 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAll-in-One ASR: Unifying Encoder-Decoder Models of CTC, Attention, and Transducer in Dual-Mode ASR
Dec 12, 2025This paper proposes a unified framework, All-in-One ASR, that allows a single model to support multiple automatic speech recognition (ASR) paradigms, including connectionist temporal classification (CTC), attention-based encoder-decoder (AED), and Transducer, in both offline and streaming modes. While each ASR architecture offers distinct advantages and trade-offs depending on the application, maintaining separate models for each scenario incurs substantial development and deployment costs. To address this issue, we introduce a multi-mode joiner that enables seamless integration of various ASR modes within a single unified model. Experiments show that All-in-One ASR significantly reduces the total model footprint while matching or even surpassing the recognition performance of individually optimized ASR models. Furthermore, joint decoding leverages the complementary strengths of different ASR modes, yielding additional improvements in recognition accuracy.
NTT Multi-Speaker ASR System for the DASR Task of CHiME-8 Challenge
Sep 09, 2024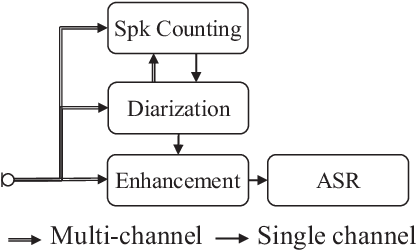
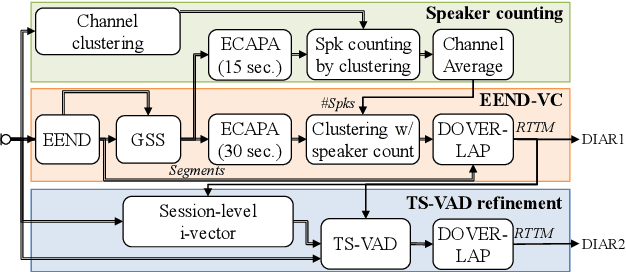

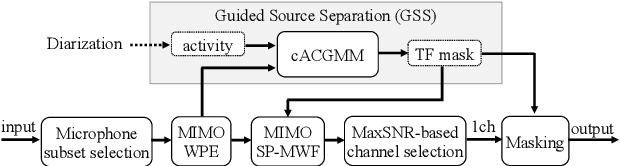
We present a distant automatic speech recognition (DASR) system developed for the CHiME-8 DASR track. It consists of a diarization first pipeline. For diarization, we use end-to-end diarization with vector clustering (EEND-VC) followed by target speaker voice activity detection (TS-VAD) refinement. To deal with various numbers of speakers, we developed a new multi-channel speaker counting approach. We then apply guided source separation (GSS) with several improvements to the baseline system. Finally, we perform ASR using a combination of systems built from strong pre-trained models. Our proposed system achieves a macro tcpWER of 21.3 % on the dev set, which is a 57 % relative improvement over the baseline.
Sentence-wise Speech Summarization: Task, Datasets, and End-to-End Modeling with LM Knowledge Distillation
Aug 01, 2024



This paper introduces a novel approach called sentence-wise speech summarization (Sen-SSum), which generates text summaries from a spoken document in a sentence-by-sentence manner. Sen-SSum combines the real-time processing of automatic speech recognition (ASR) with the conciseness of speech summarization. To explore this approach, we present two datasets for Sen-SSum: Mega-SSum and CSJ-SSum. Using these datasets, our study evaluates two types of Transformer-based models: 1) cascade models that combine ASR and strong text summarization models, and 2) end-to-end (E2E) models that directly convert speech into a text summary. While E2E models are appealing to develop compute-efficient models, they perform worse than cascade models. Therefore, we propose knowledge distillation for E2E models using pseudo-summaries generated by the cascade models. Our experiments show that this proposed knowledge distillation effectively improves the performance of the E2E model on both datasets.
Applying LLMs for Rescoring N-best ASR Hypotheses of Casual Conversations: Effects of Domain Adaptation and Context Carry-over
Jun 27, 2024Large language models (LLMs) have been successfully applied for rescoring automatic speech recognition (ASR) hypotheses. However, their ability to rescore ASR hypotheses of casual conversations has not been sufficiently explored. In this study, we reveal it by performing N-best ASR hypotheses rescoring using Llama2 on the CHiME-7 distant ASR (DASR) task. Llama2 is one of the most representative LLMs, and the CHiME-7 DASR task provides datasets of casual conversations between multiple participants. We investigate the effects of domain adaptation of the LLM and context carry-over when performing N-best rescoring. Experimental results show that, even without domain adaptation, Llama2 outperforms a standard-size domain-adapted Transformer-LM, especially when using a long context. Domain adaptation shortens the context length needed with Llama2 to achieve its best performance, i.e., it reduces the computational cost of Llama2.
BLSTM-Based Confidence Estimation for End-to-End Speech Recognition
Dec 22, 2023Confidence estimation, in which we estimate the reliability of each recognized token (e.g., word, sub-word, and character) in automatic speech recognition (ASR) hypotheses and detect incorrectly recognized tokens, is an important function for developing ASR applications. In this study, we perform confidence estimation for end-to-end (E2E) ASR hypotheses. Recent E2E ASR systems show high performance (e.g., around 5% token error rates) for various ASR tasks. In such situations, confidence estimation becomes difficult since we need to detect infrequent incorrect tokens from mostly correct token sequences. To tackle this imbalanced dataset problem, we employ a bidirectional long short-term memory (BLSTM)-based model as a strong binary-class (correct/incorrect) sequence labeler that is trained with a class balancing objective. We experimentally confirmed that, by utilizing several types of ASR decoding scores as its auxiliary features, the model steadily shows high confidence estimation performance under highly imbalanced settings. We also confirmed that the BLSTM-based model outperforms Transformer-based confidence estimation models, which greatly underestimate incorrect tokens.
