 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeiMiGUE-Speech: A Spontaneous Speech Dataset for Affective Analysis
Feb 25, 2026This work presents iMiGUE-Speech, an extension of the iMiGUE dataset that provides a spontaneous affective corpus for studying emotional and affective states. The new release focuses on speech and enriches the original dataset with additional metadata, including speech transcripts, speaker-role separation between interviewer and interviewee, and word-level forced alignments. Unlike existing emotional speech datasets that rely on acted or laboratory-elicited emotions, iMiGUE-Speech captures spontaneous affect arising naturally from real match outcomes. To demonstrate the utility of the dataset and establish initial benchmarks, we introduce two evaluation tasks for comparative assessment: speech emotion recognition and transcript-based sentiment analysis. These tasks leverage state-of-the-art pre-trained representations to assess the dataset's ability to capture spontaneous affective states from both acoustic and linguistic modalities. iMiGUE-Speech can also be synchronously paired with micro-gesture annotations from the original iMiGUE dataset, forming a uniquely multimodal resource for studying speech-gesture affective dynamics. The extended dataset is available at https://github.com/CV-AC/imigue-speech.
Investigating the Utility of Surprisal from Large Language Models for Speech Synthesis Prosody
Jun 16, 2023This paper investigates the use of word surprisal, a measure of the predictability of a word in a given context, as a feature to aid speech synthesis prosody. We explore how word surprisal extracted from large language models (LLMs) correlates with word prominence, a signal-based measure of the salience of a word in a given discourse. We also examine how context length and LLM size affect the results, and how a speech synthesizer conditioned with surprisal values compares with a baseline system. To evaluate these factors, we conducted experiments using a large corpus of English text and LLMs of varying sizes. Our results show that word surprisal and word prominence are moderately correlated, suggesting that they capture related but distinct aspects of language use. We find that length of context and size of the LLM impact the correlations, but not in the direction anticipated, with longer contexts and larger LLMs generally underpredicting prominent words in a nearly linear manner. We demonstrate that, in line with these findings, a speech synthesizer conditioned with surprisal values provides a minimal improvement over the baseline with the results suggesting a limited effect of using surprisal values for eliciting appropriate prominence patterns.
The Power of Prosody and Prosody of Power: An Acoustic Analysis of Finnish Parliamentary Speech
May 25, 2023Parliamentary recordings provide a rich source of data for studying how politicians use speech to convey their messages and influence their audience. This provides a unique context for studying how politicians use speech, especially prosody, to achieve their goals. Here we analyzed a corpus of parliamentary speeches in the Finnish parliament between the years 2008-2020 and highlight methodological considerations related to the robustness of signal based features with respect to varying recording conditions and corpus design. We also present results of long term changes pertaining to speakers' status with respect to their party being in government or in opposition. Looking at large scale averages of fundamental frequency - a robust prosodic feature - we found systematic changes in speech prosody with respect opposition status and the election term. Reflecting a different level of urgency, members of the parliament have higher f0 at the beginning of the term or when they are in opposition.
North Sámi Dialect Identification with Self-supervised Speech Models
May 19, 2023



The North S\'{a}mi (NS) language encapsulates four primary dialectal variants that are related but that also have differences in their phonology, morphology, and vocabulary. The unique geopolitical location of NS speakers means that in many cases they are bilingual in S\'{a}mi as well as in the dominant state language: Norwegian, Swedish, or Finnish. This enables us to study the NS variants both with respect to the spoken state language and their acoustic characteristics. In this paper, we investigate an extensive set of acoustic features, including MFCCs and prosodic features, as well as state-of-the-art self-supervised representations, namely, XLS-R, WavLM, and HuBERT, for the automatic detection of the four NS variants. In addition, we examine how the majority state language is reflected in the dialects. Our results show that NS dialects are influenced by the state language and that the four dialects are separable, reaching high classification accuracy, especially with the XLS-R model.
What does BERT learn about prosody?
