 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeDefense: A Toolkit to Defend Against Fake Audio
Jan 21, 2026The advances in generative AI have enabled the creation of synthetic audio which is perceptually indistinguishable from real, genuine audio. Although this stellar progress enables many positive applications, it also raises risks of misuse, such as for impersonation, disinformation and fraud. Despite a growing number of open-source fake audio detection codes released through numerous challenges and initiatives, most are tailored to specific competitions, datasets or models. A standardized and unified toolkit that supports the fair benchmarking and comparison of competing solutions with not just common databases, protocols, metrics, but also a shared codebase, is missing. To address this, we propose WeDefense, the first open-source toolkit to support both fake audio detection and localization. Beyond model training, WeDefense emphasizes critical yet often overlooked components: flexible input and augmentation, calibration, score fusion, standardized evaluation metrics, and analysis tools for deeper understanding and interpretation. The toolkit is publicly available at https://github.com/zlin0/wedefense with interactive demos for fake audio detection and localization.
Fine-tune Before Structured Pruning: Towards Compact and Accurate Self-Supervised Models for Speaker Diarization
May 30, 2025
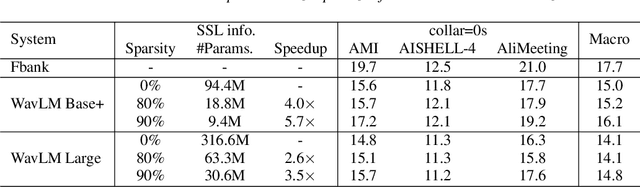


Self-supervised learning (SSL) models like WavLM can be effectively utilized when building speaker diarization systems but are often large and slow, limiting their use in resource constrained scenarios. Previous studies have explored compression techniques, but usually for the price of degraded performance at high pruning ratios. In this work, we propose to compress SSL models through structured pruning by introducing knowledge distillation. Different from the existing works, we emphasize the importance of fine-tuning SSL models before pruning. Experiments on far-field single-channel AMI, AISHELL-4, and AliMeeting datasets show that our method can remove redundant parameters of WavLM Base+ and WavLM Large by up to 80% without any performance degradation. After pruning, the inference speeds on a single GPU for the Base+ and Large models are 4.0 and 2.6 times faster, respectively. Our source code is publicly available.
Analysis of ABC Frontend Audio Systems for the NIST-SRE24
May 21, 2025We present a comprehensive analysis of the embedding extractors (frontends) developed by the ABC team for the audio track of NIST SRE 2024. We follow the two scenarios imposed by NIST: using only a provided set of telephone recordings for training (fixed) or adding publicly available data (open condition). Under these constraints, we develop the best possible speaker embedding extractors for the pre-dominant conversational telephone speech (CTS) domain. We explored architectures based on ResNet with different pooling mechanisms, recently introduced ReDimNet architecture, as well as a system based on the XLS-R model, which represents the family of large pre-trained self-supervised models. In open condition, we train on VoxBlink2 dataset, containing 110 thousand speakers across multiple languages. We observed a good performance and robustness of VoxBlink-trained models, and our experiments show practical recipes for developing state-of-the-art frontends for speaker recognition.
