 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisualizing Latent Phase Structures in Locomotion Policies: A Multi-Environment Study with Temporal Feature Extension
May 27, 2026Deep reinforcement learning (DRL) has been shown to achieve high performance on locomotion control tasks in MuJoCo benchmarks such as HalfCheetah, Ant, and Walker2D. However, visualizing the motion structures internally obtained by a trained policy function implemented as a deep neural network remains challenging. It is known from biomechanics and related fields that locomotion control is realized through the repetition of motion phases such as the stance phase and swing phase. In this study, we propose a framework for uncovering latent motion phase structures from trajectories generated by locomotion control policies through interaction with the environment. The proposed method extends the clustering features from state observations alone to augmented features including actions, next states, and next actions, and introduces a method for determining the number of clusters that suppresses self-transitions. Applying the proposed method to three environments -- Ant-v5, HalfCheetah-v5, and Walker2D-v5 -- we successfully identified phase structures with clearer and more regular transition rules than those obtained by the existing method.
Uncovering Latent Phase Structures and Branching Logic in Locomotion Policies: A Case Study on HalfCheetah
Mar 18, 2026In locomotion control tasks, Deep Reinforcement Learning (DRL) has demonstrated high performance; however, the decision-making process of the learned policy remains a black box, making it difficult for humans to understand. On the other hand, in periodic motions such as walking, it is well known that implicit motion phases exist, such as the stance phase and the swing phase. Focusing on this point, this study hypothesizes that a policy trained for locomotion control may also represent a phase structure that is interpretable by humans. To examine this hypothesis in a controlled setting, we consider a locomotion task that is amenable to observing whether a policy autonomously acquires temporally structured phases through interaction with the environment. To verify this hypothesis, in the MuJoCo locomotion benchmark HalfCheetah-v5, the state transition sequences acquired by a policy trained for walking control through interaction with the environment were aggregated into semantic phases based on state similarity and consistency of subsequent transitions. As a result, we demonstrated that the state sequences generated by the trained policy exhibit periodic phase transition structures as well as phase branching. Furthermore, by approximating the states and actions corresponding to each semantic phase using Explainable Boosting Machines (EBMs), we analyzed phase-dependent decision making-namely, which state features the policy function attends to and how it controls action outputs in each phase. These results suggest that neural network-based policies, which are often regarded as black boxes, can autonomously acquire interpretable phase structures and logical branching mechanisms.
Force Generative Imitation Learning: Bridging Position Trajectory and Force Commands through Control Technique
Feb 06, 2026In contact-rich tasks, while position trajectories are often easy to obtain, appropriate force commands are typically unknown. Although it is conceivable to generate force commands using a pretrained foundation model such as Vision-Language-Action (VLA) models, force control is highly dependent on the specific hardware of the robot, which makes the application of such models challenging. To bridge this gap, we propose a force generative model that estimates force commands from given position trajectories. However, when dealing with unseen position trajectories, the model struggles to generate accurate force commands. To address this, we introduce a feedback control mechanism. Our experiments reveal that feedback control does not converge when the force generative model has memory. We therefore adopt a model without memory, enabling stable feedback control. This approach allows the system to generate force commands effectively, even for unseen position trajectories, improving generalization for real-world robot writing tasks.
All-in-One ASR: Unifying Encoder-Decoder Models of CTC, Attention, and Transducer in Dual-Mode ASR
Dec 12, 2025This paper proposes a unified framework, All-in-One ASR, that allows a single model to support multiple automatic speech recognition (ASR) paradigms, including connectionist temporal classification (CTC), attention-based encoder-decoder (AED), and Transducer, in both offline and streaming modes. While each ASR architecture offers distinct advantages and trade-offs depending on the application, maintaining separate models for each scenario incurs substantial development and deployment costs. To address this issue, we introduce a multi-mode joiner that enables seamless integration of various ASR modes within a single unified model. Experiments show that All-in-One ASR significantly reduces the total model footprint while matching or even surpassing the recognition performance of individually optimized ASR models. Furthermore, joint decoding leverages the complementary strengths of different ASR modes, yielding additional improvements in recognition accuracy.