Apr 25, 2023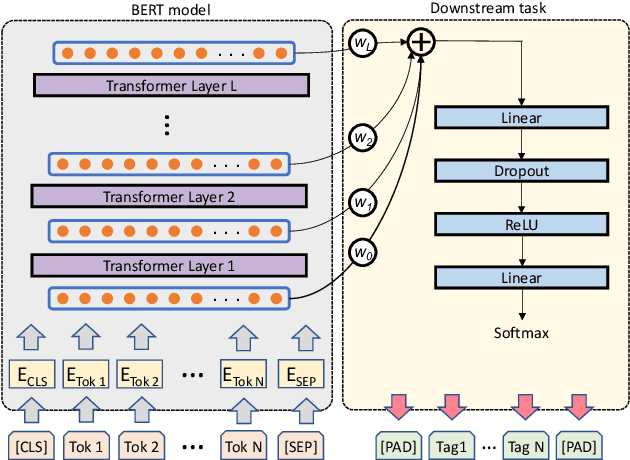
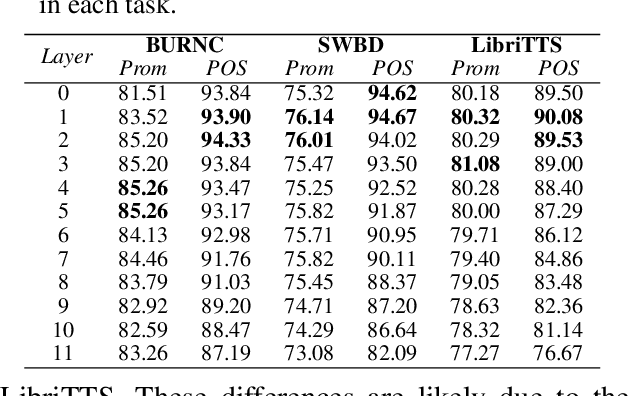
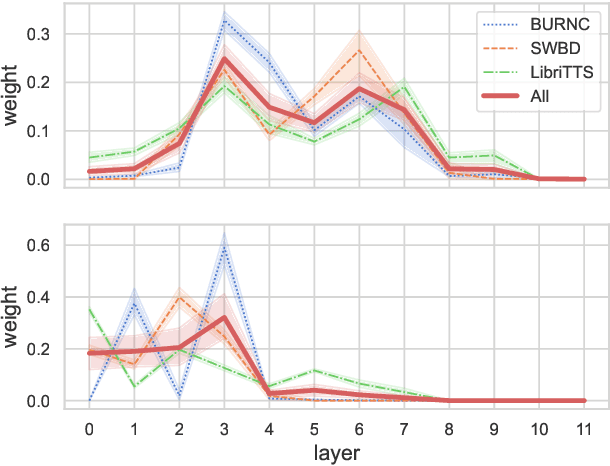

Language models have become nearly ubiquitous in natural language processing applications achieving state-of-the-art results in many tasks including prosody. As the model design does not define predetermined linguistic targets during training but rather aims at learning generalized representations of the language, analyzing and interpreting the representations that models implicitly capture is important in bridging the gap between interpretability and model performance. Several studies have explored the linguistic information that models capture providing some insights on their representational capacity. However, the current studies have not explored whether prosody is part of the structural information of the language that models learn. In this work, we perform a series of experiments on BERT probing the representations captured at different layers. Our results show that information about prosodic prominence spans across many layers but is mostly focused in middle layers suggesting that BERT relies mostly on syntactic and semantic information.
Speech-based emotion recognition with self-supervised models using attentive channel-wise correlations and label smoothing
Nov 03, 2022When recognizing emotions from speech, we encounter two common problems: how to optimally capture emotion-relevant information from the speech signal and how to best quantify or categorize the noisy subjective emotion labels. Self-supervised pre-trained representations can robustly capture information from speech enabling state-of-the-art results in many downstream tasks including emotion recognition. However, better ways of aggregating the information across time need to be considered as the relevant emotion information is likely to appear piecewise and not uniformly across the signal. For the labels, we need to take into account that there is a substantial degree of noise that comes from the subjective human annotations. In this paper, we propose a novel approach to attentive pooling based on correlations between the representations' coefficients combined with label smoothing, a method aiming to reduce the confidence of the classifier on the training labels. We evaluate our proposed approach on the benchmark dataset IEMOCAP, and demonstrate high performance surpassing that in the literature. The code to reproduce the results is available at github.com/skakouros/s3prl_attentive_correlation.
