 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAll-in-One ASR: Unifying Encoder-Decoder Models of CTC, Attention, and Transducer in Dual-Mode ASR
Dec 12, 2025This paper proposes a unified framework, All-in-One ASR, that allows a single model to support multiple automatic speech recognition (ASR) paradigms, including connectionist temporal classification (CTC), attention-based encoder-decoder (AED), and Transducer, in both offline and streaming modes. While each ASR architecture offers distinct advantages and trade-offs depending on the application, maintaining separate models for each scenario incurs substantial development and deployment costs. To address this issue, we introduce a multi-mode joiner that enables seamless integration of various ASR modes within a single unified model. Experiments show that All-in-One ASR significantly reduces the total model footprint while matching or even surpassing the recognition performance of individually optimized ASR models. Furthermore, joint decoding leverages the complementary strengths of different ASR modes, yielding additional improvements in recognition accuracy.
Difference Vector Equalization for Robust Fine-tuning of Vision-Language Models
Nov 13, 2025



Contrastive pre-trained vision-language models, such as CLIP, demonstrate strong generalization abilities in zero-shot classification by leveraging embeddings extracted from image and text encoders. This paper aims to robustly fine-tune these vision-language models on in-distribution (ID) data without compromising their generalization abilities in out-of-distribution (OOD) and zero-shot settings. Current robust fine-tuning methods tackle this challenge by reusing contrastive learning, which was used in pre-training, for fine-tuning. However, we found that these methods distort the geometric structure of the embeddings, which plays a crucial role in the generalization of vision-language models, resulting in limited OOD and zero-shot performance. To address this, we propose Difference Vector Equalization (DiVE), which preserves the geometric structure during fine-tuning. The idea behind DiVE is to constrain difference vectors, each of which is obtained by subtracting the embeddings extracted from the pre-trained and fine-tuning models for the same data sample. By constraining the difference vectors to be equal across various data samples, we effectively preserve the geometric structure. Therefore, we introduce two losses: average vector loss (AVL) and pairwise vector loss (PVL). AVL preserves the geometric structure globally by constraining difference vectors to be equal to their weighted average. PVL preserves the geometric structure locally by ensuring a consistent multimodal alignment. Our experiments demonstrate that DiVE effectively preserves the geometric structure, achieving strong results across ID, OOD, and zero-shot metrics.
Joint Modeling of Big Five and HEXACO for Multimodal Apparent Personality-trait Recognition
Oct 16, 2025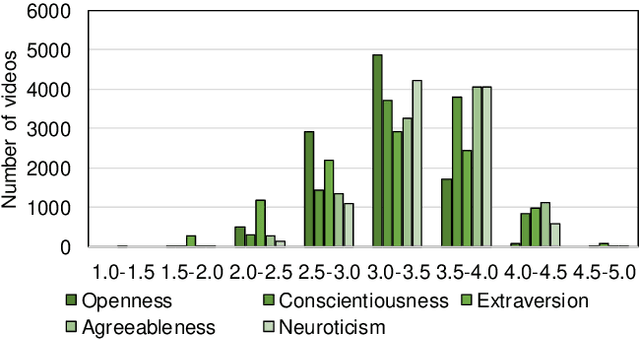



This paper proposes a joint modeling method of the Big Five, which has long been studied, and HEXACO, which has recently attracted attention in psychology, for automatically recognizing apparent personality traits from multimodal human behavior. Most previous studies have used the Big Five for multimodal apparent personality-trait recognition. However, no study has focused on apparent HEXACO which can evaluate an Honesty-Humility trait related to displaced aggression and vengefulness, social-dominance orientation, etc. In addition, the relationships between the Big Five and HEXACO when modeled by machine learning have not been clarified. We expect awareness of multimodal human behavior to improve by considering these relationships. The key advance of our proposed method is to optimize jointly recognizing the Big Five and HEXACO. Experiments using a self-introduction video dataset demonstrate that the proposed method can effectively recognize the Big Five and HEXACO.
Few-shot Personalization via In-Context Learning for Speech Emotion Recognition based on Speech-Language Model
Sep 10, 2025


