 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoro 34B and the Blessing of Multilinguality
Apr 02, 2024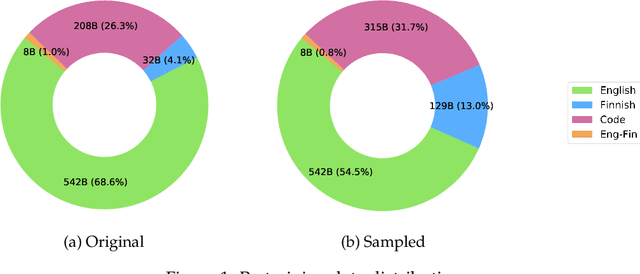

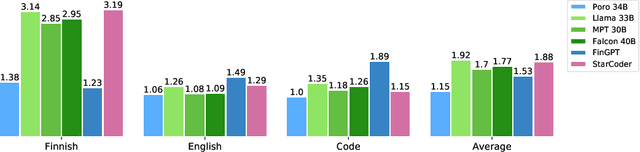

The pretraining of state-of-the-art large language models now requires trillions of words of text, which is orders of magnitude more than available for the vast majority of languages. While including text in more than one language is an obvious way to acquire more pretraining data, multilinguality is often seen as a curse, and most model training efforts continue to focus near-exclusively on individual large languages. We believe that multilinguality can be a blessing and that it should be possible to substantially improve over the capabilities of monolingual models for small languages through multilingual training. In this study, we introduce Poro 34B, a 34 billion parameter model trained for 1 trillion tokens of Finnish, English, and programming languages, and demonstrate that a multilingual training approach can produce a model that not only substantially advances over the capabilities of existing models for Finnish, but also excels in translation and is competitive in its class in generating English and programming languages. We release the model parameters, scripts, and data under open licenses at https://huggingface.co/LumiOpen/Poro-34B.
Uncertainty-Aware Natural Language Inference with Stochastic Weight Averaging
Apr 10, 2023This paper introduces Bayesian uncertainty modeling using Stochastic Weight Averaging-Gaussian (SWAG) in Natural Language Understanding (NLU) tasks. We apply the approach to standard tasks in natural language inference (NLI) and demonstrate the effectiveness of the method in terms of prediction accuracy and correlation with human annotation disagreements. We argue that the uncertainty representations in SWAG better reflect subjective interpretation and the natural variation that is also present in human language understanding. The results reveal the importance of uncertainty modeling, an often neglected aspect of neural language modeling, in NLU tasks.
How Does Data Corruption Affect Natural Language Understanding Models? A Study on GLUE datasets