Extracting speaker and emotion information from self-supervised speech models via channel-wise correlations
Oct 15, 2022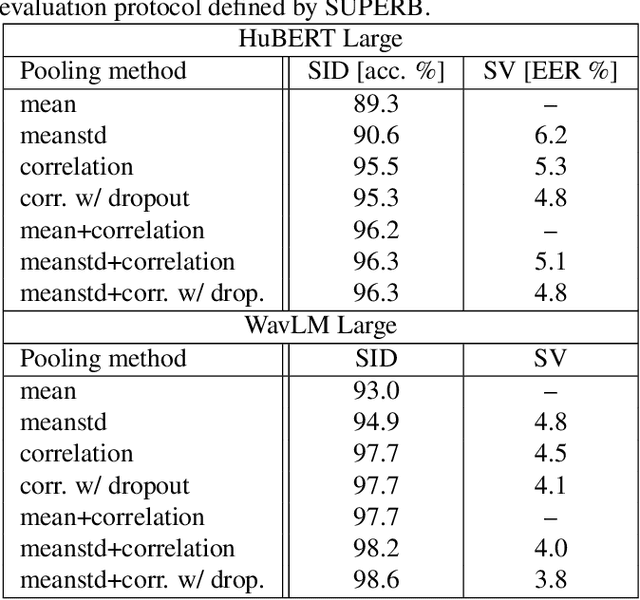
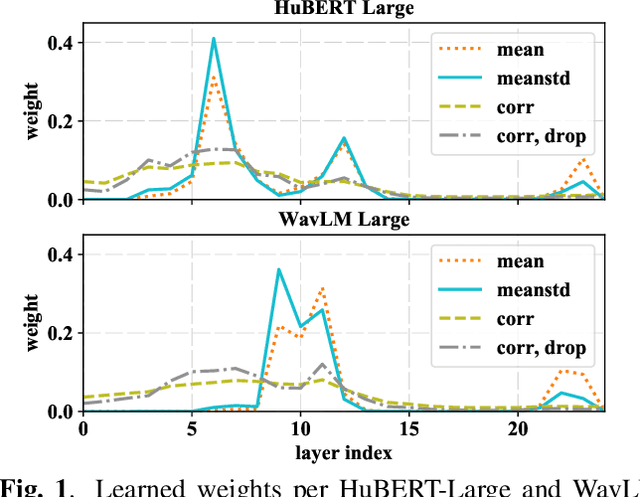
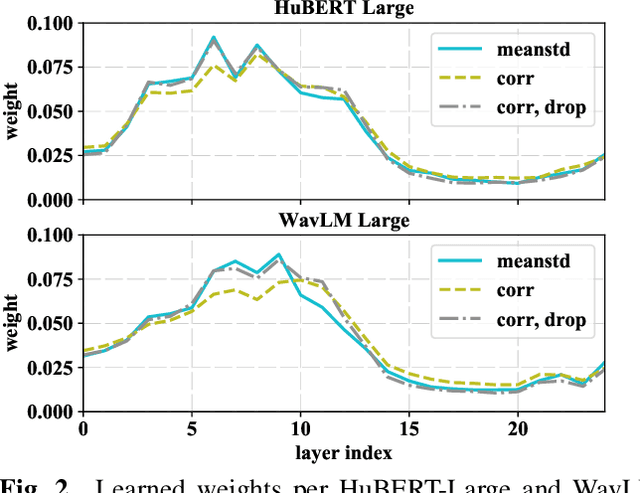
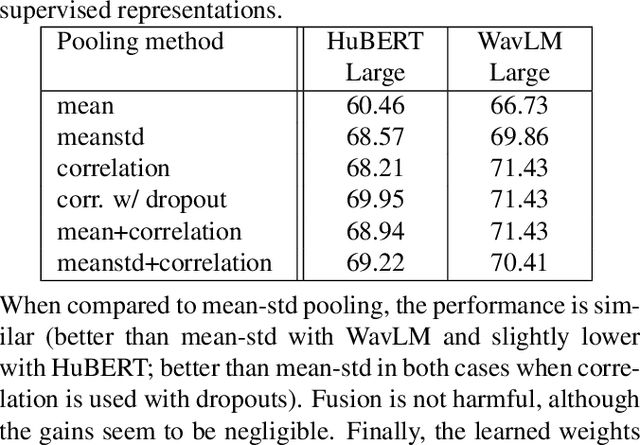
Self-supervised learning of speech representations from large amounts of unlabeled data has enabled state-of-the-art results in several speech processing tasks. Aggregating these speech representations across time is typically approached by using descriptive statistics, and in particular, using the first- and second-order statistics of representation coefficients. In this paper, we examine an alternative way of extracting speaker and emotion information from self-supervised trained models, based on the correlations between the coefficients of the representations - correlation pooling. We show improvements over mean pooling and further gains when the pooling methods are combined via fusion. The code is available at github.com/Lamomal/s3prl_correlation.
