 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClosing the Loop: PID Feedback Control for Interpretable Activation Steering in Symbolic Music Generation
Jun 17, 2026Transformer-based architectures have significantly advanced the generation of complex symbolic sequences, yet a significant gap remains in achieving fine-grained, interpretable control over discrete signal attributes. This paper investigates the mechanistic interpretability of the Multitrack Music Transformer (MMT) and proposes a framework for deterministic attribute modulation without retraining to bridge this gap via inference-time activation steering. Utilizing the Difference-in-Means (DiffMean) methodology, we isolate latent directions for signal attributes, specifically Pitch and Duration, within the residual stream. We validate the Linear Representation Hypothesis in this domain, achieving high correlation between steering magnitude and attribute shift. To address the inherent feature entanglement in multi-attribute steering, we introduce a Dual Steering framework utilizing Gram-Schmidt Orthogonalization. Experimental results demonstrate that this geometric decoupling reduces conceptual interference and signal degradation compared to naive vector addition, enabling independent deterministic control even against strong autoregressive conditioning.
SpeakerCard-1M: An Evidence-Grounded Speaker Card Corpus for In-the-Wild Speaker Verification
Jun 03, 2026Modern speaker verification (SV) systems rely on speaker embeddings that are effective but difficult to interpret or query in natural language. Most existing speech-text corpora target controllable synthesis or utterance-level captioning, and provide limited speaker-level supervision for in-the-wild speaker recognition. This paper introduces SpeakerCard-1M, a bilingual speaker-centric resource for evidence-grounded SV, derived from VoxCeleb1/2 and CN-Celeb1/2, where the "-1M" suffix refers to the 1.78M utterance-level captions contained in the release. We adopt a tool-first, LLM-last approach: ten acoustic probes produce field-level evidence, the evidence is aggregated into speaker profiles under a schema that separates relatively stable traits from utterance-level states, and bilingual Speaker Cards are rendered by a constrained LLM that sees only the structured fields. The release includes 56.7K Speaker Card records over 10.2K speakers, 1.78M utterance-level captions, and speaker-ID-disjoint hard-negative triplets. We further define two SV-oriented cross-modal protocols, bidirectional Speaker-Text Retrieval (T2S-R / S2T-R) and Attribute-Conditioned Verification (AC-Verify), and compare a dual-encoder baseline against recent audio language models under a zero-shot forced-choice setting. Joint audio-text training increases VoxCeleb1-O EER by 0.31% absolute over the audio-only baseline. Under a style-symmetric LLM-generated counterfactual protocol, eight recent audio language models (7B-30B+ parameters, both open- and closed-source) score 49-77% on pitch-level AC-Verify under two-way forced choice, compared with 88.66% reached by our dual encoder.
Latent Space Disentanglement via Activation Steering for Interpretable Attribute Control in Symbolic Music Generation
May 29, 2026Transformer-based architectures have significantly advanced the generation of complex symbolic sequences, yet a significant gap remains in achieving fine-grained, interpretable control over discrete signal attributes. This paper investigates the mechanistic interpretability of the Multitrack Music Transformer (MMT) and proposes a framework for deterministic attribute modulation without retraining to bridge this gap via inference-time activation steering. Utilizing the Difference-in-Means (DiffMean) methodology, we isolate latent directions for signal attributes, specifically Pitch and Duration, within the residual stream. We validate the Linear Representation Hypothesis in this domain, achieving high correlation between steering magnitude and attribute shift. To address the inherent feature entanglement in multi-attribute steering, we introduce a Dual Steering framework utilizing Gram-Schmidt Orthogonalization. Experimental results demonstrate that this geometric decoupling reduces conceptual interference and signal degradation compared to naive vector addition, enabling independent deterministic control even against strong autoregressive conditioning.