Jan 12, 2022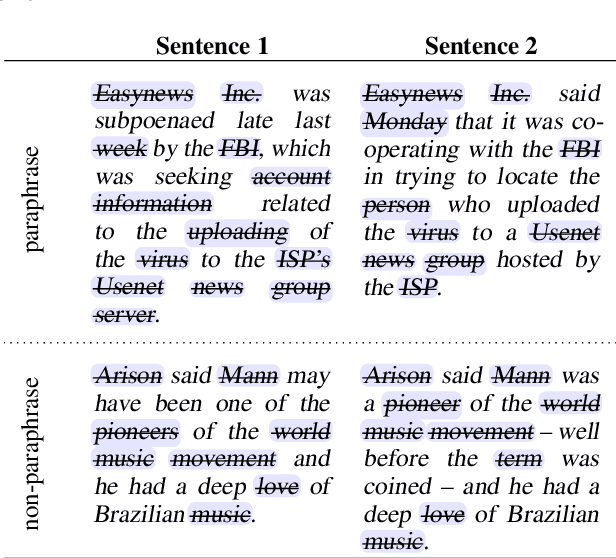
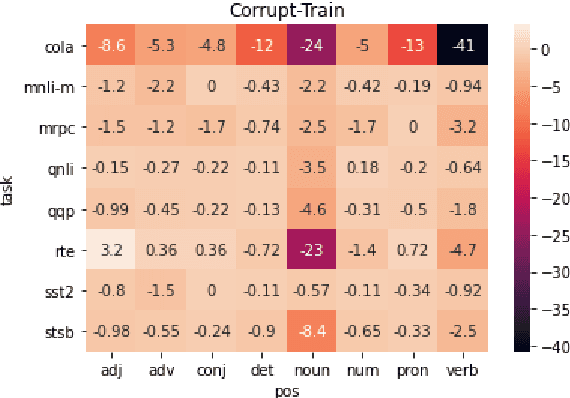

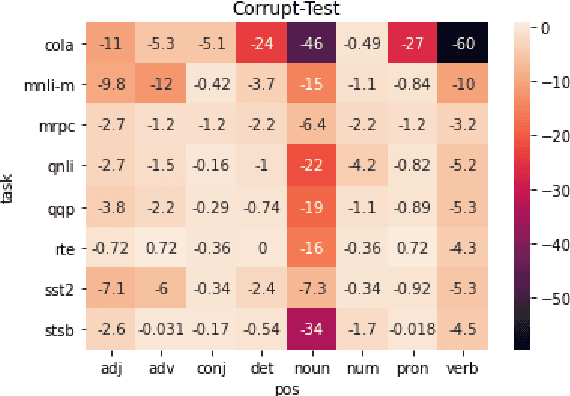
A central question in natural language understanding (NLU) research is whether high performance demonstrates the models' strong reasoning capabilities. We present an extensive series of controlled experiments where pre-trained language models are exposed to data that have undergone specific corruption transformations. The transformations involve removing instances of specific word classes and often lead to non-sensical sentences. Our results show that performance remains high for most GLUE tasks when the models are fine-tuned or tested on corrupted data, suggesting that the models leverage other cues for prediction even in non-sensical contexts. Our proposed data transformations can be used as a diagnostic tool for assessing the extent to which a specific dataset constitutes a proper testbed for evaluating models' language understanding capabilities.
NLI Data Sanity Check: Assessing the Effect of Data Corruption on Model Performance
Apr 10, 2021
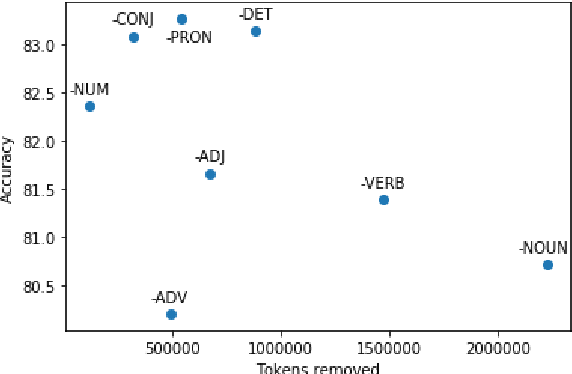

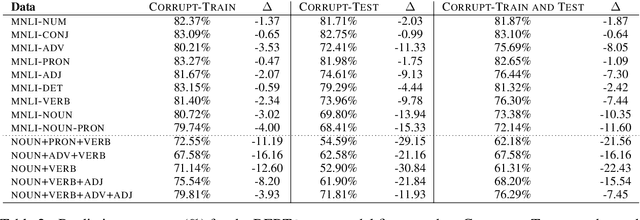
Pre-trained neural language models give high performance on natural language inference (NLI) tasks. But whether they actually understand the meaning of the processed sequences remains unclear. We propose a new diagnostics test suite which allows to assess whether a dataset constitutes a good testbed for evaluating the models' meaning understanding capabilities. We specifically apply controlled corruption transformations to widely used benchmarks (MNLI and ANLI), which involve removing entire word classes and often lead to non-sensical sentence pairs. If model accuracy on the corrupted data remains high, then the dataset is likely to contain statistical biases and artefacts that guide prediction. Inversely, a large decrease in model accuracy indicates that the original dataset provides a proper challenge to the models' reasoning capabilities. Hence, our proposed controls can serve as a crash test for developing high quality data for NLI tasks.