Predicting Prosodic Prominence from Text with Pre-trained Contextualized Word Representations
Aug 06, 2019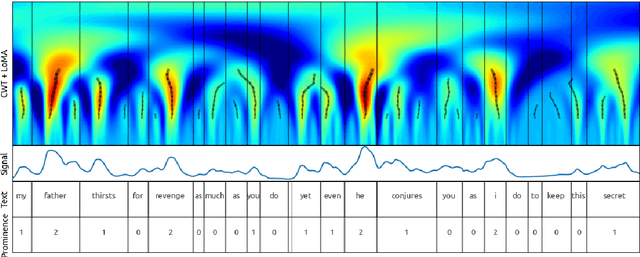
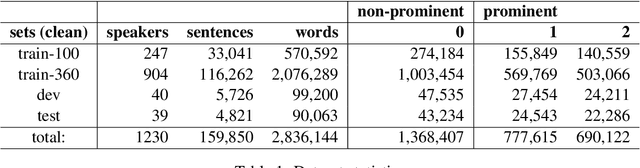

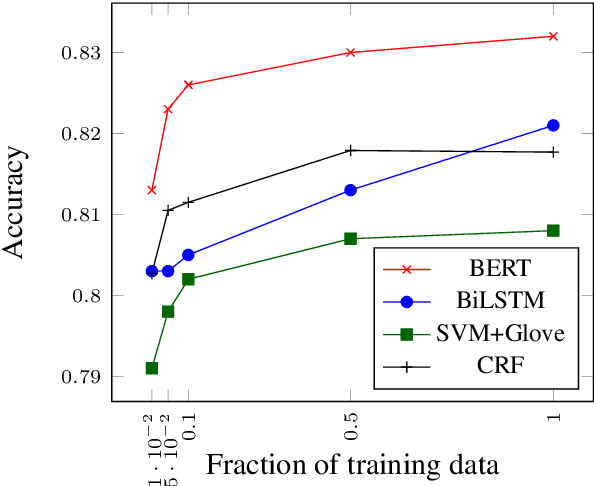
In this paper we introduce a new natural language processing dataset and benchmark for predicting prosodic prominence from written text. To our knowledge this will be the largest publicly available dataset with prosodic labels. We describe the dataset construction and the resulting benchmark dataset in detail and train a number of different models ranging from feature-based classifiers to neural network systems for the prediction of discretized prosodic prominence. We show that pre-trained contextualized word representations from BERT outperform the other models even with less than 10% of the training data. Finally we discuss the dataset in light of the results and point to future research and plans for further improving both the dataset and methods of predicting prosodic prominence from text. The dataset and the code for the models are publicly available.