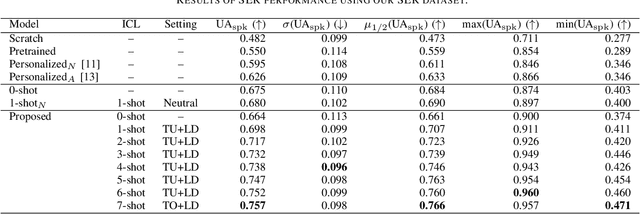
This paper proposes a personalization method for speech emotion recognition (SER) through in-context learning (ICL). Since the expression of emotions varies from person to person, speaker-specific adaptation is crucial for improving the SER performance. Conventional SER methods have been personalized using emotional utterances of a target speaker, but it is often difficult to prepare utterances corresponding to all emotion labels in advance. Our idea to overcome this difficulty is to obtain speaker characteristics by conditioning a few emotional utterances of the target speaker in ICL-based inference. ICL is a method to perform unseen tasks by conditioning a few input-output examples through inference in large language models (LLMs). We meta-train a speech-language model extended from the LLM to learn how to perform personalized SER via ICL. Experimental results using our newly collected SER dataset demonstrate that the proposed method outperforms conventional methods.
Generic Speech Enhancement with Self-Supervised Representation Space Loss
Jul 10, 2025


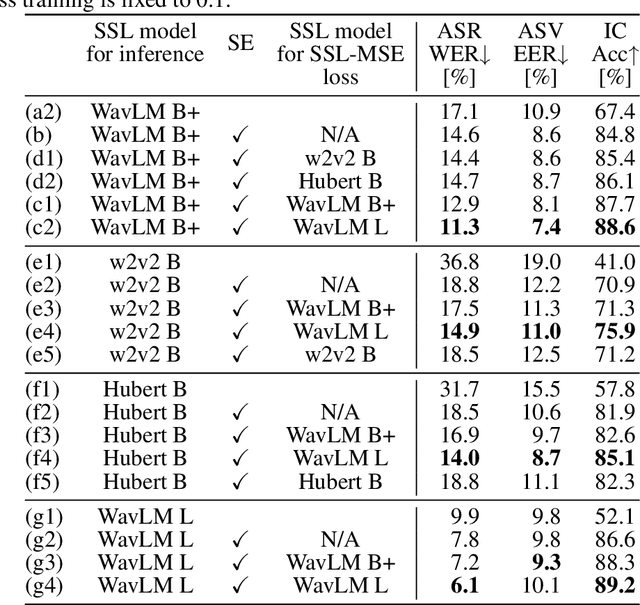
Single-channel speech enhancement is utilized in various tasks to mitigate the effect of interfering signals. Conventionally, to ensure the speech enhancement performs optimally, the speech enhancement has needed to be tuned for each task. Thus, generalizing speech enhancement models to unknown downstream tasks has been challenging. This study aims to construct a generic speech enhancement front-end that can improve the performance of back-ends to solve multiple downstream tasks. To this end, we propose a novel training criterion that minimizes the distance between the enhanced and the ground truth clean signal in the feature representation domain of self-supervised learning models. Since self-supervised learning feature representations effectively express high-level speech information useful for solving various downstream tasks, the proposal is expected to make speech enhancement models preserve such information. Experimental validation demonstrates that the proposal improves the performance of multiple speech tasks while maintaining the perceptual quality of the enhanced signal.
* 22 pages, 3 figures. Accepted for Frontiers in signal processing
ToMATO: Verbalizing the Mental States of Role-Playing LLMs for Benchmarking Theory of Mind
Jan 15, 2025



Existing Theory of Mind (ToM) benchmarks diverge from real-world scenarios in three aspects: 1) they assess a limited range of mental states such as beliefs, 2) false beliefs are not comprehensively explored, and 3) the diverse personality traits of characters are overlooked. To address these challenges, we introduce ToMATO, a new ToM benchmark formulated as multiple-choice QA over conversations. ToMATO is generated via LLM-LLM conversations featuring information asymmetry. By employing a prompting method that requires role-playing LLMs to verbalize their thoughts before each utterance, we capture both first- and second-order mental states across five categories: belief, intention, desire, emotion, and knowledge. These verbalized thoughts serve as answers to questions designed to assess the mental states of characters within conversations. Furthermore, the information asymmetry introduced by hiding thoughts from others induces the generation of false beliefs about various mental states. Assigning distinct personality traits to LLMs further diversifies both utterances and thoughts. ToMATO consists of 5.4k questions, 753 conversations, and 15 personality trait patterns. Our analysis shows that this dataset construction approach frequently generates false beliefs due to the information asymmetry between role-playing LLMs, and effectively reflects diverse personalities. We evaluate nine LLMs on ToMATO and find that even GPT-4o mini lags behind human performance, especially in understanding false beliefs, and lacks robustness to various personality traits.
Alignment-Free Training for Transducer-based Multi-Talker ASR
Sep 30, 2024