Predicting Prosodic Prominence from Text with Pre-trained Contextualized Word Representations
Aug 06, 2019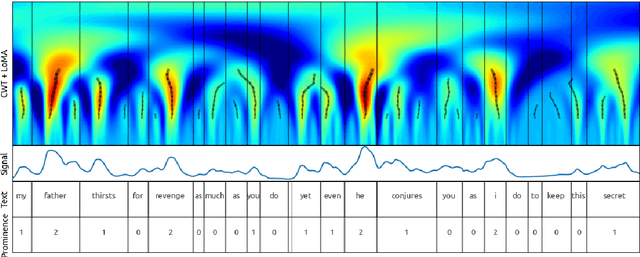
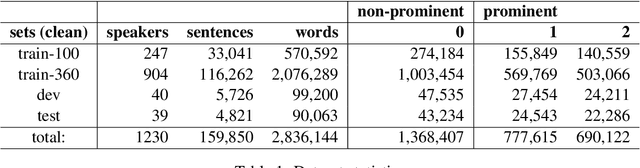

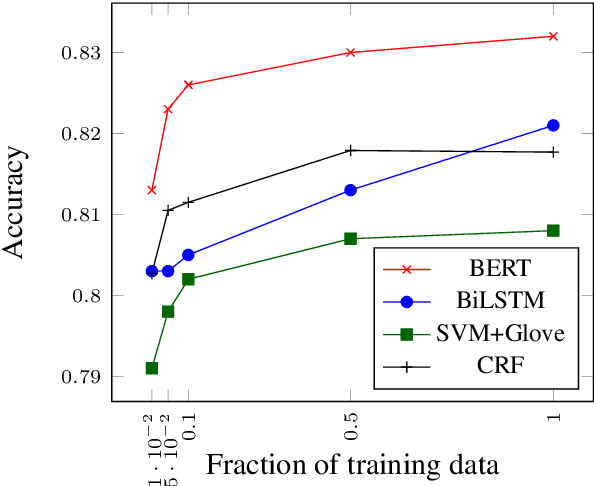
In this paper we introduce a new natural language processing dataset and benchmark for predicting prosodic prominence from written text. To our knowledge this will be the largest publicly available dataset with prosodic labels. We describe the dataset construction and the resulting benchmark dataset in detail and train a number of different models ranging from feature-based classifiers to neural network systems for the prediction of discretized prosodic prominence. We show that pre-trained contextualized word representations from BERT outperform the other models even with less than 10% of the training data. Finally we discuss the dataset in light of the results and point to future research and plans for further improving both the dataset and methods of predicting prosodic prominence from text. The dataset and the code for the models are publicly available.
The University of Helsinki submissions to the WMT19 news translation task
Jun 10, 2019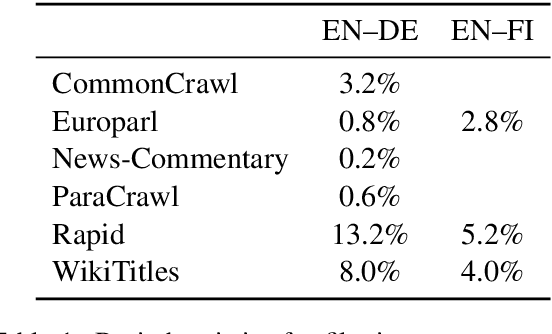
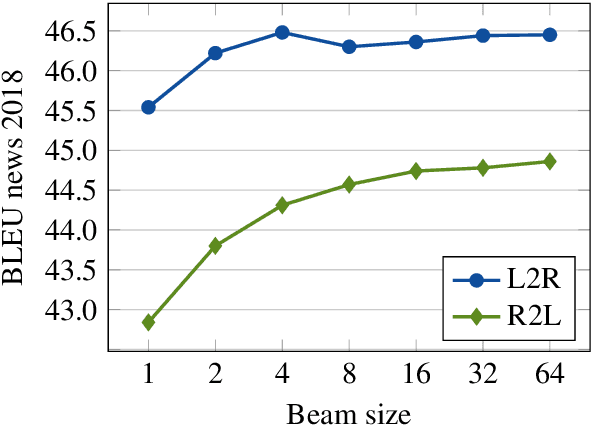

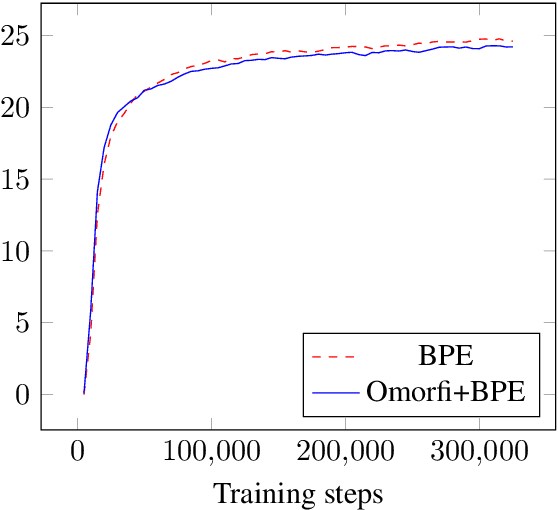