Accuracy-Preserving CNN Pruning Method under Limited Data Availability
Nov 13, 2025Convolutional Neural Networks (CNNs) are widely used in image recognition and have succeeded in various domains. CNN models have become larger-scale to improve accuracy and generalization performance. Research has been conducted on compressing pre-trained models for specific target applications in environments with limited computing resources. Among model compression techniques, methods using Layer-wise Relevance Propagation (LRP), an explainable AI technique, have shown promise by achieving high pruning rates while preserving accuracy, even without fine-tuning. Because these methods do not require fine-tuning, they are suited to scenarios with limited data. However, existing LRP-based pruning approaches still suffer from significant accuracy degradation, limiting their practical usability. This study proposes a pruning method that achieves a higher pruning rate while preserving better model accuracy. Our approach to pruning with a small amount of data has achieved pruning that preserves accuracy better than existing methods.
Generic Speech Enhancement with Self-Supervised Representation Space Loss
Jul 10, 2025


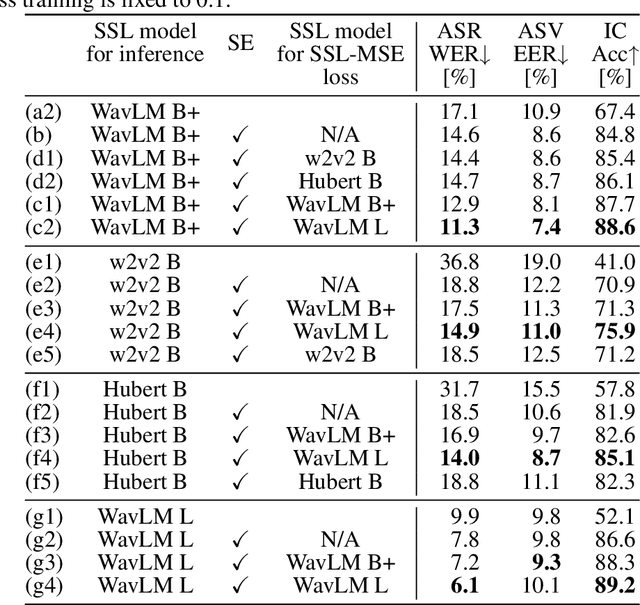
Single-channel speech enhancement is utilized in various tasks to mitigate the effect of interfering signals. Conventionally, to ensure the speech enhancement performs optimally, the speech enhancement has needed to be tuned for each task. Thus, generalizing speech enhancement models to unknown downstream tasks has been challenging. This study aims to construct a generic speech enhancement front-end that can improve the performance of back-ends to solve multiple downstream tasks. To this end, we propose a novel training criterion that minimizes the distance between the enhanced and the ground truth clean signal in the feature representation domain of self-supervised learning models. Since self-supervised learning feature representations effectively express high-level speech information useful for solving various downstream tasks, the proposal is expected to make speech enhancement models preserve such information. Experimental validation demonstrates that the proposal improves the performance of multiple speech tasks while maintaining the perceptual quality of the enhanced signal.