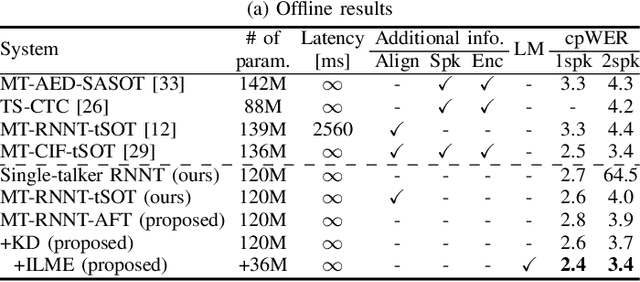
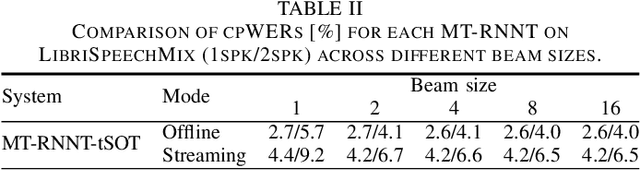
Extending the RNN Transducer (RNNT) to recognize multi-talker speech is essential for wider automatic speech recognition (ASR) applications. Multi-talker RNNT (MT-RNNT) aims to achieve recognition without relying on costly front-end source separation. MT-RNNT is conventionally implemented using architectures with multiple encoders or decoders, or by serializing all speakers' transcriptions into a single output stream. The first approach is computationally expensive, particularly due to the need for multiple encoder processing. In contrast, the second approach involves a complex label generation process, requiring accurate timestamps of all words spoken by all speakers in the mixture, obtained from an external ASR system. In this paper, we propose a novel alignment-free training scheme for the MT-RNNT (MT-RNNT-AFT) that adopts the standard RNNT architecture. The target labels are created by appending a prompt token corresponding to each speaker at the beginning of the transcription, reflecting the order of each speaker's appearance in the mixtures. Thus, MT-RNNT-AFT can be trained without relying on accurate alignments, and it can recognize all speakers' speech with just one round of encoder processing. Experiments show that MT-RNNT-AFT achieves performance comparable to that of the state-of-the-art alternatives, while greatly simplifying the training process.
Boosting Hybrid Autoregressive Transducer-based ASR with Internal Acoustic Model Training and Dual Blank Thresholding
Sep 30, 2024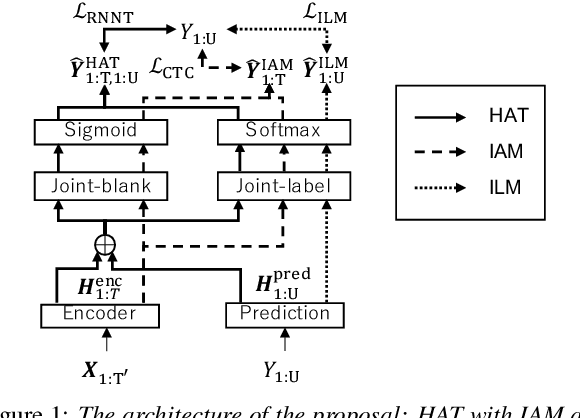
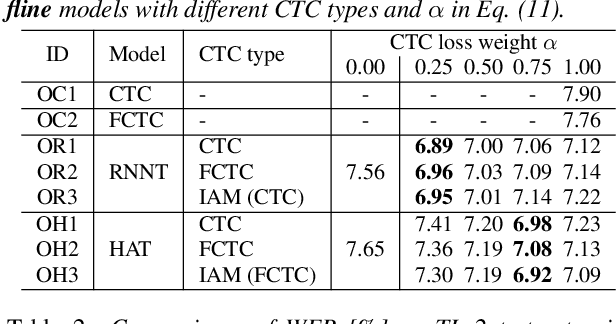
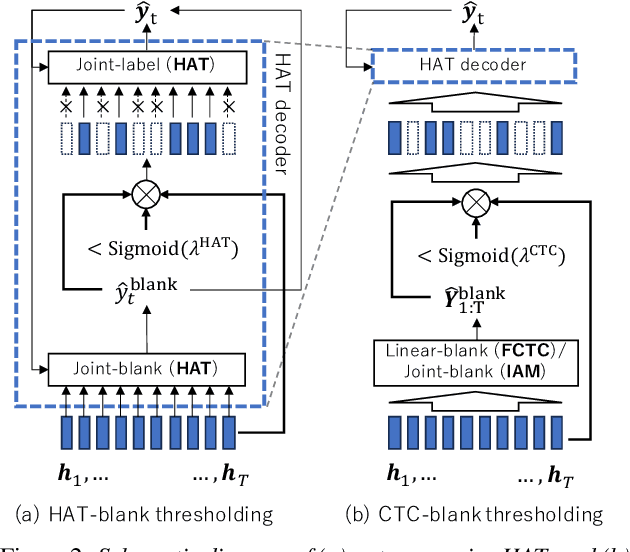
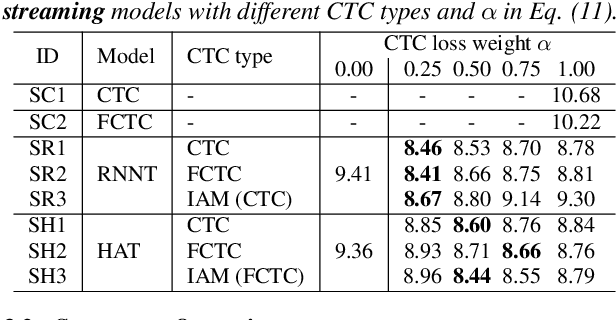
A hybrid autoregressive transducer (HAT) is a variant of neural transducer that models blank and non-blank posterior distributions separately. In this paper, we propose a novel internal acoustic model (IAM) training strategy to enhance HAT-based speech recognition. IAM consists of encoder and joint networks, which are fully shared and jointly trained with HAT. This joint training not only enhances the HAT training efficiency but also encourages IAM and HAT to emit blanks synchronously which skips the more expensive non-blank computation, resulting in more effective blank thresholding for faster decoding. Experiments demonstrate that the relative error reductions of the HAT with IAM compared to the vanilla HAT are statistically significant. Moreover, we introduce dual blank thresholding, which combines both HAT- and IAM-blank thresholding and a compatible decoding algorithm. This results in a 42-75% decoding speed-up with no major performance degradation.
Factor-Conditioned Speaking-Style Captioning
Jun 27, 2024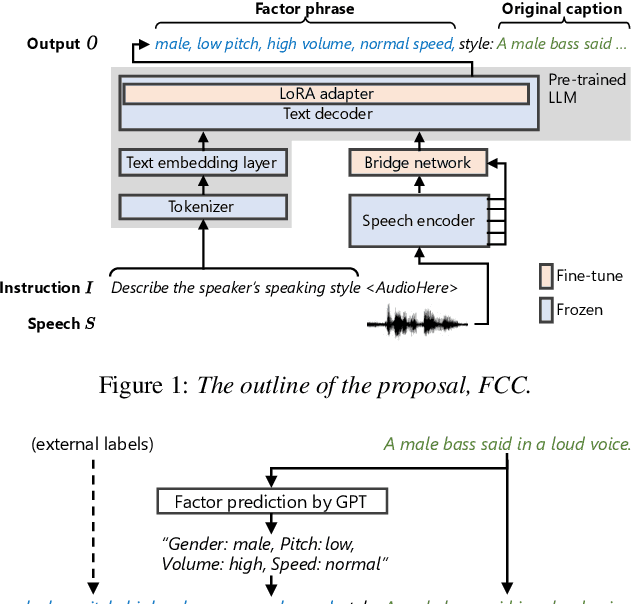