Lattice Rescoring Based on Large Ensemble of Complementary Neural Language Models
Dec 20, 2023We investigate the effectiveness of using a large ensemble of advanced neural language models (NLMs) for lattice rescoring on automatic speech recognition (ASR) hypotheses. Previous studies have reported the effectiveness of combining a small number of NLMs. In contrast, in this study, we combine up to eight NLMs, i.e., forward/backward long short-term memory/Transformer-LMs that are trained with two different random initialization seeds. We combine these NLMs through iterative lattice generation. Since these NLMs work complementarily with each other, by combining them one by one at each rescoring iteration, language scores attached to given lattice arcs can be gradually refined. Consequently, errors of the ASR hypotheses can be gradually reduced. We also investigate the effectiveness of carrying over contextual information (previous rescoring results) across a lattice sequence of a long speech such as a lecture speech. In experiments using a lecture speech corpus, by combining the eight NLMs and using context carry-over, we obtained a 24.4% relative word error rate reduction from the ASR 1-best baseline. For further comparison, we performed simultaneous (i.e., non-iterative) NLM combination and 100-best rescoring using the large ensemble of NLMs, which confirmed the advantage of lattice rescoring with iterative NLM combination.
Iterative Shallow Fusion of Backward Language Model for End-to-End Speech Recognition
Oct 17, 2023We propose a new shallow fusion (SF) method to exploit an external backward language model (BLM) for end-to-end automatic speech recognition (ASR). The BLM has complementary characteristics with a forward language model (FLM), and the effectiveness of their combination has been confirmed by rescoring ASR hypotheses as post-processing. In the proposed SF, we iteratively apply the BLM to partial ASR hypotheses in the backward direction (i.e., from the possible next token to the start symbol) during decoding, substituting the newly calculated BLM scores for the scores calculated at the last iteration. To enhance the effectiveness of this iterative SF (ISF), we train a partial sentence-aware BLM (PBLM) using reversed text data including partial sentences, considering the framework of ISF. In experiments using an attention-based encoder-decoder ASR system, we confirmed that ISF using the PBLM shows comparable performance with SF using the FLM. By performing ISF, early pruning of prospective hypotheses can be prevented during decoding, and we can obtain a performance improvement compared to applying the PBLM as post-processing. Finally, we confirmed that, by combining SF and ISF, further performance improvement can be obtained thanks to the complementarity of the FLM and PBLM.
NTT speaker diarization system for CHiME-7: multi-domain, multi-microphone End-to-end and vector clustering diarization
Sep 22, 2023This paper details our speaker diarization system designed for multi-domain, multi-microphone casual conversations. The proposed diarization pipeline uses weighted prediction error (WPE)-based dereverberation as a front end, then applies end-to-end neural diarization with vector clustering (EEND-VC) to each channel separately. It integrates the diarization result obtained from each channel using diarization output voting error reduction plus overlap (DOVER-LAP). To harness the knowledge from the target domain and results integrated across all channels, we apply self-supervised adaptation for each session by retraining the EEND-VC with pseudo-labels derived from DOVER-LAP. The proposed system was incorporated into NTT's submission for the distant automatic speech recognition task in the CHiME-7 challenge. Our system achieved 65 % and 62 % relative improvements on development and eval sets compared to the organizer-provided VC-based baseline diarization system, securing third place in diarization performance.
Transfer Learning from Pre-trained Language Models Improves End-to-End Speech Summarization
Jun 07, 2023End-to-end speech summarization (E2E SSum) directly summarizes input speech into easy-to-read short sentences with a single model. This approach is promising because it, in contrast to the conventional cascade approach, can utilize full acoustical information and mitigate to the propagation of transcription errors. However, due to the high cost of collecting speech-summary pairs, an E2E SSum model tends to suffer from training data scarcity and output unnatural sentences. To overcome this drawback, we propose for the first time to integrate a pre-trained language model (LM), which is highly capable of generating natural sentences, into the E2E SSum decoder via transfer learning. In addition, to reduce the gap between the independently pre-trained encoder and decoder, we also propose to transfer the baseline E2E SSum encoder instead of the commonly used automatic speech recognition encoder. Experimental results show that the proposed model outperforms baseline and data augmented models.
Knowledge Distillation for Neural Transducer-based Target-Speaker ASR: Exploiting Parallel Mixture/Single-Talker Speech Data
May 25, 2023Neural transducer (RNNT)-based target-speaker speech recognition (TS-RNNT) directly transcribes a target speaker's voice from a multi-talker mixture. It is a promising approach for streaming applications because it does not incur the extra computation costs of a target speech extraction frontend, which is a critical barrier to quick response. TS-RNNT is trained end-to-end given the input speech (i.e., mixtures and enrollment speech) and reference transcriptions. The training mixtures are generally simulated by mixing single-talker signals, but conventional TS-RNNT training does not utilize single-speaker signals. This paper proposes using knowledge distillation (KD) to exploit the parallel mixture/single-talker speech data. Our proposed KD scheme uses an RNNT system pretrained with the target single-talker speech input to generate pseudo labels for the TS-RNNT training. Experimental results show that TS-RNNT systems trained with the proposed KD scheme outperform a baseline TS-RNNT.