LabelBuddy: An Open Source Music and Audio Language Annotation Tagging Tool Using AI Assistance
Mar 04, 2026The advancement of Machine learning (ML), Large Audio Language Models (LALMs), and autonomous AI agents in Music Information Retrieval (MIR) necessitates a shift from static tagging to rich, human-aligned representation learning. However, the scarcity of open-source infrastructure capable of capturing the subjective nuances of audio annotation remains a critical bottleneck. This paper introduces \textbf{LabelBuddy}, an open-source collaborative auto-tagging audio annotation tool designed to bridge the gap between human intent and machine understanding. Unlike static tools, it decouples the interface from inference via containerized backends, allowing users to plug in custom models for AI-assisted pre-annotation. We describe the system architecture, which supports multi-user consensus, containerized model isolation, and a roadmap for extending agents and LALMs. Code available at https://github.com/GiannisProkopiou/gsoc2022-Label-buddy.
Alpha Divergence Losses for Biometric Verification
Nov 19, 2025Performance in face and speaker verification is largely driven by margin based softmax losses like CosFace and ArcFace. Recently introduced $α$-divergence loss functions offer a compelling alternative, particularly for their ability to induce sparse solutions (when $α>1$). However, integrating an angular margin-crucial for verification tasks-is not straightforward. We find this integration can be achieved in at least two distinct ways: via the reference measure (prior probabilities) or via the logits (unnormalized log-likelihoods). In this paper, we explore both pathways, deriving two novel margin-based $α$-divergence losses: Q-Margin (margin in the reference measure) and A3M (margin in the logits). We identify and address a critical training instability in A3M-caused by the interplay of penalized logits and sparsity-with a simple yet effective prototype re-initialization strategy. Our methods achieve significant performance gains on the challenging IJB-B and IJB-C face verification benchmarks. We demonstrate similarly strong performance in speaker verification on VoxCeleb. Crucially, our models significantly outperform strong baselines at low false acceptance rates (FAR). This capability is crucial for practical high-security applications, such as banking authentication, when minimizing false authentications is paramount.
Analysis of ABC Frontend Audio Systems for the NIST-SRE24
May 21, 2025We present a comprehensive analysis of the embedding extractors (frontends) developed by the ABC team for the audio track of NIST SRE 2024. We follow the two scenarios imposed by NIST: using only a provided set of telephone recordings for training (fixed) or adding publicly available data (open condition). Under these constraints, we develop the best possible speaker embedding extractors for the pre-dominant conversational telephone speech (CTS) domain. We explored architectures based on ResNet with different pooling mechanisms, recently introduced ReDimNet architecture, as well as a system based on the XLS-R model, which represents the family of large pre-trained self-supervised models. In open condition, we train on VoxBlink2 dataset, containing 110 thousand speakers across multiple languages. We observed a good performance and robustness of VoxBlink-trained models, and our experiments show practical recipes for developing state-of-the-art frontends for speaker recognition.
State-of-the-art Embeddings with Video-free Segmentation of the Source VoxCeleb Data
Oct 03, 2024



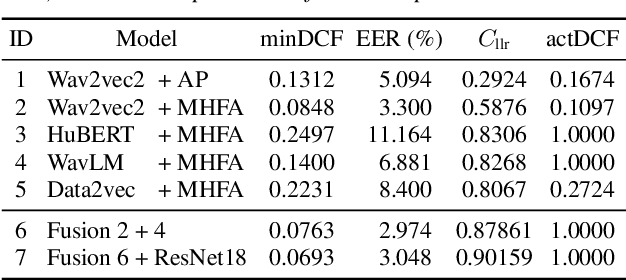
In this paper, we refine and validate our method for training speaker embedding extractors using weak annotations. More specifically, we use only the audio stream of the source VoxCeleb videos and the names of the celebrities without knowing the time intervals in which they appear in the recording. We experiment with hyperparameters and embedding extractors based on ResNet and WavLM. We show that the method achieves state-of-the-art results in speaker verification, comparable with training the extractors in a standard supervised way on the VoxCeleb dataset. We also extend it by considering segments belonging to unknown speakers appearing alongside the celebrities, which are typically being discarded. Overall, our approach can be used for directly training state-of-the-art embedding extractors or as an alternative to the VoxCeleb-like pipeline for dataset creation without needing image modality.
