 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Machine Translation through Visuals and Speech
Nov 28, 2019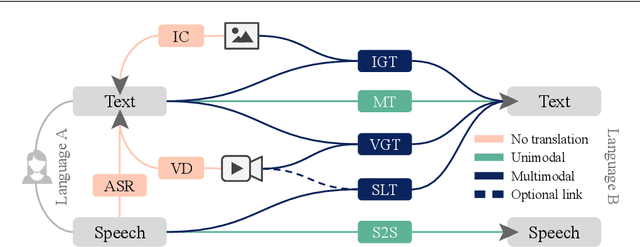
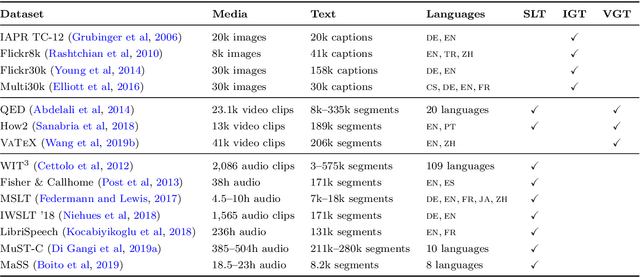

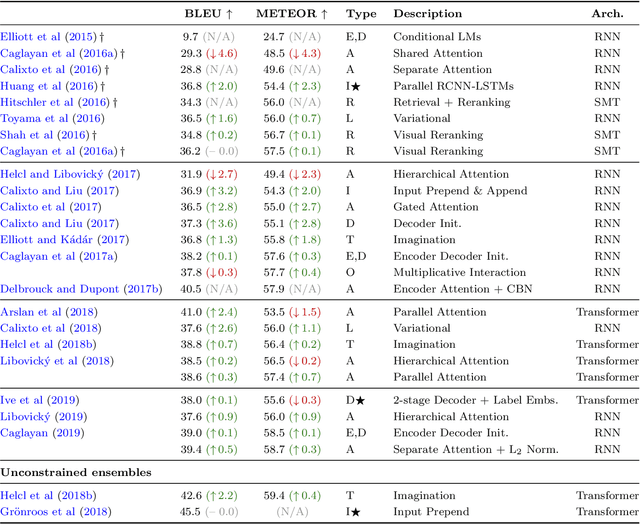
Multimodal machine translation involves drawing information from more than one modality, based on the assumption that the additional modalities will contain useful alternative views of the input data. The most prominent tasks in this area are spoken language translation, image-guided translation, and video-guided translation, which exploit audio and visual modalities, respectively. These tasks are distinguished from their monolingual counterparts of speech recognition, image captioning, and video captioning by the requirement of models to generate outputs in a different language. This survey reviews the major data resources for these tasks, the evaluation campaigns concentrated around them, the state of the art in end-to-end and pipeline approaches, and also the challenges in performance evaluation. The paper concludes with a discussion of directions for future research in these areas: the need for more expansive and challenging datasets, for targeted evaluations of model performance, and for multimodality in both the input and output space.
The University of Helsinki submissions to the WMT19 news translation task
Jun 10, 2019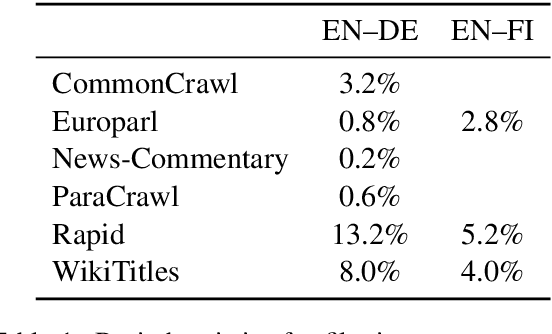
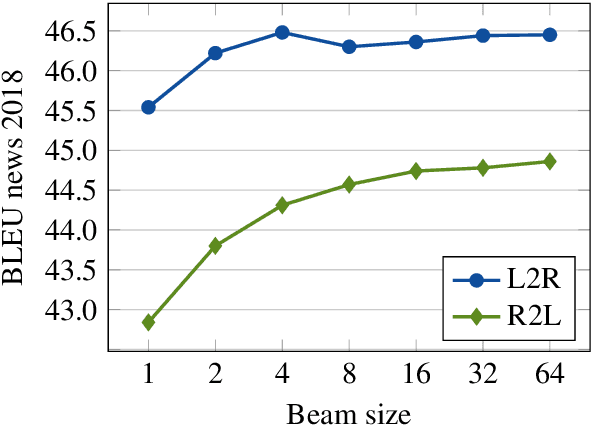