* 22 pages, 3 figures. Accepted for Frontiers in signal processing
Motion Generation for Food Topping Challenge 2024: Serving Salmon Roe Bowl and Picking Fried Chicken
Apr 30, 2025
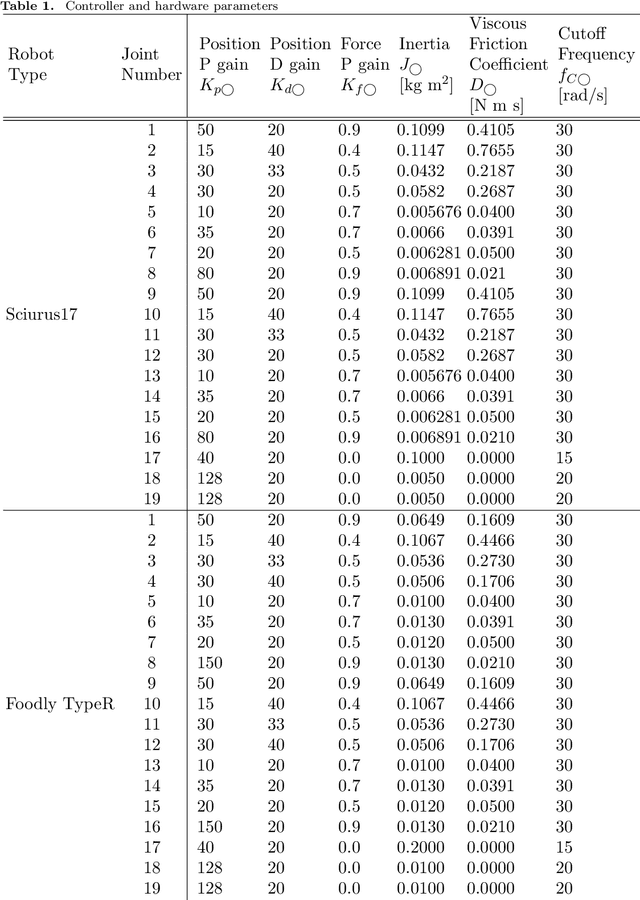

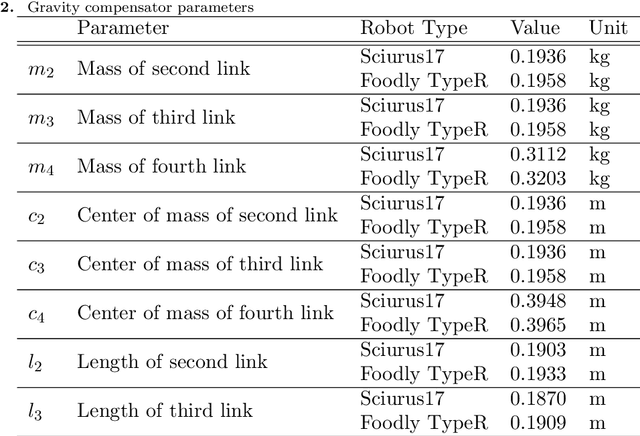
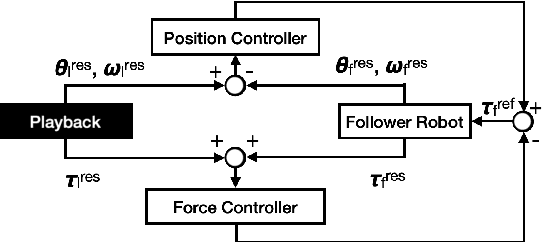
Although robots have been introduced in many industries, food production robots are yet to be widely employed because the food industry requires not only delicate movements to handle food but also complex movements that adapt to the environment. Force control is important for handling delicate objects such as food. In addition, achieving complex movements is possible by making robot motions based on human teachings. Four-channel bilateral control is proposed, which enables the simultaneous teaching of position and force information. Moreover, methods have been developed to reproduce motions obtained through human teachings and generate adaptive motions using learning. We demonstrated the effectiveness of these methods for food handling tasks in the Food Topping Challenge at the 2024 IEEE International Conference on Robotics and Automation (ICRA 2024). For the task of serving salmon roe on rice, we achieved the best performance because of the high reproducibility and quick motion of the proposed method. Further, for the task of picking fried chicken, we successfully picked the most pieces of fried chicken among all participating teams. This paper describes the implementation and performance of these methods.
Variable-Speed Teaching-Playback as Real-World Data Augmentation for Imitation Learning
Dec 04, 2024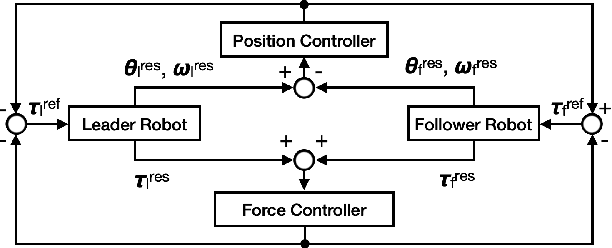


Because imitation learning relies on human demonstrations in hard-to-simulate settings, the inclusion of force control in this method has resulted in a shortage of training data, even with a simple change in speed. Although the field of data augmentation has addressed the lack of data, conventional methods of data augmentation for robot manipulation are limited to simulation-based methods or downsampling for position control. This paper proposes a novel method of data augmentation that is applicable to force control and preserves the advantages of real-world datasets. We applied teaching-playback at variable speeds as real-world data augmentation to increase both the quantity and quality of environmental reactions at variable speeds. An experiment was conducted on bilateral control-based imitation learning using a method of imitation learning equipped with position-force control. We evaluated the effect of real-world data augmentation on two tasks, pick-and-place and wiping, at variable speeds, each from two human demonstrations at fixed speed. The results showed a maximum 55% increase in success rate from a simple change in speed of real-world reactions and improved accuracy along the duration/frequency command by gathering environmental reactions at variable speeds.