In this paper, we present the University of Helsinki submissions to the WMT 2019 shared task on news translation in three language pairs: English-German, English-Finnish and Finnish-English. This year, we focused first on cleaning and filtering the training data using multiple data-filtering approaches, resulting in much smaller and cleaner training sets. For English-German, we trained both sentence-level transformer models and compared different document-level translation approaches. For Finnish-English and English-Finnish we focused on different segmentation approaches, and we also included a rule-based system for English-Finnish.
Testing the Generalization Power of Neural Network Models Across NLI Benchmarks
Oct 30, 2018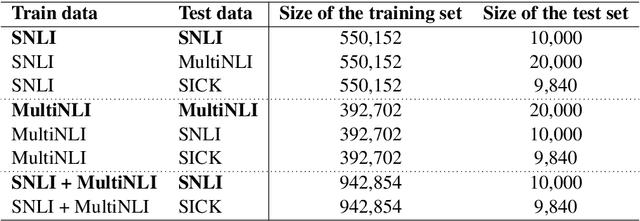
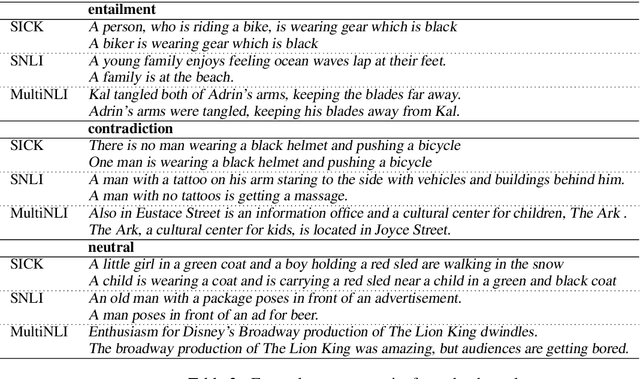
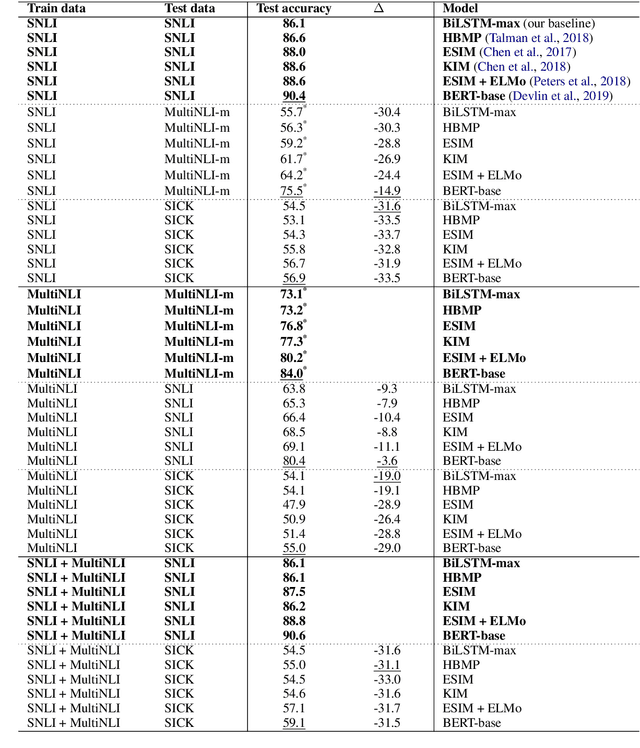
Neural network models have been very successful for natural language inference, with the best models reaching 90% accuracy in some benchmarks. However, the success of these models turns out to be largely benchmark specific. We show that models trained on natural language inference dataset drawn from one benchmark fail to perform well in others, even if the notion of inference assumed in these benchmark tasks is the same or similar. We train five state-of-the-art neural network models on different datasets and show that each one of these fail to generalize outside of the respective benchmark. In light of these results we conclude that the current neural network models are not able to generalize in capturing the semantics of natural language inference, but seem to be overfitting to the specific dataset.
