 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Scheduled Sampling for Neural Transducer-based ASR
Paper and Code
May 25, 2023
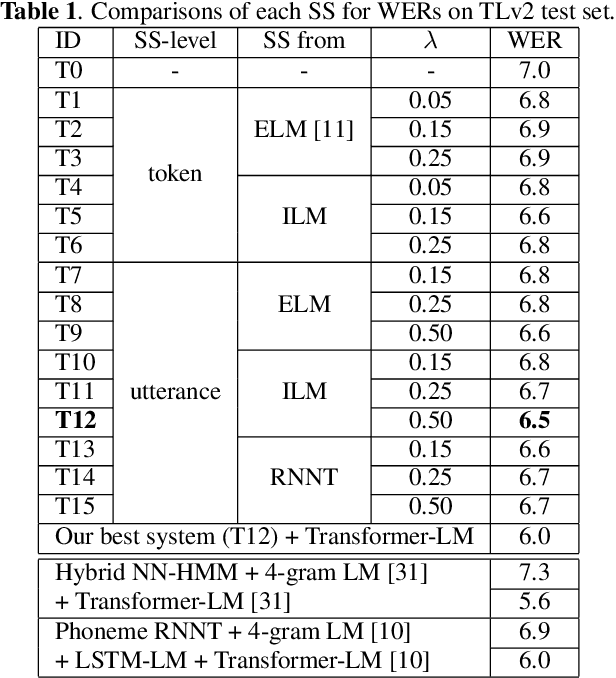
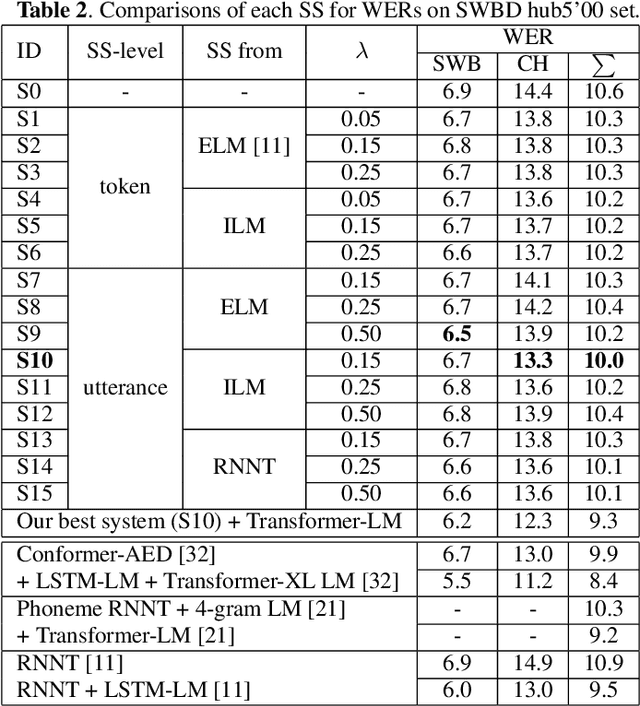
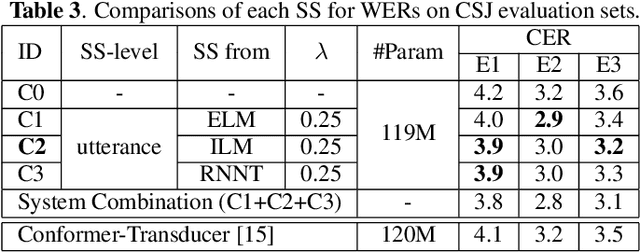
The recurrent neural network-transducer (RNNT) is a promising approach for automatic speech recognition (ASR) with the introduction of a prediction network that autoregressively considers linguistic aspects. To train the autoregressive part, the ground-truth tokens are used as substitutions for the previous output token, which leads to insufficient robustness to incorrect past tokens; a recognition error in the decoding leads to further errors. Scheduled sampling (SS) is a technique to train autoregressive model robustly to past errors by randomly replacing some ground-truth tokens with actual outputs generated from a model. SS mitigates the gaps between training and decoding steps, known as exposure bias, and it is often used for attentional encoder-decoder training. However SS has not been fully examined for RNNT because of the difficulty in applying SS to RNNT due to the complicated RNNT output form. In this paper we propose SS approaches suited for RNNT. Our SS approaches sample the tokens generated from the distiribution of RNNT itself, i.e. internal language model or RNNT outputs. Experiments in three datasets confirm that RNNT trained with our SS approach achieves the best ASR performance. In particular, on a Japanese ASR task, our best system outperforms the previous state-of-the-art alternative.