This paper presents a novel speaking-style captioning method that generates diverse descriptions while accurately predicting speaking-style information. Conventional learning criteria directly use original captions that contain not only speaking-style factor terms but also syntax words, which disturbs learning speaking-style information. To solve this problem, we introduce factor-conditioned captioning (FCC), which first outputs a phrase representing speaking-style factors (e.g., gender, pitch, etc.), and then generates a caption to ensure the model explicitly learns speaking-style factors. We also propose greedy-then-sampling (GtS) decoding, which first predicts speaking-style factors deterministically to guarantee semantic accuracy, and then generates a caption based on factor-conditioned sampling to ensure diversity. Experiments show that FCC outperforms the original caption-based training, and with GtS, it generates more diverse captions while keeping style prediction performance.
Adversarial Finetuning with Latent Representation Constraint to Mitigate Accuracy-Robustness Tradeoff
Aug 31, 2023



This paper addresses the tradeoff between standard accuracy on clean examples and robustness against adversarial examples in deep neural networks (DNNs). Although adversarial training (AT) improves robustness, it degrades the standard accuracy, thus yielding the tradeoff. To mitigate this tradeoff, we propose a novel AT method called ARREST, which comprises three components: (i) adversarial finetuning (AFT), (ii) representation-guided knowledge distillation (RGKD), and (iii) noisy replay (NR). AFT trains a DNN on adversarial examples by initializing its parameters with a DNN that is standardly pretrained on clean examples. RGKD and NR respectively entail a regularization term and an algorithm to preserve latent representations of clean examples during AFT. RGKD penalizes the distance between the representations of the standardly pretrained and AFT DNNs. NR switches input adversarial examples to nonadversarial ones when the representation changes significantly during AFT. By combining these components, ARREST achieves both high standard accuracy and robustness. Experimental results demonstrate that ARREST mitigates the tradeoff more effectively than previous AT-based methods do.