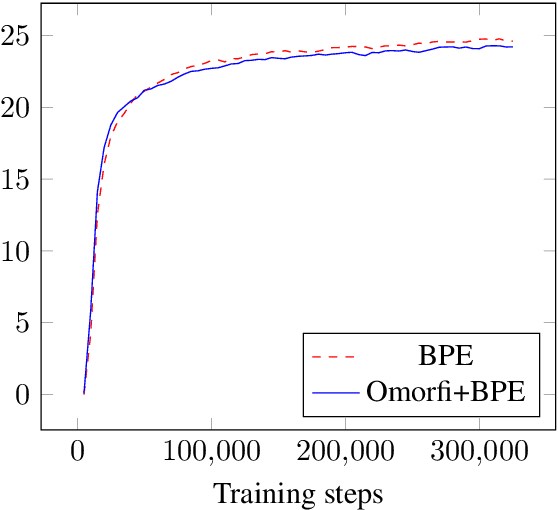
In this paper, we present the University of Helsinki submissions to the WMT 2019 shared task on news translation in three language pairs: English-German, English-Finnish and Finnish-English. This year, we focused first on cleaning and filtering the training data using multiple data-filtering approaches, resulting in much smaller and cleaner training sets. For English-German, we trained both sentence-level transformer models and compared different document-level translation approaches. For Finnish-English and English-Finnish we focused on different segmentation approaches, and we also included a rule-based system for English-Finnish.
The MeMAD Submission to the IWSLT 2018 Speech Translation Task
Oct 24, 2018

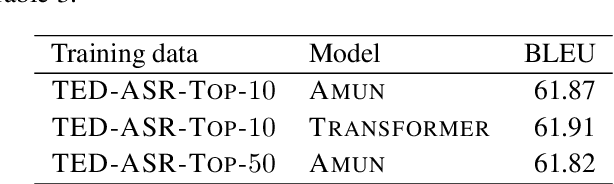

This paper describes the MeMAD project entry to the IWSLT Speech Translation Shared Task, addressing the translation of English audio into German text. Between the pipeline and end-to-end model tracks, we participated only in the former, with three contrastive systems. We tried also the latter, but were not able to finish our end-to-end model in time. All of our systems start by transcribing the audio into text through an automatic speech recognition (ASR) model trained on the TED-LIUM English Speech Recognition Corpus (TED-LIUM). Afterwards, we feed the transcripts into English-German text-based neural machine translation (NMT) models. Our systems employ three different translation models trained on separate training sets compiled from the English-German part of the TED Speech Translation Corpus (TED-Trans) and the OpenSubtitles2018 section of the OPUS collection. In this paper, we also describe the experiments leading up to our final systems. Our experiments indicate that using OpenSubtitles2018 in training significantly improves translation performance. We also experimented with various pre- and postprocessing routines for the NMT module, but we did not have much success with these. Our best-scoring system attains a BLEU score of 16.45 on the test set for this year's task.
The MeMAD Submission to the WMT18 Multimodal Translation Task
Sep 03, 2018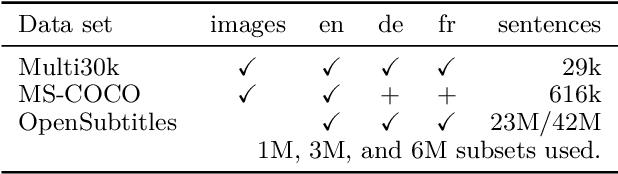
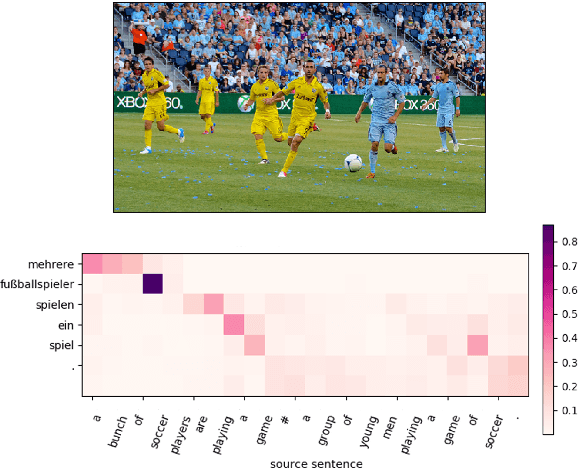
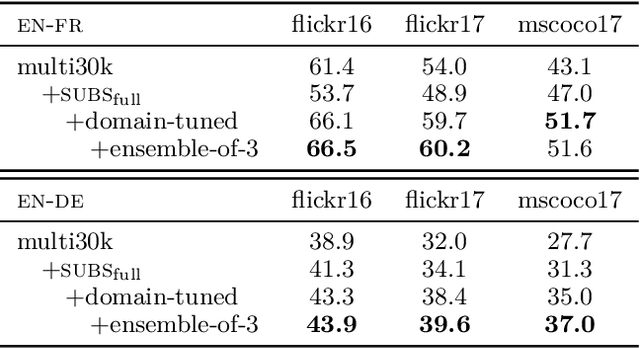

This paper describes the MeMAD project entry to the WMT Multimodal Machine Translation Shared Task. We propose adapting the Transformer neural machine translation (NMT) architecture to a multi-modal setting. In this paper, we also describe the preliminary experiments with text-only translation systems leading us up to this choice. We have the top scoring system for both English-to-German and English-to-French, according to the automatic metrics for flickr18. Our experiments show that the effect of the visual features in our system is small. Our largest gains come from the quality of the underlying text-only NMT system. We find that appropriate use of additional data is effective.