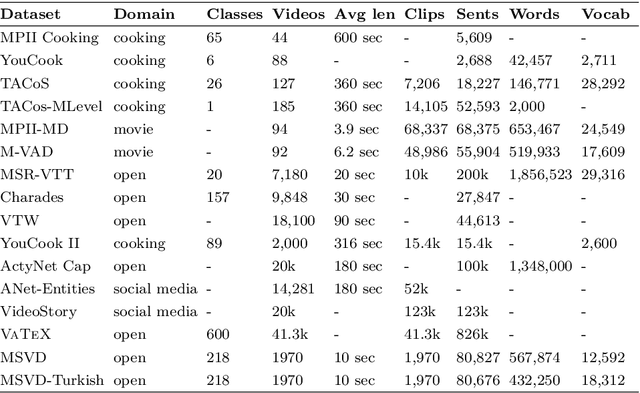
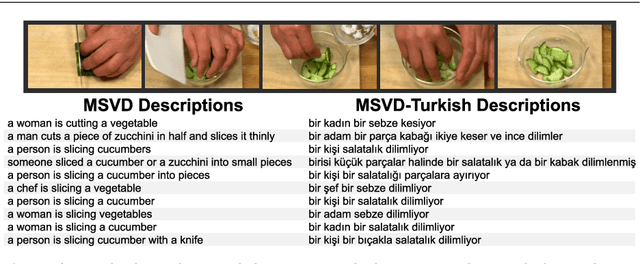

Automatic generation of video descriptions in natural language, also called video captioning, aims to understand the visual content of the video and produce a natural language sentence depicting the objects and actions in the scene. This challenging integrated vision and language problem, however, has been predominantly addressed for English. The lack of data and the linguistic properties of other languages limit the success of existing approaches for such languages. In this paper we target Turkish, a morphologically rich and agglutinative language that has very different properties compared to English. To do so, we create the first large scale video captioning dataset for this language by carefully translating the English descriptions of the videos in the MSVD (Microsoft Research Video Description Corpus) dataset into Turkish. In addition to enabling research in video captioning in Turkish, the parallel English-Turkish descriptions also enables the study of the role of video context in (multimodal) machine translation. In our experiments, we build models for both video captioning and multimodal machine translation and investigate the effect of different word segmentation approaches and different neural architectures to better address the properties of Turkish. We hope that the MSVD-Turkish dataset and the results reported in this work will lead to better video captioning and multimodal machine translation models for Turkish and other morphology rich and agglutinative languages.