BUT Systems and Analyses for the ASVspoof 5 Challenge
Aug 20, 2024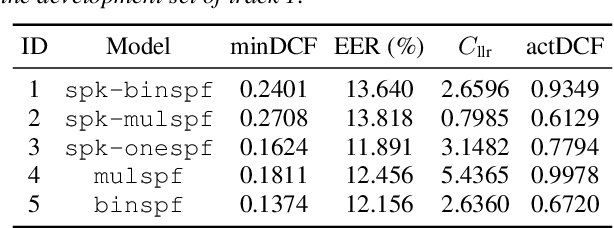
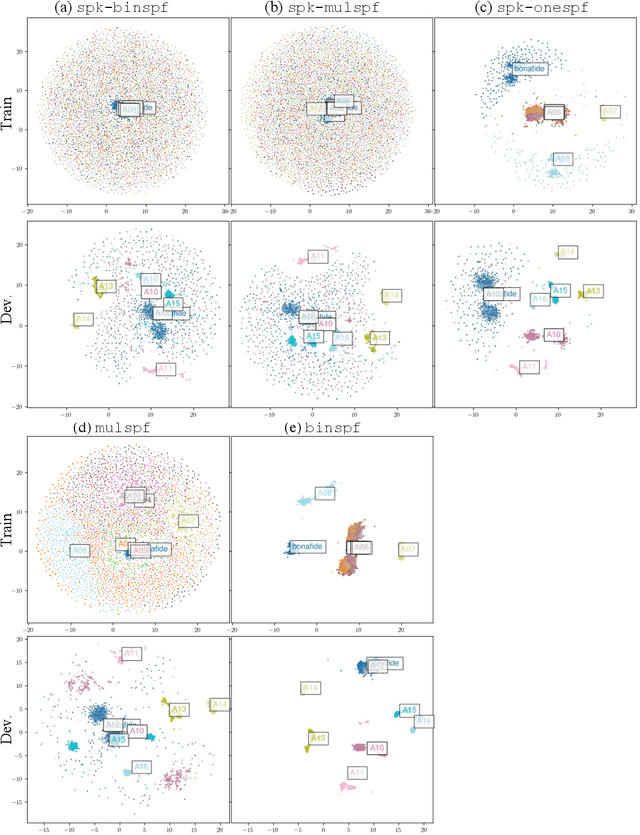

This paper describes the BUT submitted systems for the ASVspoof 5 challenge, along with analyses. For the conventional deepfake detection task, we use ResNet18 and self-supervised models for the closed and open conditions, respectively. In addition, we analyze and visualize different combinations of speaker information and spoofing information as label schemes for training. For spoofing-robust automatic speaker verification (SASV), we introduce effective priors and propose using logistic regression to jointly train affine transformations of the countermeasure scores and the automatic speaker verification scores in such a way that the SASV LLR is optimized.
Challenging margin-based speaker embedding extractors by using the variational information bottleneck
Jun 18, 2024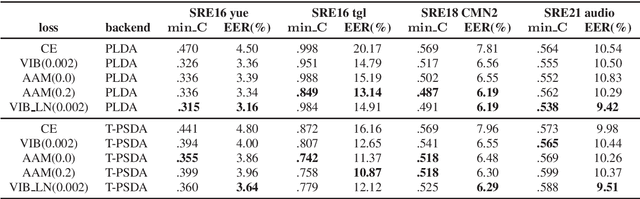
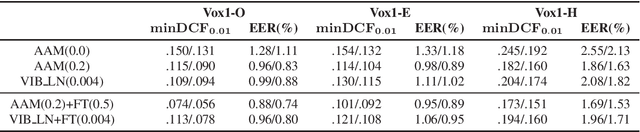
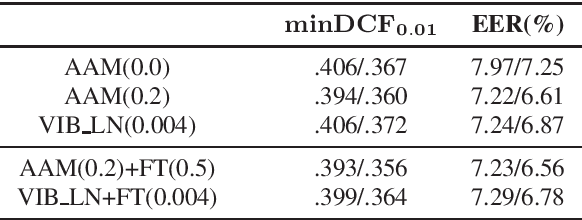
Speaker embedding extractors are typically trained using a classification loss over the training speakers. During the last few years, the standard softmax/cross-entropy loss has been replaced by the margin-based losses, yielding significant improvements in speaker recognition accuracy. Motivated by the fact that the margin merely reduces the logit of the target speaker during training, we consider a probabilistic framework that has a similar effect. The variational information bottleneck provides a principled mechanism for making deterministic nodes stochastic, resulting in an implicit reduction of the posterior of the target speaker. We experiment with a wide range of speaker recognition benchmarks and scoring methods and report competitive results to those obtained with the state-of-the-art Additive Angular Margin loss.