Joint Training of Speaker Embedding Extractor, Speech and Overlap Detection for Diarization
Nov 04, 2024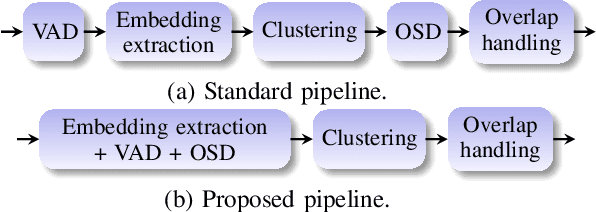
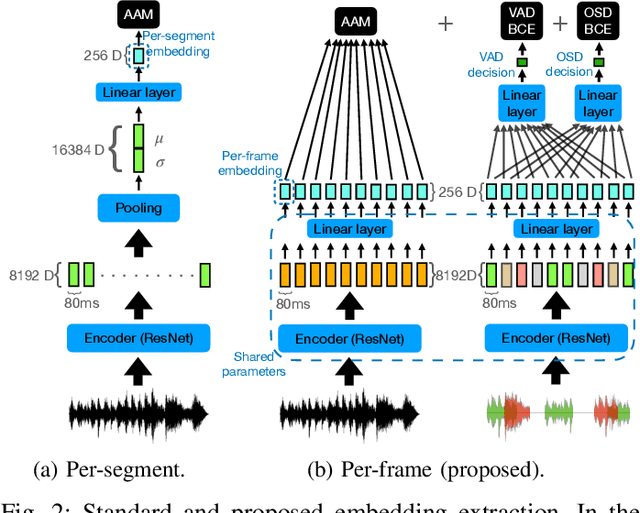
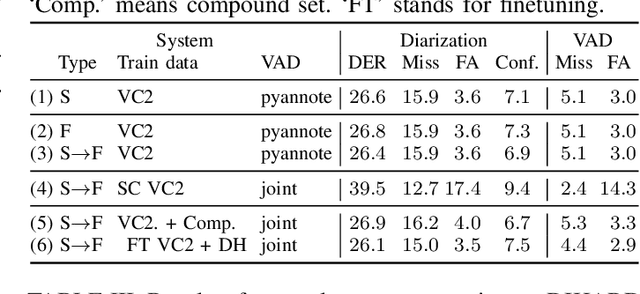
In spite of the popularity of end-to-end diarization systems nowadays, modular systems comprised of voice activity detection (VAD), speaker embedding extraction plus clustering, and overlapped speech detection (OSD) plus handling still attain competitive performance in many conditions. However, one of the main drawbacks of modular systems is the need to run (and train) different modules independently. In this work, we propose an approach to jointly train a model to produce speaker embeddings, VAD and OSD simultaneously and reach competitive performance at a fraction of the inference time of a standard approach. Furthermore, the joint inference leads to a simplified overall pipeline which brings us one step closer to a unified clustering-based method that can be trained end-to-end towards a diarization-specific objective.
Leveraging Self-Supervised Learning for Speaker Diarization
Sep 14, 2024



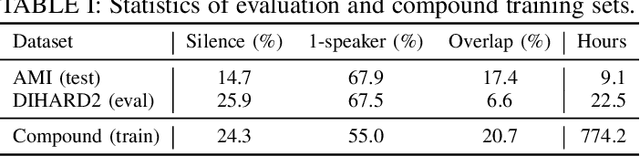
End-to-end neural diarization has evolved considerably over the past few years, but data scarcity is still a major obstacle for further improvements. Self-supervised learning methods such as WavLM have shown promising performance on several downstream tasks, but their application on speaker diarization is somehow limited. In this work, we explore using WavLM to alleviate the problem of data scarcity for neural diarization training. We use the same pipeline as Pyannote and improve the local end-to-end neural diarization with WavLM and Conformer. Experiments on far-field AMI, AISHELL-4, and AliMeeting datasets show that our method substantially outperforms the Pyannote baseline and achieves performance comparable to the state-of-the-art results on AMI and AISHELL-4. In addition, by analyzing the system performance under different data quantity scenarios, we show that WavLM representations are much more robust against data scarcity than filterbank features, enabling less data hungry training strategies. Furthermore, we found that simulated data, usually used to train endto-end diarization models, does not help when using WavLM in our experiments. Additionally, we also evaluate our model on the recent CHiME8 NOTSOFAR-1 task where it achieves better performance than the Pyannote baseline. Our source code is publicly available at https://github.com/BUTSpeechFIT/DiariZen.