Error-Feedback Model for Output Correction in Bilateral Control-Based Imitation Learning
Nov 19, 2024In recent years, imitation learning using neural networks has enabled robots to perform flexible tasks. However, since neural networks operate in a feedforward structure, they do not possess a mechanism to compensate for output errors. To address this limitation, we developed a feedback mechanism to correct these errors. By employing a hierarchical structure for neural networks comprising lower and upper layers, the lower layer was controlled to follow the upper layer. Additionally, using a multi-layer perceptron in the lower layer, which lacks an internal state, enhanced the error feedback. In the character-writing task, this model demonstrated improved accuracy in writing previously untrained characters. In the character-writing task, this model demonstrated improved accuracy in writing previously untrained characters. Through autonomous control with error feedback, we confirmed that the lower layer could effectively track the output of the upper layer. This study represents a promising step toward integrating neural networks with control theories.
Guided Speaker Embedding
Oct 16, 2024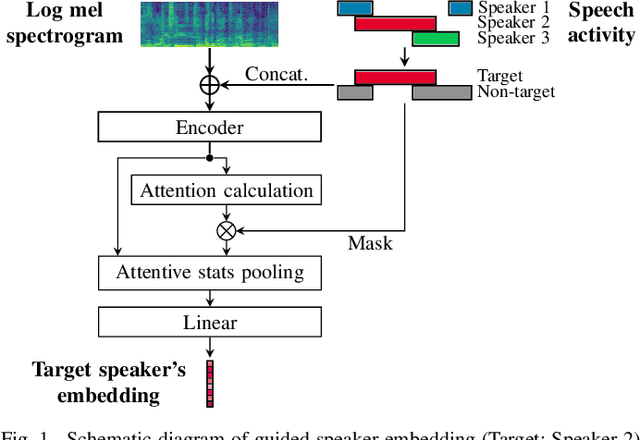

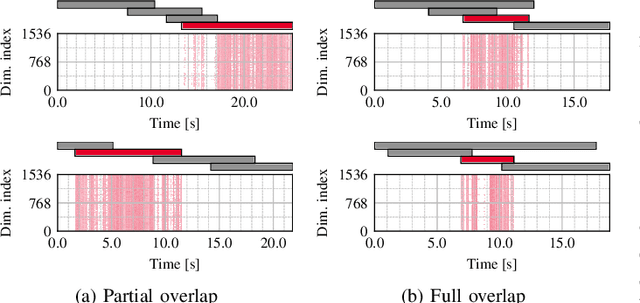

This paper proposes a guided speaker embedding extraction system, which extracts speaker embeddings of the target speaker using speech activities of target and interference speakers as clues. Several methods for long-form overlapped multi-speaker audio processing are typically two-staged: i) segment-level processing and ii) inter-segment speaker matching. Speaker embeddings are often used for the latter purpose. Typical speaker embedding extraction approaches only use single-speaker intervals to avoid corrupting the embeddings with speech from interference speakers. However, this often makes speaker embeddings impossible to extract because sufficiently long non-overlapping intervals are not always available. In this paper, we propose using speaker activities as clues to extract the embedding of the speaker-of-interest directly from overlapping speech. Specifically, we concatenate the activity of target and non-target speakers to acoustic features before being fed to the model. We also condition the attention weights used for pooling so that the attention weights of the intervals in which the target speaker is inactive are zero. The effectiveness of the proposed method is demonstrated in speaker verification and speaker diarization.