 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtracting speaker and emotion information from self-supervised speech models via channel-wise correlations
Paper and Code
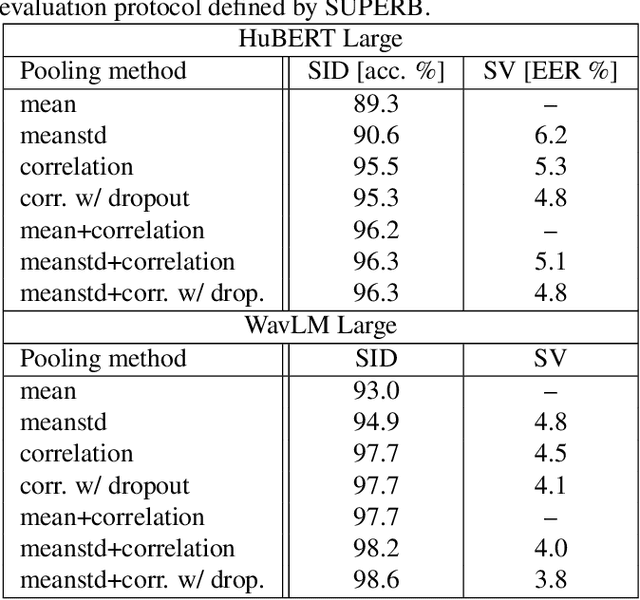
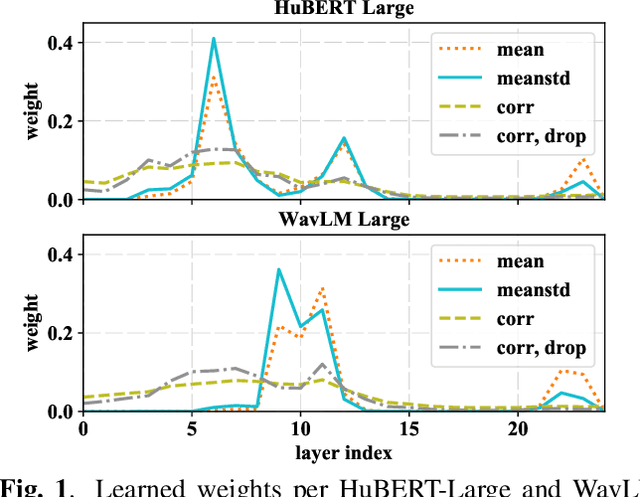
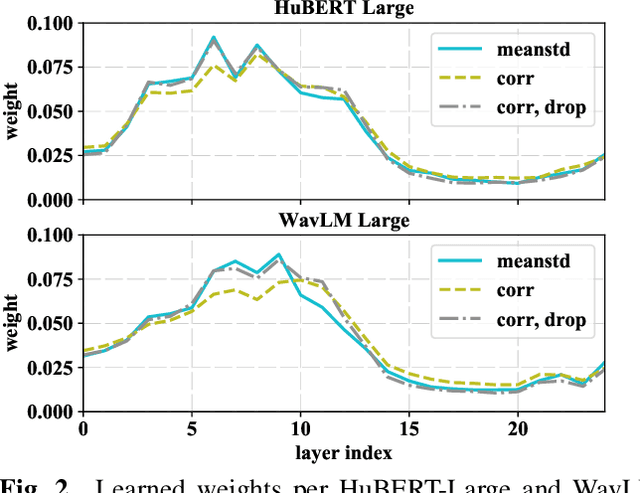
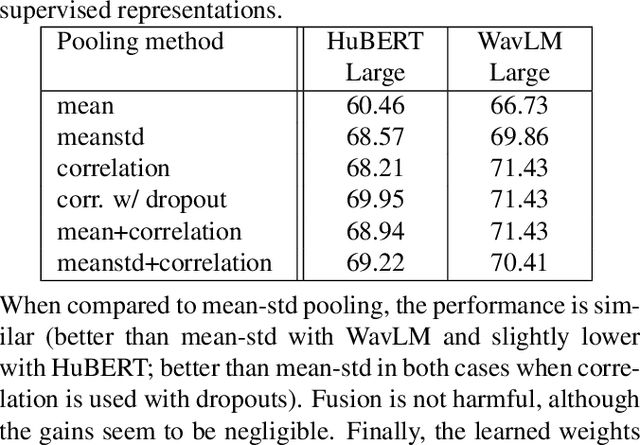
Self-supervised learning of speech representations from large amounts of unlabeled data has enabled state-of-the-art results in several speech processing tasks. Aggregating these speech representations across time is typically approached by using descriptive statistics, and in particular, using the first- and second-order statistics of representation coefficients. In this paper, we examine an alternative way of extracting speaker and emotion information from self-supervised trained models, based on the correlations between the coefficients of the representations - correlation pooling. We show improvements over mean pooling and further gains when the pooling methods are combined via fusion. The code is available at github.com/Lamomal/s3prl_correlation.