BUT Systems and Analyses for the ASVspoof 5 Challenge
Aug 20, 2024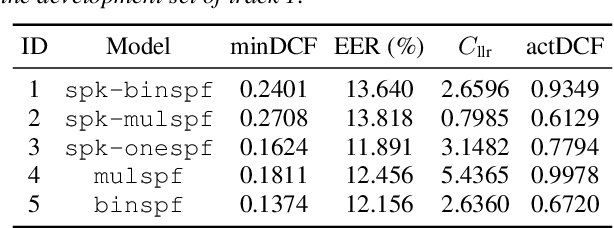
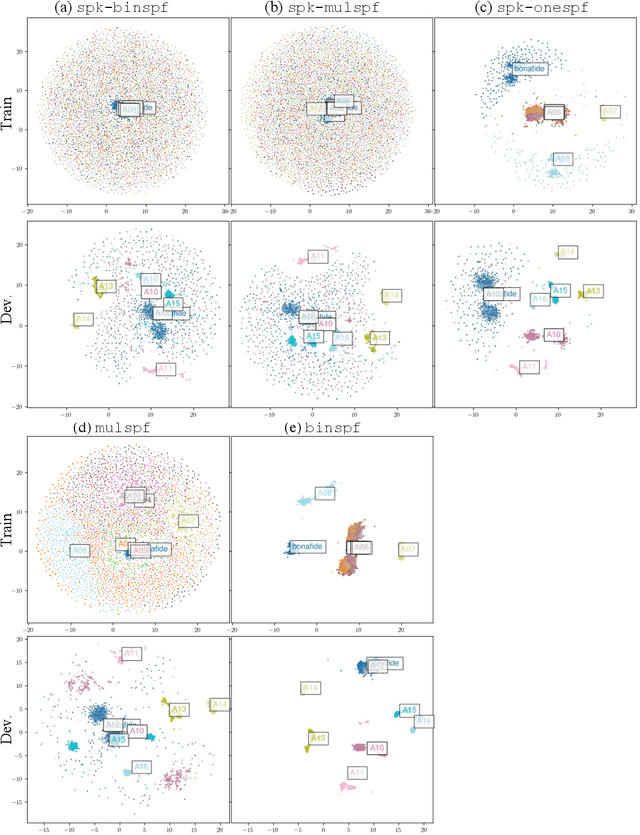
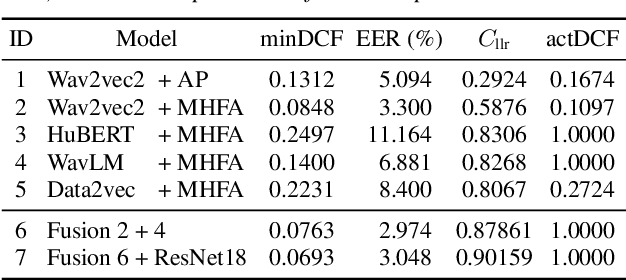

This paper describes the BUT submitted systems for the ASVspoof 5 challenge, along with analyses. For the conventional deepfake detection task, we use ResNet18 and self-supervised models for the closed and open conditions, respectively. In addition, we analyze and visualize different combinations of speaker information and spoofing information as label schemes for training. For spoofing-robust automatic speaker verification (SASV), we introduce effective priors and propose using logistic regression to jointly train affine transformations of the countermeasure scores and the automatic speaker verification scores in such a way that the SASV LLR is optimized.