Natural Language Inference with Hierarchical BiLSTM Max Pooling Architecture
Aug 27, 2018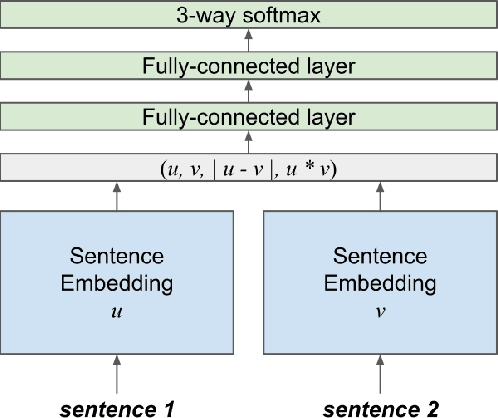

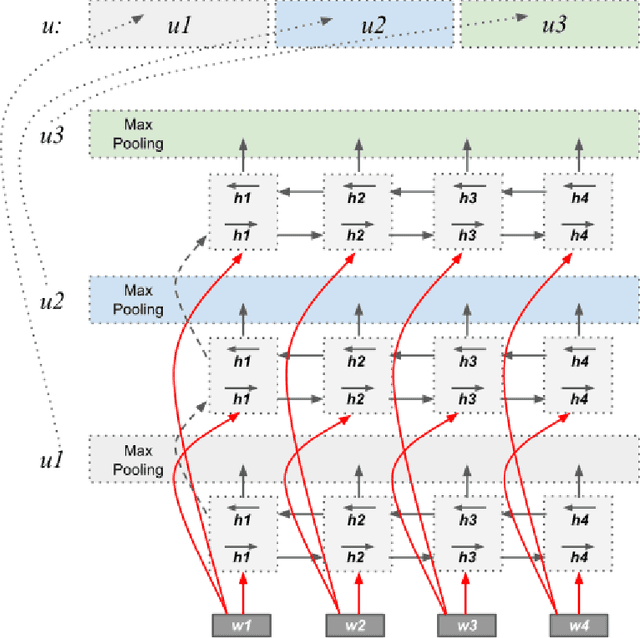

Recurrent neural networks have proven to be very effective for natural language inference tasks. We build on top of one such model, namely BiLSTM with max pooling, and show that adding a hierarchy of BiLSTM and max pooling layers yields state of the art results for the SNLI sentence encoding-based models and the SciTail dataset, as well as provides strong results for the MultiNLI dataset. We also show that our sentence embeddings can be utilized in a wide variety of transfer learning tasks, outperforming InferSent on 7 out of 10 and SkipThought on 8 out of 9 SentEval sentence embedding evaluation tasks. Furthermore, our model beats the InferSent model in 8 out of 10 recently published SentEval probing tasks designed to evaluate sentence embeddings' ability to capture some of the important linguistic properties of sentences.