Comparing Data Augmentation Methods for End-to-End Task-Oriented Dialog Systems
Jun 10, 2024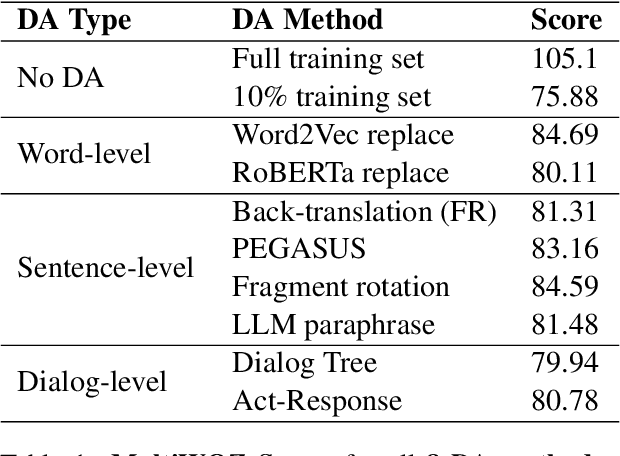
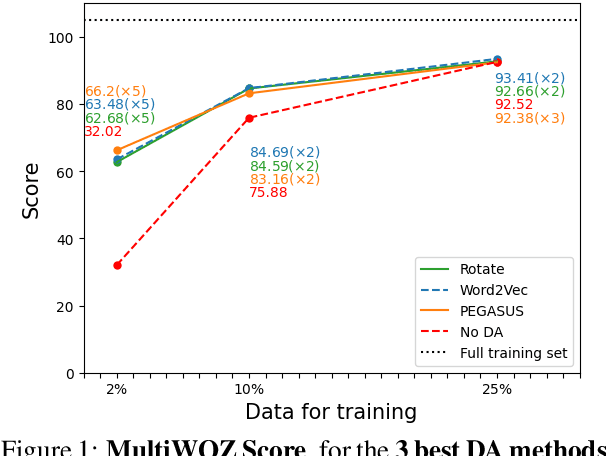
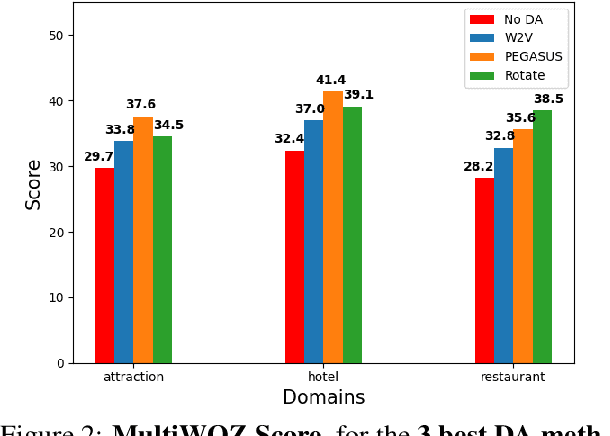

Creating effective and reliable task-oriented dialog systems (ToDSs) is challenging, not only because of the complex structure of these systems, but also due to the scarcity of training data, especially when several modules need to be trained separately, each one with its own input/output training examples. Data augmentation (DA), whereby synthetic training examples are added to the training data, has been successful in other NLP systems, but has not been explored as extensively in ToDSs. We empirically evaluate the effectiveness of DA methods in an end-to-end ToDS setting, where a single system is trained to handle all processing stages, from user inputs to system outputs. We experiment with two ToDSs (UBAR, GALAXY) on two datasets (MultiWOZ, KVRET). We consider three types of DA methods (word-level, sentence-level, dialog-level), comparing eight DA methods that have shown promising results in ToDSs and other NLP systems. We show that all DA methods considered are beneficial, and we highlight the best ones, also providing advice to practitioners. We also introduce a more challenging few-shot cross-domain ToDS setting, reaching similar conclusions.