Challenging margin-based speaker embedding extractors by using the variational information bottleneck
Jun 18, 2024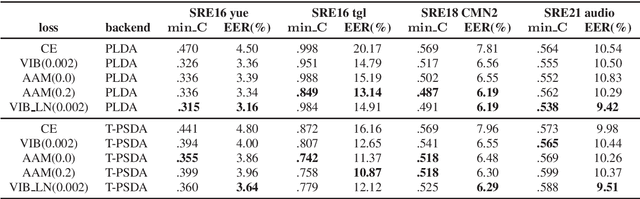
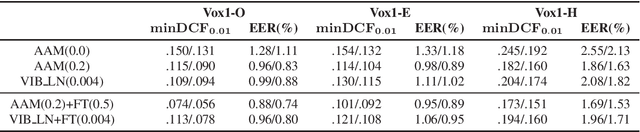
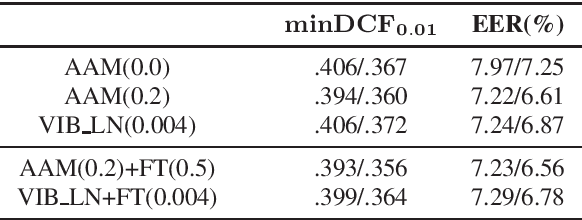
Speaker embedding extractors are typically trained using a classification loss over the training speakers. During the last few years, the standard softmax/cross-entropy loss has been replaced by the margin-based losses, yielding significant improvements in speaker recognition accuracy. Motivated by the fact that the margin merely reduces the logit of the target speaker during training, we consider a probabilistic framework that has a similar effect. The variational information bottleneck provides a principled mechanism for making deterministic nodes stochastic, resulting in an implicit reduction of the posterior of the target speaker. We experiment with a wide range of speaker recognition benchmarks and scoring methods and report competitive results to those obtained with the state-of-the-art Additive Angular Margin loss.
Do End-to-End Neural Diarization Attractors Need to Encode Speaker Characteristic Information?
Feb 29, 2024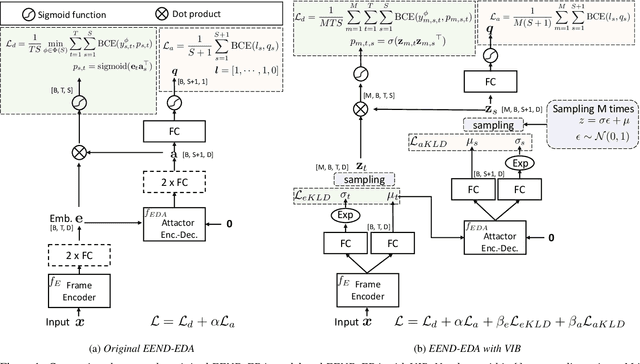

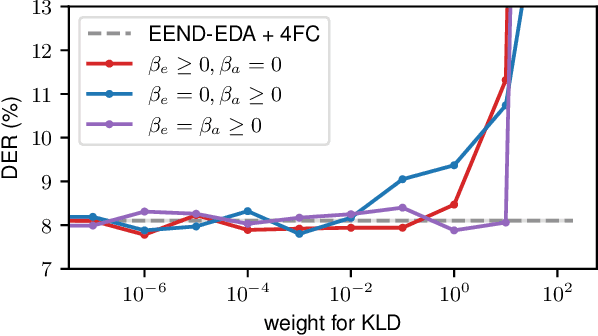

In this paper, we apply the variational information bottleneck approach to end-to-end neural diarization with encoder-decoder attractors (EEND-EDA). This allows us to investigate what information is essential for the model. EEND-EDA utilizes vector representations of the speakers in a conversation - attractors. Our analysis shows that, attractors do not necessarily have to contain speaker characteristic information. On the other hand, giving the attractors more freedom allowing them to encode some extra (possibly speaker-specific) information leads to small but consistent diarization performance improvements. Despite architectural differences in EEND systems, the notion of attractors and frame embeddings is common to most of them and not specific to EEND-EDA. We believe that the main conclusions of this work can apply to other variants of EEND. Thus, we hope this paper will be a valuable contribution to guide the community to make more informed decisions when designing new systems.
Discriminative Training of VBx Diarization
Oct 04, 2023


Bayesian HMM clustering of x-vector sequences (VBx) has become a widely adopted diarization baseline model in publications and challenges. It uses an HMM to model speaker turns, a generatively trained probabilistic linear discriminant analysis (PLDA) for speaker distribution modeling, and Bayesian inference to estimate the assignment of x-vectors to speakers. This paper presents a new framework for updating the VBx parameters using discriminative training, which directly optimizes a predefined loss. We also propose a new loss that better correlates with the diarization error rate compared to binary cross-entropy $\unicode{x2013}$ the default choice for diarization end-to-end systems. Proof-of-concept results across three datasets (AMI, CALLHOME, and DIHARD II) demonstrate the method's capability of automatically finding hyperparameters, achieving comparable performance to those found by extensive grid search, which typically requires additional hyperparameter behavior knowledge. Moreover, we show that discriminative fine-tuning of PLDA can further improve the model's performance. We release the source code with this publication.
Multi-Stream Extension of Variational Bayesian HMM Clustering (MS-VBx) for Combined End-to-End and Vector Clustering-based Diarization
May 23, 2023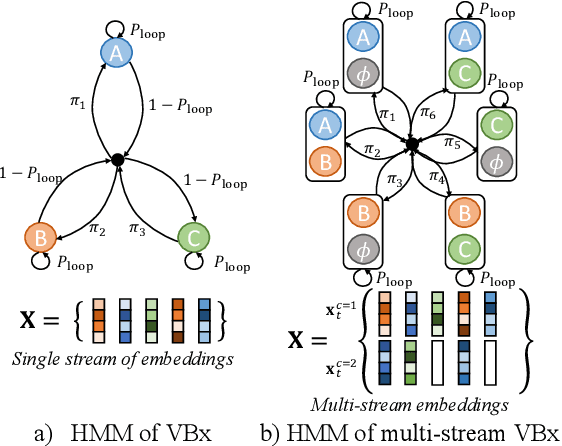
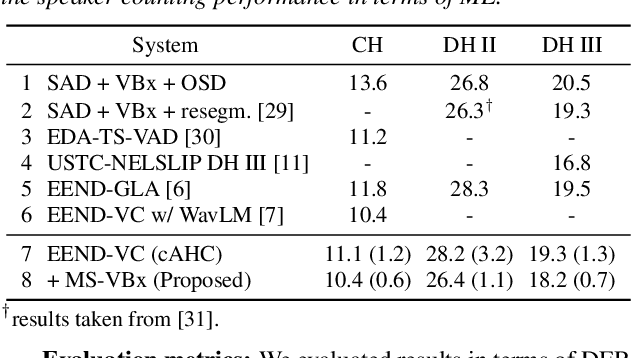
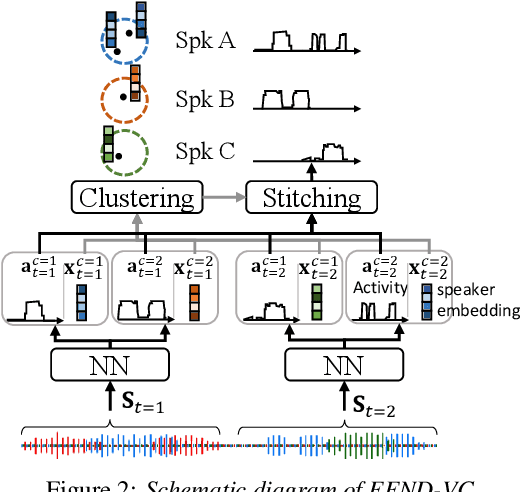
Combining end-to-end neural speaker diarization (EEND) with vector clustering (VC), known as EEND-VC, has gained interest for leveraging the strengths of both methods. EEND-VC estimates activities and speaker embeddings for all speakers within an audio chunk and uses VC to associate these activities with speaker identities across different chunks. EEND-VC generates thus multiple streams of embeddings, one for each speaker in a chunk. We can cluster these embeddings using constrained agglomerative hierarchical clustering (cAHC), ensuring embeddings from the same chunk belong to different clusters. This paper introduces an alternative clustering approach, a multi-stream extension of the successful Bayesian HMM clustering of x-vectors (VBx), called MS-VBx. Experiments on three datasets demonstrate that MS-VBx outperforms cAHC in diarization and speaker counting performance.